数据结构
第一章
数据结构:
- 定义:计算机存储,组织数据的方式。
- 关键词:
- 数据:如列表
- 存储
- 组织:怎删改查
- 例子:就比如手机上的一个通讯录,它就有很多数据,并且可以存储和组织数据。
其中组织为增、删、改、查。
- 增:我喜欢一个靓女,然后我加了她的电话号码。
- 删:我觉得我的三号女朋友不够专一,所以我就把她甩了,并且把她删了。
- 改:我的二号女朋友叫李白,然后我把她的备注改为“宝宝”。
- 查:我要从众多女朋友当中查找某一个女朋友的信息
总结:数据结构就是与数据有关,就是研究数据的储存和组织。
二维数组的CRUD
- 静态数组
- 动态数组
内存的概念:打个比方,内存就像一张巨大的网,但是这张网是有限制的,在这张“网”当中,储存着计算机的数据。(如下图所示)
例子:int类型的存储方式
int类型在C语言中占4个字节,而它在内存中也占4个格子 (8bit = 1 Byte)
一个字节能储存2^8
第二章 Arrays(数组)
数组是一个固定长度的存储相同数据类型的数据结构,数组中的元素被存储在一段连续的内存空间中。它是最简单的数据结构之一,大多数现代编程语言都内置数组支持。
为何使用数组存储一堆变量
与单独为每一个元素声明一个变量名相比,我们可以使用数组的索引值访问数组中的每一个元素。
例如:我们需要实现一个系统来存储办公室所有员工的年龄,传统的存储方式如下:
我们为办公室的每一个员工创建一个变量。假设办公室由三个员工,只需声明三个变量:empl_age,emp2_age和emp3_age.
当我们新招募员工进来时,我们需要创建更多的变量来存储员工的年龄。维护这样的系统非常麻烦,每添加一个新的员工,我们就需要修改这个系统的代码。
要人工计算超过20个员工的平均年龄,逐一访问每一个变量让人头痛的。
数组数据结构的出现尝试解决这种问题。数组的特性之一就是,以一个名称保存多个相同数据类型的数据。
在这个例子中,我们可以声明一个名为employees_ages的整型数组来保存所有员工的年龄。
数组的第二个特性就是,数组中的每一个数据元素被存储在一段连续的内存空间中,我们可以以索引的方式访问数组的数据元素。
通过遍历数组的索引来访问每个员工的年龄,使得计算员工年龄的平均值变得更加容易;因为在遍历过程中,数组的名称是恒定的,只有索引在变化。
声明一个一维数组
在使用一个数组之前,我们需要声明这个数组。声明数组意味着我们需要指定以下内容:
- 数据类型 这个数组将要存储怎样一种类型的数据(不同类型占据的内存空间是不同的.如:字符、整型、浮点型等一些数据类型。
- 名称 用于标识这个数组并与之交互的变量名
- 数量 数组的数量,它指定这个数组最多能存储的数据元素的数量
声明数组的语法
C语言中声明数组的语法如下:
type name[size]创建一个存储100个学生成绩的数组
int marks[100]为数组分配值的两种方式:
初始化时分配值
声明数组时为数组分配值。如果一些值没有明确定义,会被设置为0:
int marks[10]={5,10,20,30,40,60};初始化后分配值
默认情况下,只要由足够的内存,创建的数组会被随机分配一个位置,我们无法获知这个内存位置包含哪些信息。
如果在创建数组时,没有初始化数组元素。这时,我们就访问数组元素的话,会得到一个垃圾值。因此,如果要对一个数组执行计算,我们建议清空数组值或者为其分配初始值。
int ages[10];
//未为数组分配初始值,访问数组元素
for (int o=0;i<10;i++>){
printf("\n arr[%d]=%d",i,ages[i]);
}数组的遍历
数组中的每一个元素都可以通过索引访问到。数组的索引通常从0开始,即数组中第一个元素的索引为0.数组的最后一个元素位于(n-1)个索引处。我们将其称之为基于0的索引。数组也可以是基于其它数的,我们将其称之为基于n的索引。
使用for循环简单的遍历数组中的所有索引,可以访问数组中的所有元素。
int id[10];
//使用循环为数组分配值
for (int i=0;i<10;i++>){
printf("\nEnter an id:");
scanf("%d",%id[i]);
}
//遍历数组中的元素
for( int i=0;i<10;i++){
