Django 基础
Web开发简介 前端开发人员通常需要开发如下文件:
- html 文件:HTML指的是超文本标记语言 (Hyper Text Markup Language),负责搭建网页结构。
- CSS文件:CSS指级联样式表(Cascading Style Sheet),负责界面的显示样式和效果。比如字体、大小、前景色、背景色、间距、一些动画效果等等。
- javascript 脚本:负责交互,可执行一些功能降低服务器的压力。
- 资源文件:显示在界面上的 图片、视频等。
当浏览网站时,浏览器先通过http协议向服务器请求这些文档,然后解析其内容,生成对应的界面。 由于 浏览器 内嵌的js 解释器性能飞速提升,一部分业务逻辑被放在前端来分担后端的负荷, 前端的重要性日益增加。 后端要开发服务进程,处理前端http请求,返回相应的数据。通常包括数据的增删改查。如果设计用户量非常大,需要响应 百万级以上 的客户访问, 就需要精心的设计架构,做好多服务分布式、集群式的处理大量的用户请求。
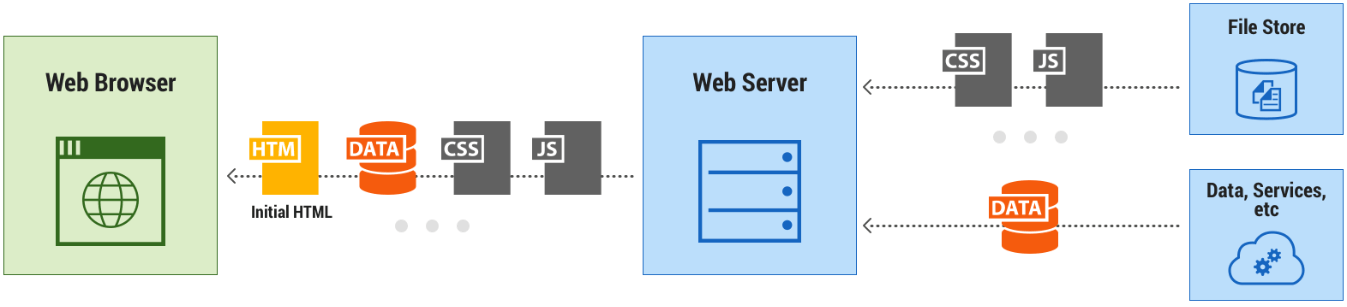
- 静态文件服务方案:即前端开发出来的HTML、css、js文件存储在什么地方,使用什么服务提供给前端浏览器访问。 通常一个比较大型的网站, 静态文件往往会使用单独的服务器专门提供服务,甚至一部分特别消耗带宽的数据(比如视频、图片)会使用第三方的云服务厂商(比如阿里云的cdn和oss服务)。
- API 接口设计, 就是 定义 前端和后端交互接口规范。
- 数据库存储方案
- 为了提高性能, 需要决定使用怎样的 缓存服务 和 异步任务服务
2. HTTP ### 2.1 HTTP请求消息
POST /api/medicine HTTP/1.1
Host: www.baiyueheiyu.com
User-Agent: Mozilla/6.0 (compatible; MSIE5.01; Windows NT)
Content-Type: application/x-www-form-urlencode
Content-Length: 51
Accept-Language: zh-cn
Accept-Encoding: gzip, deflate
name=qingmeisu&sn=099877883837&desc=qingmeisuyaopin- 请求行 request line:包含 请求的方法、操作资源的地址、 协议的版本
- GET:从服务器 获取 资源信息。
- POST:添加 资源信息 到 服务器。
- PUT:请求服务器 更新 资源信息 。
- DELETE:请求服务器 删除 资源信息 。
- 请求头 request headers:通常请求头有多个,一个请求头占据一行。单个请求头的格式是: 名字: 值。HTTP协议规定了一些标准的请求头,也可以在HTTP消息中 添加自己定义的请求头。
- 消息体 message body:POST、PUT等请求,添加、修改的数据信息存放在消息体中。如果 HTTP 请求有消息体,需要在 请求头和消息体 之间 插入一个空行。WEB API 请求消息体 通常是某种格式的文本,常见的有Json、Xml等。 ### 2.2 HTTP响应消息
HTTP/1.1 200 OK
Date: Thu, 19 Sep 2019 08:08:27 GMT
Server: WSGIServer/0.2 CPython/3.7.3
Content-Type: application/json
Content-Length: 37
X-Frame-Options: SAMEORIGIN
Vary: Cookie
{"ret": 0, "retlist": [], "total": 0}状态行 status line:包括协议版本、状态码、描述状态的短语。状态码表示了 服务端对客户端请求的处理结果 ,由3位数字表示,第一位数字代表 处理结果的大体类型。
- 2xx:通常表示请求消息没有问题,而且服务器也正确处理了
- 3xx:重定向响应,表示客户端请求的url地址已经改变了, 需要客户端重新发起请求到另外的一个url。
- 4xx:表示客户端请求有错误。
- 400 Bad Request 表示客户端请求不符合接口要求,比如格式完全错误;
- 401 Unauthorized 表示客户端需要先认证才能发送请求;
- 403 Forbidden 表示客户端没有权限要求服务器处理这样的请求, 比如普通用户请求删除别人账号等;
- 404 Not Found 表示客户端请求的url 不存在
- 5xx:表示服务端在处理请求中,发生了未知的错误。通常是服务端的代码设计问题,或者是服务端子系统出了故障(比如数据库服务宕机了)
响应头 response headers:作用 和 格式 与请求头类似
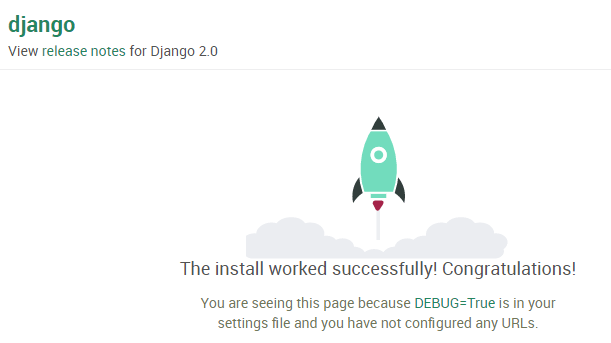
消息体 message body:和请求消息体一样,通常也是某种格式的文本。 ## 3. Django安装与App创建 通过python -m django –version查看系统是否安装Django。创建项目结构如下: 项目名 manage.py # 工具脚本,用作项目管理。使用它执行管理操作。 项目名/ # 该目录的名字不可随意改动 init.py settings.py # 项目的配置文件 urls.py # 声明前端发过来的各种http请求,分别由哪些函数处理 wsgi.py web 服务网关接口(Web Server Gateway Interface) 规范 ,wsgi。遵循wsgi规范的 web后端系统由wsgi web server 和 wsgi web application两个运行在python进程中的模块组成。 http 请求发送到 wsgi web server , wsgi web server 分配 线程或者进程或者 轻量级线程(协程),然后在 这些 线程、进程、或者协程里面,去调用执行 wsgi web application 的接口( 比如函数或者类方法)。wsgi web application 被调用后,负责 处理 业务逻辑。然后再把处理结果返回给 wsgi web server, wsgi web server再返回给前端。 django是 wsgi web application 的框架,它只有一个简单的单线程 wsgi web server供调试时使用。产品正式上线运行的时候,通常需要高效的 wsgi web server 产品,比如 gunicorn,uwsgi,cherrypy等结合Django 组成一个高效的后端服务。 wsgi.py 就是提供给wsgi web server调用的接口文件,里面的变量application对应对象实现了 wsgi入口,供wsgi web server调用 。 运行web 服务只需要在项目目录下执行命令python manage.py runserver 0.0.0.0:8000。0.0.0.0:8000 是指定 web服务绑定的 IP 地址和端口。0.0.0.0 表示绑定本机所有的IP地址, 就是可以通过任何一个本机的IP (包括 环回地址 127.0.0.1) 都可以访问我们的服务。8000 表示是服务启动在8000端口上。在浏览器地址栏输入 ‘127.0.0.1’ 看到如下界面表示Django服务搭建成功。
注意,如果启动web服务的命令行窗口关闭,web服务就会停止。 一个项目包含多个app。一个app 通常是一个相对独立的模块 ,实现相对独立的功能。在项目根目录执行命令python manage.py startapp sales将会创建一个名为sales的app,里面将包含如下自动生成的文件。
sales/ init.py admin.py apps.py migrations/ init.py models.py tests.py views.py
处理http 请求的代码的 Django启动时会自动加载settings配置文件中的installed_apps,按顺序一次加载apps对应的admin.py文件:
#此方法在admin 的__init__.py中 def autodiscover():
autodiscover_modules('admin', register_to=site)若果想要项目启动时自动执行某个python文件,只需在installed_apps中的某一配置APP的apps.py文件中定义方法,并调用autodiscover_modules:
from django.apps import AppConfig from django.utils.module_loading import autodiscover_modules class App01Config(AppConfig): name = 'app01' def ready(self): autodiscover_modules("aa") # 执行App01目录下的aaa.py4. HTTP请求的url路由
对于请求 /sales/orders/ , 返回一段字符串给浏览器。需要执行如下操作:
- 在views.py 里加入如下内容: from django.http import HttpResponse
def listorders(request): # 接收到/sales/orders/时调用的函数 return HttpResponse("下面是系统中所有的订单信息。。。")参数 request 是Django中的 HttpRequest 对象,包含了HTTP请求信息。
- 在根目录下的urls.py中的urlpatterns 列表变量中添加一条路由信息,告诉Django当前端发送过来的HTTP请求地址 是 /sales/orders/ , 就由 views.py 里面的函数 listorders 来处理。 from django.contrib import admin
from django.urls import path # 导入 listorders 函数 from sales.views import listorders urlpatterns = [ path('admin/', admin.site.urls), # 添加如下的路由记录 path('sales/orders/', listorders), # 注意:最后的一个斜杠不能省略 ]项目代码修改后, Django可以自动检测并重新加载,不需要重启 Django 服务。 当项目比较大的时候, 请求的url 会特别多。通常可以将不同的路由记录 按照功能 分拆到不同的 url路由子表 文件中。比如可以把 访问 的 url 凡是 以 sales 开头的都 由 sales app目录下的 子路由文件 urls.py 处理。这个文件需要我们手动创建,在此文件中输入如下内容:
from django.urls import pathfrom . import viewsurlpatterns = [ path('orders/', views.listorders),]然后还要修改主url路由文件,如下:
from django.contrib import admin# 导入一个include函数from django.urls import path, includefrom sales.views import listordersurlpatterns = [ path('admin/', admin.site.urls), path('sales/', include('sales.urls')),]5. 创建数据库和表
MySQL和PostgreSQL需要安装数据库服务系统和客户端。SqlLite没有独立的数据库服务进程,数据操作被做成库直接供应用程序调用。使用特定数据库需要在项目根目录下的settings.py文件中配置。 ### 5.1 创建数据库与ORM 执行命令python manage.py migrate即可创建数据库,其会自动在项目的根目录下生成配置文件中设定的对应数据库文件,且会自动生成一些预定的表。如auth_user是用户表,django_session是登录会话表。 Django 里数据库表的操作,包括 表的定义、表中数据的增删改查,都可以通过 Model 类型的对象进行。ORM(object relational mapping)屏蔽了不同数据库访问的底层细节,开发好代码后,如果要换数据库,几乎不需要改代码, 修改几个配置项就可以了。
- 定义数据库表—-定义继承自 django.db.models.Model 的类
- 定义表中的字段(列)—-定义该类的一些属性
- 类的方法就是对该表中数据的处理方法,包括 数据的增、删、改、查 ### 5.2 创建表 首先创建一个名为common的应用目录, 存放项目需要的一些公共表的定义。进入项目根目录,执行命令python manage.py startapp common。 数据库表的定义,一般放在app目录中的 models.py。
from django.db import modelsclass Customer(models.Model): # 用户表,继承django.db.models.Model # 定义表的3个字段 # 客户名称 name = models.CharField(max_length=200) # 对应varchar类型 # 联系电话 phonenumber = models.CharField(max_length=200) # 地址 address = models.CharField(max_length=200)不同的对应类型可以参考官方文档。 在项目的配置文件settings.py中的INSTALLED_APPS项加入如下内容:
INSTALLED_APPS = [ 'django.contrib.admin', 'django.contrib.auth', 'django.contrib.contenttypes', 'django.contrib.sessions', 'django.contrib.messages', 'django.contrib.staticfiles', # 加入下面这行 'common.apps.CommonConfig', # 声明CommonConfig 是 common/apps.py 文件中定义的一个应用配置的类。]class CommonConfig(AppConfig): name = 'common' # name 用来定义 应用的python模块路径其他配置参数可以参考官方文档 现在Django知道了 common 应用, 可以在项目根目录下执行命令python manage.py makemigrations common。得到结果如下:
Migrations for 'common': common\migrations\0001_initial.py - Create model Customer此时在common目录下面出现了0001_initial.py, 这个脚本就是相应要进行的数据库操作代码。随即,执行命令python manage.py migrate即可创建。 如果以后修改了Models.py 里面的库表的定义,都需要再次运行运行如下两个命令,使数据库同步该修改结果:
python manage.py makemigrations common # 后面的是Apppython manage.py migrate如果误操作删除了某个model对应的表,可先将该表的model注释,执行:
python manage.py makemigrations common # 后面的是Apppython manage.py migrate --fake之后在解除掉对应model的注释,并执行如下语句:
python manage.py makemigrations common # 后面的是Apppython manage.py migrate5.3 数据库数据读取