printf("\n id[%d]=%d",i,id[i]);
}在对数组元素进行插入或者删除时,为了保持数组的顺序。需要处理数组中已经存在的其它数组元素。对于较大的数组,这项工作对性能的消耗是昂贵的。
插入元素到数组中
插入尾部
在数组还有足够的空间可供插入时,在数组的尾部插入一个元素是非常容易的。找到数组最后一个元素的索引,并将新插入元素的索引+1即可完成插入。
任意位置插入
通过将该位置后的所有元素的位置向后移动,可在该位置插入元素。
void insert_position(int arr[]){
int i=0,pos,num;
printf("输入要插入的元素值:");
scanf("%d",&num);
printf ("输入要插入元素的索引位置");
scanf("%d",&pos);
for(i=n-1;i>=pos;i--){
arr[i+1]=arr[i];
}
arr[pos]=num;
n=n+1;//增加已使用索引的总数
}从数组中删除元素
删除尾部元素
只要数组不为空,删除数组中的元素是很容易的。找到最后一个元素的索引,然后删除该元素即可。
删除任意位置元素
可以在任意索引处删除元素,方法是删除该位置的元素,然后将该位置之后的所有元素向前移动以填充删除的位置。
void delete_position(int arr[]){
int i,pos;
printf("输入要删除元素的索引位置");
scanf("%d",&pos);
for (i=pos;i<n-1;i++>){
arr[i]=arr[i+1];
}
n=n-1;增加已使用索引的总数
}多维数组
数组可能具有多个维度来表示数据,我们将其称之为多维数组,可以使用多个索引来访问多维数组中的元素。
二维数组
二维数组可以视为数组中的数组。它可以使用行和列的表格来展示。可以使用与行和列对应的2个索引来访问表中的每个元素。
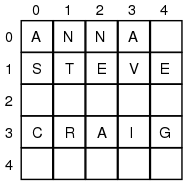
使用2个参数声明一个二维数组:
type name[max_size_x][max_size_y]max_size_x和max_size_y分别代表每个维度可存储数据的最大数据量
三维数组
类似的,可将三维数组视为一个立方体,可以使用与三维坐标相对应的3个索引来访问数组中的元素。
例如:魔方的每个方块都可以由尺寸为3x3x3的三维数组表示
声明一个三维数组:
type name[max_size_x][max_size_y][max_size_z];max_size_x、max_size_y和max_size_z分别代表每个维度能存储数据数量的最大值。
数组的内存分配
由于数组是将其所有的数据元素存储在连续的内存空间中。在存储数组时,仅存储数组的基地址,即第一个元素的地址。数组其它元素的地址可以通过对基地址的偏移来计算。
一维数组的内存地址
使用以下公式计算数组元素的内存地址
A[i]=base_address(A)+size_of_element(i-lower_bound);lower_bound表示数组的最小索引,同样的,up_bound表示数组的最大索引。在C语言中,最小下标通常是0,因此可以省略。
二维数组的内存地址
二维数组的存储形式由两种表示方法,并且其对应元素的地址均可以通过公式计算出来。
按列存储
以这种形式存储,元素逐列存储。第一列的m个元素存储在前m个位置中,第二列的元素存储在接下来的m个位置中,一次类推。
Address(A[i][j])=base_address+width{number_of_rows(j-1)+(i-1)}按行存储
以这种形式,元素逐行存储,第一行的n个元素,存储在前n个位置中,第二行的元素存储在第二行的前n个位置中,以此类推。
Address(A[i][j])=base_address+width{number_of_cols(i-1)+(j-1)}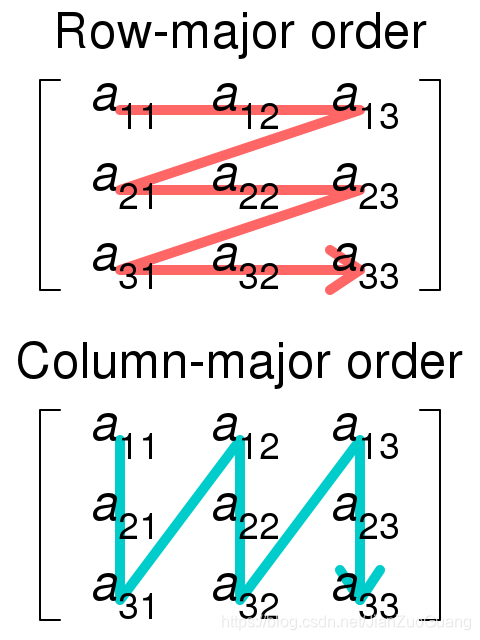
时间复杂度
访问
数组可以直接使用索引访问,因此,访问数组元素的时间复杂度为O(1)
查找
从数组中查找一个给定的值,需要遍历数组中的每一个元素,知道找到给定值为止。假设查找的形式为线性查找(数组最基本的查找形式),则查找的时间复杂度为O(n).