# 导入 Customer 对象定义from common.models import Customerdef listcustomers(request): # 返回一个 QuerySet 对象 ,包含所有的表记录 # 每条表记录都是是一个dict对象, # key 是字段名,value 是 字段值 qs = Customer.objects.values() # 返回包含所有Customer表记录的QuerySet对象 # 定义返回字符串 retStr = '' for customer in qs: # 遍历所有对象。每个对象都是一个dict对象 for name,value in customer.items(): # 取出每个对象的键值对 retStr += f'{name} : {value} | ' # <br> 表示换行 retStr += '<br>' return HttpResponse(retStr)有时需要根据过滤条件查询部分客户信息,比如在浏览器中输入/sales/customers/?phonenumber=13000000001要求返回电话号码为13000000001的客户记录。可以通过 filter 方法加入过滤条件:
def listcustomers(request): qs = Customer.objects.values() # 检查url中是否有参数phonenumber ph = request.GET.get('phonenumber',None) # 参数名要和字段名一致 # 如果有,添加过滤条件 if ph: qs = qs.filter(phonenumber=ph) # 可以传入多个过滤参数 # 定义返回字符串 retStr = '' for customer in qs: for name,value in customer.items(): retStr += f'{name} : {value} | ' # <br> 表示换行 retStr += '<br>' return HttpResponse(retStr)5.4 Model中的数据类型
- CharField:字符串
- FloatField:浮点数
- IntegerField:整数
- BigIntegerField:大整数
- AutoField:自增长整数
- BigAutoField:大自增长数
- BooleanField:布尔数
- BinaryField:二进制数
- DateField:日期
- DateTimeField:日期时间
- DecimalField:设置精度的十进制数
- FileField:文件 ## 5. 前后端分离
# 先定义好HTML模板html_template ='''html模板'''def listcustomers(request): # 查询数据库,返回QuerySet 对象 ,包含所有的表记录 qs = Customer.objects.values() # 检查url是否有参数phonenumber ph = request.GET.get('phonenumber',None) # 如果有,添加过滤条件 if ph: qs = qs.filter(phonenumber=ph) # 生成html模板中要插入的html片段内容 tableContent = '' for customer in qs: tableContent += '<tr>' for name,value in customer.items(): tableContent += f'<td>{value}</td>' tableContent += '</tr>' return HttpResponse(html_template%tableContent)很多后端框架都提供了一种 模板技术, 可以在html 中嵌入编程语言代码片段, 用模板引擎(就是一个专门处理HTML模板的库)来动态的生成HTML代码。比如JavaEE 里面的JSP。Django也内置了一个这样的模板引擎。
# 先定义好HTML模板html_template ='''<!DOCTYPE html><html><head><meta charset="UTF-8"><style>table { border-collapse: collapse;}th, td { padding: 8px; text-align: left; border-bottom: 1px solid #ddd;}</style></head> <body> <table> <tr> <th>id</th> <th>姓名</th> <th>电话号码</th> <th>地址</th> </tr> {% for customer in customers %} <tr> {% for name, value in customer.items %} <td>{{ value }}</td> {% endfor %} </tr> {% endfor %} </table> </body></html>'''from django.template import enginesdjango_engine = engines['django']template = django_engine.from_string(html_template)def listcustomers(request): # 返回一个 QuerySet 对象 ,包含所有的表记录 qs = Customer.objects.values() # 检查url中是否有参数phonenumber ph = request.GET.get('phonenumber',None) # 如果有,添加过滤条件 if ph: qs = qs.filter(phonenumber=ph) # 传入渲染模板需要的参数 rendered = template.render({'customers':qs}) return HttpResponse(rendered)更多Django模板用法可参考官方文档 当今前端 和 后端 之间的交互几乎完全是 业务数据。