也存在一些其它的查找算法,比如,二分搜索,可在O(log n)的时间复杂度内搜索,但前提是当前数组为有序数组。
插入
在数组的两个元素之间插入一个新的元素,需要将插入之后的所有位置的元素向后移动。这就意味着如果在数组的开头插入元素,需要将数组的所有元素向后移动,因此插入操作的时间复杂度为O(n)
删除
在数组的两个元素之间删除一个元素,需要将删除位置之后的所有位置的元素向前移动。这就意味着,如果删除数组的第一个元素,需要将数组的所有元素统一向前移动,因此删除操作的时间复杂度为O(n)
空间要求
数组仅占据用于存储指定数据类型的元素的空间,这就意味着,存储n个元素所要求的空间复杂度为O(n)
数组的优点
相比其它类型的数据结构,数组有以下优点:
- 数组允许随机访问数组元素,每个存储在数组中的元素可以通过直接访问其索引来使用
- 数组对存储友好。这意味着在某些情况下,由于数组的线性存储方式,代码的执行顺序会大大提高
数组的缺点
- 声明数组时,需要指定数组的长度。初始声明数组的长度过长或过短,在移动数组元素时都会有导致效率变低
- 插入和删除元素之后保持数组的连续性代价是昂贵的,因为有可能需要重新排列所有数组元素。
第四章 复杂度分析
Linear List包括Array和linked list
第一节:Array总论
0)Linear List一般在国内被翻译为“线性表”,它包含两部分:一是Array,二是Linked List。但是在国外却没有这个概念,在国外只有Array与LInked List的概念。
1)数组必须是连续的,也就是“back to back” 最大的特点
2)数组元素地址的查找,如下图所示:
比如我查第一个元素,那么计算机就会从第一个格子开始查找,直到找到“00000001”中的1为止。那如果我还要查找第二个元素,这个时候,计算机就不会挨个去查找了,而是在第一个元素的地址的基础上再加上4个字节,这样就可以找到第二个元素的地址了,并且可以省很多时间,以此类推,第3个,第4个,甚至是第N个元素地址的查找也都是这样的。
第二节:静态数组 复杂度分析
0)数组在按照下标(index)查询时,其时间复杂度为O(1)
1)数组元素的更改:有一个数组array[ ]={1,2,3,4},如果我把array[1]改成6,那么时间复杂度也为 O(1)
2)数组元素的增加:由于数组具有“back to back”的特性,所以数组不可能在某一个地方插入一个元素
比如在这幅图中,黑色部分存储了一个数组的数据,那么就不能在它前面或后面的格子再插入任何数据,因为不确定这些格子是否为空。
那么这种情况下该怎么办才能增加数组的元素呢?下面来举个例子:
微软和谷歌的程序员都生病了,他们都需要住院,而且谷歌的程序员非要跟微软的程序员住在一起,因为他们可以进行技术交流。但是这个时候院长却为难了,因为微软程序员所在的楼层已经住满了,容不下谷歌的程序员。那么院长就想出来了一个办法:让谷歌程序员去其他空楼层住院,并且让微软程序员全部搬进谷歌程序员所在的楼层,这样就实现了谷歌程序员的愿望。
现在再抽象到理论层面:数组在增加元素时,会进行一个“先复制再转移”的操作,即先在内存当中复制一份原来的数组,然后再对这个副本进行插入处理。时间复杂度为O(N)
3)数组元素的删除:复杂度O(1)或者O(N)
比如有一个数组为array[ ]=
但我想把3给它删了,那么直接把3所占的那4个格子给它删了就行(如下图所示)
但是这种情况仅限于“back to back”的情况,即从数组的尾部进行删除时,它才能如此之快,其时间复杂度为O(1)。
然而,非“back to back”情况就没有那么容易了。如下图所示:
还是有一个数组array[ ]={0,1,2},但这一次我要把0给删了,那么这个时候就并不仅仅是删除这么简单了,因为把0删除了之后,这个数组就没有了首元素,而一个数组又必须要有首元素(遵循“back to back”的原则)所以要将0之后的每一个元素都向前移动4个字节,即1向前移动一位,2向前移动一位,以此类推。也就是有多少个数据就要移动多少次,那么它的时间复杂度就是O(N)。并且从数组的中间删除的空间复杂度也是O(N)。
4)标记-清除
还是有一个数组array[]={1,2,3,4.......后面还有很多数据},还是从头部删除,但是这次并不止删除一个元素,我要把“1,2,3”这三个元素都删了,如果直接进行删除的话,就要执行3次O(N)的操作,这样就会很麻烦。但是我可以把这3个元素都进行标记,然后统一进行删除,那么这样就相当于只执行了一次O(N)的操作。当要删除的元素为N个时,如果不进行标记,那么其时间复杂度就为O(),但如果进行标记,那它的时间复杂度就为O(N)。进行这样的操作就可以在元素过多时大大节省时间。
这也是JVM原理之一,mark and swing垃圾回收机制
第三节:动态数组
0)数组扩容:动态数组在增加元素时具有扩容功能,就比如一个数组array[]={1,2,3},这个数组的容量太小了,我要对它进行扩容,那么此时这个数组的容量就会增加一倍,即{1, 2, 3, 4, 5, 6}。并且在扩容时的第一个元素其时间复杂度为O(N),而后元素的复杂度为O(1),
如下图所示:
即扩容时复杂度为O(N),不扩容时复杂度为O(1),这就是大名鼎鼎的“平摊分析”。
举个例子:有一个人犯了罪,但是他出狱后改过自新,从新做人,为社会做了很多好事,这就叫“将功补过”。
那么抽象到理论层面也是一样的,数组在扩容时为O(N),很浪费时间,但是它就会在后面跟一系列O(1)来减少时间复杂度。
1)复杂度震荡:还是一个数组,我在需要时就要对其扩容,但是在不需要时就要对其减容,那么该数组就会反复拉扯,如下图所示:
该数组会在2处进行来回摆动,那么这个时候就出现了一个标准:减容时只减四分之一,这样就不会出错。
第五章 链表
第一节:单向链表
0)单向链表的含义:单向链表就是在内存当中开辟两块连续的格子,一个格子储存值,另一个格子存储地址,然后再用指针指向下一个区域。如下图所示:

打个比方:就像游戏《神秘海域》一样,他会在一个藏宝地点放着一个箱子,这个箱子里放着下一个地点的线索,然后以此类推,知道找到宝藏为止。单向链表就是这个原理。
1)节点的查找:查找一个链表的头节点就是一瞬间的事,它的时间复杂度为O(1),但是查找尾节点就没有这么容易了,它就会把链表遍历一次,那么时间复杂度就为O(N)
2)头节点的插入:有一个链表“头Node=>1=>2=>3=>4”,它的头节点是1,那么我想在这个链表当中插入一个头节点“0”,那么计算机就要先找到这个链表的原先头节点“1”,然后把头“Node=>1”的指针指向0,并且将“0”插入,再设置一个指针指向1(0=>1)就行了。这样就行了两次O(1)的操作,那么它的时间复杂度就是O(1)
3)尾节点的插入:还是上面那个链表,但是这次我要插入一个尾节点5,那么计算机就要把这个链表遍历一遍,再在尾部进行插入,那么时间复杂度就为O(N)。从中间插入也是一样的
中间插入是O(N)
4)备胎:如下图所示

一般来说,单向链表会在尾节点处留一个指针指向NULL,当需要时才会启用,就跟备胎一样。
我们平时玩的贪吃蛇就是这个原理,它永远会在蛇尾留一个空指针,一旦玩家吃到了食物,那么这个指针就会指向下一个节点。
第二节:双向链表

0)如图,双向链表有两个节点,一个为前节点,另一个为后节点。在双向链表当中,一个值的后节点指向下一个值的前节点,而一个值的前节点则会指向上一个值的后节点。
1)节点的访问:访问头节点和尾节点的复杂度都为O(1),但访问中间的元素的复杂度为O(N);删除一个元素的复杂度为O(1),但是查找某一个元素的复杂度为O(N)。
2)循环链表:

如图,循环链表的值、头节点、尾节点会依次排序。
第三节:现实举例以及题外话
0)游览器左上角的进退键就是一个双向链表,如下图所示:

1)网易云音乐的进退键也是一个双向链表,如下图所示:

第二章 Hash
第一节:hash的含义
0)先来打个比方:特工在执行潜伏任务时不可能以特工的身份大摇大摆地进入潜伏地点,而是要进行一定的伪装,这样才能顺利地进入潜伏地点。
那么再抽象到理论层面,对于一个明文,这个明文当中储存着一些机密信息,我要通过某种方式将其加密成某种密文,那么这种方式就称为“Hash Function(哈希函数)”。
:
%E6%95%B0%E6%8D%AE%E7%BB%93%E6%9E%84/image.png
1)Hash碰撞:不同的明文在通过某一种Hash Function加密后会得到相同的密文。
:
%E6%95%B0%E6%8D%AE%E7%BB%93%E6%9E%84/image%201.png
2)单向散列函数:举个例子,有一个明文,我只能用某一种Hash Function将其推导出密文,而不能用这种方式将密文推导成明文,那么这种方式就叫“单向散列函数”。(其实就是一种验证函数)
现在再来谈谈它在生活当中的应用:平时我们在网上下载东西时都会有一个“sha验证”,这个验证方式就是利用了单向散列函数的原理。sha验证可以计算出官网安装包的散列值与用户安装包的散列值,然后进行比对,如果用户的散列值与官网上的一样,那么下载的就是正版,反之则为盗版。
再比如就是C#和Java当中的字典,其键值对就是通过这种方式进行对应的。
第二节:Hash Table与Hash Map的原理分析
hash在内存当中的运行原理:明文在通过hash function进行加密时,会得到密文以及它在内存当中的地址,然后将密文储存到地址中。再次通过该方式验证时就会直接查询其地址,然后再通过地址得到密文。(其实就相当于数组当中的下标查找)
在一些高级语言中,为了防止键值对发生hash碰撞,它就会将值储存到链表当中,其原理如下图:
:
%E6%95%B0%E6%8D%AE%E7%BB%93%E6%9E%84/image%202.png
发生碰撞立刻生成链表
键对应的值储存在链表当中,然后链表当中的值后面又会跟着一个节点,从这个节点发出一个指针指向键。
最坏情况基于发生多次哈希碰撞
:
%E6%95%B0%E6%8D%AE%E7%BB%93%E6%9E%84/image%203.png
第七章 堆栈
栈
栈是一种线性存储数据的数据结构,以后进先出的顺序存储数据。在某些需要对数据按照一定顺序使用的情况下,栈是非常有用的。
:
%E6%95%B0%E6%8D%AE%E7%BB%93%E6%9E%84/image%204.png
可以将栈视作为放在桌子上的一堆盘子,在任何时刻,用户都只能访问最顶部的盘子。用户取盘子或者是放盘子,都只能从盘子的顶部进行操作。

栈的一些运算形式
栈的运算形式主要有两个:入栈(Push)和出栈(Pop)
入栈操作
向栈中添加元素。对应元素被添加到栈顶。
Peek操作
Peek操作用于返回栈中的第一个元素,用于跟踪栈当前的运算位置。不会对栈元素实行删除。
栈上溢和下溢的条件
根据栈的实现方式不同,栈的内存空间可能有限。在进行入栈和出栈操作时,我们必须实现关于栈空间的条件检测,确保不超出当前栈所支持的最大操作范围。
下溢条件检查栈操作弹出元素之前栈中中是否存在元素,如果栈为空,则不能继续弹出元素:
if (top==-1){
//下溢条件
}上溢条件检查栈是否为满栈(或者是否还有内存空间)。
if (top==sizeOfStack){
//上溢条件
}栈顶指针
为了能够方便的从栈中添加和删除数据。需要一个特殊的指针来跟踪插入和删除之后,栈中最后一个元素的位置。
栈创建
栈的创建主要有两种方式:使用数组或者使用链表。我们首先以数组创建一个简单的栈。
- 创建一个一维数组,并固定数组的大小(int stack[SIZE],SIZE使用预处理器定义#define SIZE 10
- 定义一个int类型变量作为top,并初始化为-1(int top=-1)
#define SIZE 10
int stack[SIZE];
int top=-1;属性
- 遵循后进先出,元素的插入删除均在栈顶进行
- top指针始终指向栈顶元素

入栈
入栈过程
- 检查栈是否为空(top==SIZE-1)
- 如果为空,异常并退出
- 如果不为空,增加top值(top++),并设置stack[top]=value
void push(int value){
if (top==SIZE-1){
printf("溢出,栈满");
}else{
top++;
stack[top]=value;
printf("插入成功);
}
}出栈
出栈过程
- 检查栈是否为空(top==-1)
- 如果为空,异常并退出
- 如果不为空,删除stack[top]并使top减少(top–)
void pop(){
if (top==-1){
printf("栈为空);
}else{
printf("删除成功:%d",stack[pop]);
top--;
}
}访问栈顶
访问过程
- 检查栈是否为空(top==-1)
- 如果栈为空,异常并退出
- 如果栈不为空,返回stack[top]
void peek(){
if (top==-1){
printf("栈为空");
break;
}else{
printf("%d",stack[top]);
}
}栈运算时间复杂度
| Access | Search | Insertion | Deletion | Space |
|---|---|---|---|---|
| O(n) | O(n) | O(1) | O(1) | O(n) |
访问栈元素
要想在栈中查找某个指定的元素,需要连续移除栈顶部的元素直到找打目标元素为止。所以栈的访问时间复杂度为O(n)
查找
查找类似于访问栈元素,需要不断的将元素弹出栈,直到找到目标元素,因此其时间复杂度为O(n)
插入
由于从栈中插入元素仅能从栈顶插入,不需要对栈元素进行迭代,因此栈中插入元素的时间复杂度为O(1)
删除
删除类似于插入,栈操作仅限于栈顶,其时间复杂度为O(1)
空间复杂度
栈仅存储指定数据类的元素的空间,这意味着,要存储n个元素,其空间复杂度为O(n)
使用场景
- 编辑器的撤销功能 我们编辑文档时,每执行一个操作都会被压如栈中,当我们想要撤回操作时,执行出栈还原操作
- 表达式解析 通过使用堆栈有助于使用后缀和前缀表示法解析表达式
队列Queue
队列是一种线性的数据存储结构,按照数据先进先出的形式存储数据。
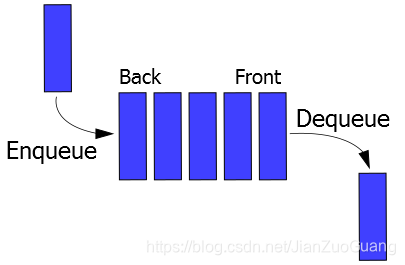
队列可以抽象为我们排队买东西或者购票。一个人可以从队列的尾部加入到队列中,也可以从队列的开头离开队列。第一个新进入队列的人,最先离开。
队列的一些运算
队列的运算主要包括两个,其中一个为入队,另外一个为出队。
入队
通过入队的形式,将一个元素添加到队列中,新加入进来的元素总是位于队列的末尾。
出队
通过出队,可以将一个元素从当前队列中移除,移除队列操作总是在队列的头部进行。
队列的头、尾指针
为了能够有效的从队列中添加和移除数据,使用了两个特殊的指针来跟踪队列的第一个和最后一个元素。这俩个指针根据入队和出队的情况,不断的变化,并检查上溢和下溢出条件。
上溢和下溢条件检查
更具队列实现方式的不同,队列的使用可能会有内存空间限制,因此,我们必须实施条件检查,以确保我们在入队和出队时不会超出队列的最大支持范围。
从队列中弹出元素前,需要检查队列是否为空,否则无法出队。
if (front==rear){
//头指针和尾指针指向相同,表示队列为空
}将元素入队时,需要检查队列是否有足够的内存空间
if (rear==SIZE-1){
//尾指针指向达到最大存储限制
}队列的平均时间复杂度
| Access | Search | Insertion | Deletion | Space |
|---|---|---|---|---|
| O(n) | O(n) | O(1) | O(1) | O(n) |
队列的类型
队列可以根据一些使用类型存在一些类型的变化。
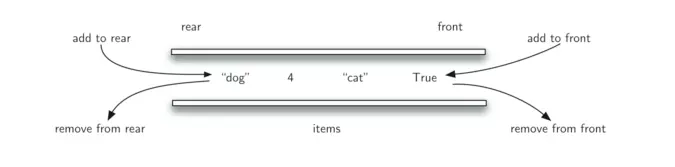
双端队列
在标准的队列中,从队列中插入元素只能在队尾进行,而从队列中移除元素,只能在队头进行。双端队列允许从队列的两端进行插入和移除。
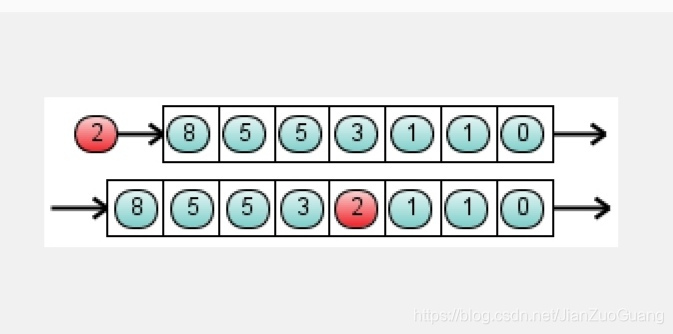
优先队列 --- 普通的队列时一种先进先出的数据结构,元素在队尾追加,从队头删除。而在优先队列中,具有最高优先级的元素最先被删除。队列中的元素均被赋予优先级。
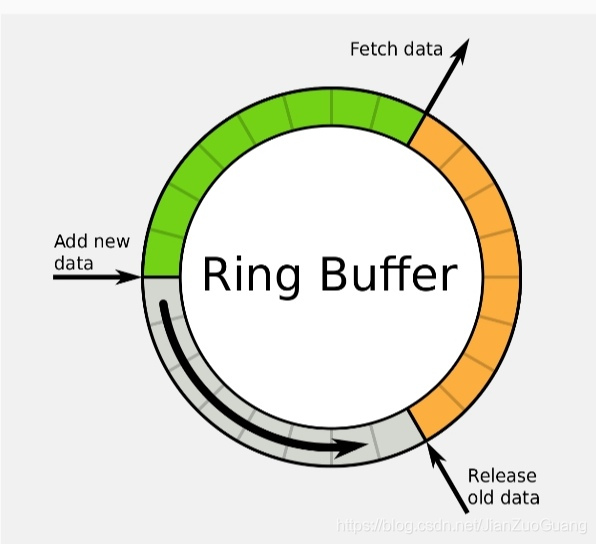
环形队列 --- 环形队列只用单个固定大小的缓冲区,类似于一个首尾相连的圆弧。对于具有固定大小的队列而言,使用环形队列不涉及移位,整个队列都可以用于存储数据元素。
树
树作为一种数据结构,其结构类似于生活中的树。以根节点和子级作为树节点,通过一组链表节点表示。树也可以这样定义:树是由根结点和若干颗子树构成的。树是由一个集合以及在该集合上定义的一种关系构成的。集合中的元素称为树的结点,所定义的关系称为父子关系。父子关系在树的结点之间建立了一个层次结构。在这种层次结构中有一个结点具有特殊的地位,这个结点称为该树的根结点,或称为树根。使用遍历,可以访问树中的每一个节点。

和数组,栈和队列不一样,树并不是以线性存储的数据结构。
基本术语
在学习树数据结构之前,我们需要了解一些与树相关的术语:
Root(根):树的第一个节点被称之为根节点,每棵树必须有一个根节点
Parent Node(父节点):任何节点的前置节点都称之为父节点,也就是说,从其到任何其它节点都有分支的节点称之为父节点
Child Node(子节点):任何节点的后代节点称之为子节点,任何父节点可以具有任意数量的子节点,除Root节点外的所有节点都是子节点。
兄弟节点:同属一个父级的节点称之为兄弟节点。
叶节点leaf nodes:在树数据结构中,没有子节点的节点称之为叶节点,它们也被称之为外部节点或者终端节点。
内部节点:至少有一个子节点的节点被称之为内部节点。
外部节点:没有子节点的节点称之为外部节点。
Degree(度):一个节点的子节点的总数称为该节点的度。
层级(Level):在树中,从上到下的每一个步骤都被称之为层级。
高度(Height):从叶节点到某个特定节点的最长路径长。
深度(Depth):从根节点到指定节点边缘总数。
路径(Path):从根节点到指定节点的边数。
树的类型
根据属性的不同,树可以分为以下几种:
- 普通树
- 二叉树
- 二叉搜索树
- 多叉树 4.AVL树(自平衡二叉查找树)
普通树
普通树中的每一个节点可以有一个或者多个子节点。其它类型的树是普通树的特例。在数学上,将树定义为有限的非空元素集,其中一个元素成为根元素,其余元素在划分树时称为子树的根。
二叉树
在普通树中,每个节点可以偶任意数量的子节点。二叉树作为普通树的一个特例,其中每个节点最多可以有两个子节点,一个被称为左节点,另一个被称为右节点。

二叉搜索树
二叉搜索树是一种额外满足二分搜索特性的二叉树。该树用于在树中查找元素时减少比较的次数,例如常规的二分搜索。
在二叉搜索树中,每个节点的键必须大于或者等于其左子树中的任何节点的键,且小于或者等于其右子树节点的任何节点的键。

多叉树
多叉树中的每个节点可有具有多个子节点。通常将其称之为n叉树,其中每个节点有M个子节点和m-1个键值,每个节点中的键值按升序排列,前i个子节点中的键值都小于第i个键值,后m-1个子节点中的键值都大于第i个键值。

多叉树常见的两种变体
- B-Trees B树是一种树状数据结构,它能够存储数据,对其进行排序并允许以O(log n)的时间复杂度进行查找、顺序读取、插入、删除的数据结构。B树,概括来说是一个节点可以拥有多于两个子节点的二叉排序树,与自平衡二叉查找树不同,B树为系统最优化大块数据的读和写操作,普遍运用在数据库和文件系统。B树中所有节点的最大孩子节点数被称之为B树的阶,通常用m来表示。
- B+ Trees 一个B+树可以看作是一棵B树,其中每个节点只包含键(而不是键值对),并且将所有记录存储在树的叶级。
AVL树(自平衡二叉查找树)
AVL树也称之为自平衡二叉查找树.如果树中每个节点的左子树和右子树的高度差为-1,0或+1,将其称之为平衡二叉树。

树的常见使用场景
- 文件系统结构 操作系统中文件系统的目录和子目录可以通过树结构来表示
- 各个文件夹逐个展开形成树状结构
- DOM结构 HTML中的页面使用DOM结构呈现,该结构包含所有网页中使用到的标签,DOM结构也是一个类似于树的结构
- 路由器算法 使用树结构构造一个跨越网络的位置树,以确保数据包必须遵循路由规则才能有效的到达目的地。
树的遍历
想要访问二叉树中的节点需要遍历整棵树。通常有三种遍历树的形式,每种遍历形式产生不同顺序的元素。
中序遍历(Left-Root-Right)
中序遍历首先访问左子节点,然后访问根节点,最后再访问右子节点。递归重复此操作,直到遍历完树中的所有元素。
中序遍历算法步骤
- 遍历左子树,中序递归调用(左子树)
- 访问根结点
- 遍历右子树,中序递归调用(右子树)

中序遍历代码
void inorder(struct Node* node){
if (node==NULL)return;
inorder(node->left);
cout<<node-data<<endl;
inorder(node->right);
}前序遍历(Root-Left-Right)
在前序遍历中,首先访问根节点,然后访问左节点,最后访问右节点。重复执行递归,直到所有节点都被遍历。
前序遍历算法步骤
- 访问根节点
- 遍历左子树,前序递归调用(左子树)
- 遍历右子树,前序递归调用(右子树)
前序遍历代码
void preorder(struct Node* node){
if (node==NULL)return;
cout<<node->data<<endl;
preorder(node->left);
preorder(node->right);
}后序遍历(Left-Right-Root)
后序遍历首先访问左子节点,然后访问右子节点,最后访问根节点。递归重复此操作,直到树中的每个元素都被访问。
后序遍历算法步骤
- 遍历左子树,后序递归调用(左子树)
- 遍历右子树,后序递归调用(右子树)
- 访问根节点
后序遍历代码
void postorder(struct Node* node){
if (node==NULL)return;
postorder(node->left);
postorder(node->right);
}算法时间复杂度
每棵树的遍历的时间复杂度均为O(n),遍历树所需时间随元素线性增加
AVL树
AVL树又称之为自平衡二叉搜索树。如果一棵二叉树,其左子树和右子树中的每个节点的高度为-1,0或者+1,则称此二叉树是平衡的。
为了保证最后两层的查不超过1
:
%E6%95%B0%E6%8D%AE%E7%BB%93%E6%9E%84/image%205.png
为什么平衡是重要的
可以看出,二叉搜索树的最坏时间复杂度类似于线性搜索算法,这是由于树的一侧比另外一侧具有更多的元素。
在实际的数据存储中,我们无法预测树的结构,因此二叉搜索树的查找性能可能会比预期的差。为了保证二叉搜索树的性能不变,我们需要使该树保持平衡,确保树的一侧不比另外一侧有更多的子级,这样可以确保执行二叉查找时,两面都具有相同的元素数量。
平衡因子计算公式如下:
BlanceFactor=height(left-subtree)-height(right-subtree)如果发现其不同节点的高度差大于1,需要使用四种旋转技术平衡树。这些技术通常用于插入和删除树中节点时。
AVL 旋转
为了保持树平衡,需要使用以下几种方式保持平衡
左旋
在这种情况下,通过向左旋转一次来恢复平衡属性
右旋
在这种情况下,通过向右旋转一次来恢复平衡属性
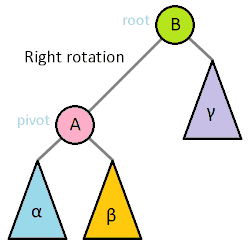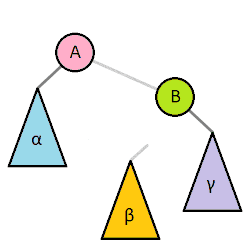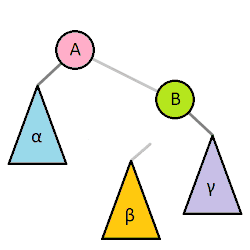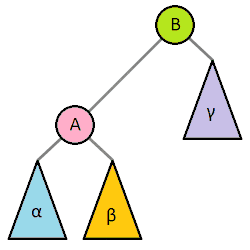
左-右旋转
以下这种情况,通过左旋转然后再右旋转来恢复平衡属性
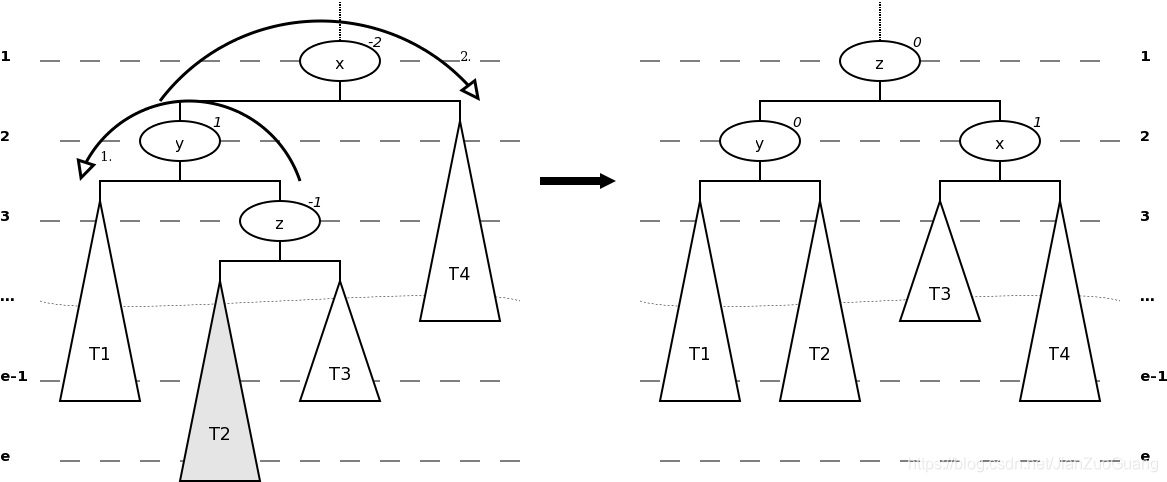
右-做旋转
以下这种情况,通右旋转然后再左旋转来恢复平衡属性
:
%E6%95%B0%E6%8D%AE%E7%BB%93%E6%9E%84/image%206.png