因此需要 定义好 前端和后端 交互数据 的接口。目前通常这样的接口设计最普遍的就是使用 REST 风格的 API 接口。现在我们的API接口 已经由架构师定义好了,只需要根据这个接口文档,实现后端系统的部分。 Django返回的信息通常都是所谓的 动态 数据信息。 比如:用户信息,药品信息,订单信息,等等。这些信息通常都是存在数据库中,会随着系统的使用发生变化的。而 静态 信息,比如: 页面HTML文档、css文档、图片、视频等,是不应该由 Django 负责返回数据的。 ## 6. 对资源的增删改查 仅使用views.py处理HTTP请求会使得该文件过于庞杂,不利于维护。可以创建不同的文件处理不同类型的HTTP请求。例如,可以新增一个文件 customer.py, 专门处理 客户端对 customer 数据的操作。 从接口文档中发现对数据的增删改查都是同一个URL/api/mgr/customers,区别主要在于HTTP操作类型不同,如PUT、DELETE、POST、GET,action参数表明这次请求的具体操作。在customers.py中定义如下函数:
from django.http import JsonResponseimport jsondef dispatcher(request): # 请求参数都在 request 的 params(dict类型) 属性中 # GET请求 参数在url中,通过request 对象的 GET属性获取 if request.method == 'GET': request.params = request.GET # POST/PUT/DELETE 请求参数从 request 对象的 body 属性中获取 elif request.method in ['POST','PUT','DELETE']: # 根据接口文件描述,POST/PUT/DELETE 请求的消息体都是 json格式 request.params = json.loads(request.body) # 根据不同的action分派给不同的函数进行处理 action = request.params['action'] if action == 'list_customer': return listcustomers(request) elif action == 'add_customer': return addcustomer(request) elif action == 'modify_customer': return modifycustomer(request) elif action == 'del_customer': return deletecustomer(request) else: return JsonResponse({'ret': 1, 'msg': '不支持该类型http请求'})6.1 查看客户数据
根据接口文档,后端返回的数据格式如下:
{ "ret": 0, "retlist": [ { "address": "江苏省常州武进市白云街44号", "id": 1, "name": "武进市 袁腾飞", "phonenumber": "13886666666" }, { "address": "北京海淀区", "id": 4, "name": "北京海淀区代理 蔡国庆", "phonenumber": "13990123456" } ]}from common.models import Customerdef listcustomers(request): # 返回一个 QuerySet 对象 ,包含所有的表记录 qs = Customer.objects.values() # 将 QuerySet 对象 转化为 list 类型 # 否则不能 被 转化为 JSON 字符串 retlist = list(qs) return JsonResponse({'ret': 0, 'retlist': retlist})6.2 添加客户信息
根据接口文档,前端提供的客户数据格式如下:
{ "action":"add_customer", "data":{ "name":"武汉市桥西医院", "phonenumber":"13345679934", "address":"武汉市桥西医院北路" }}def addcustomer(request): info = request.params['data'] # 将数据插入到数据库中 # 返回值 就是对应插入记录的对象 record = Customer.objects.create(name=info['name'] , phonenumber=info['phonenumber'] , address=info['address']) return JsonResponse({'ret': 0, 'id':record.id})根据接口文档,添加客户 请求是个Post请求。缺省创建的项目, Django 会启用一个 CSRF (跨站请求伪造) 安全防护机制。在这种情况下, 所有的Post、PUT 类型的 请求都必须在HTTP请求头中携带用于校验的数据。为了简单起见,我们先临时取消掉CSRF的 校验机制,等以后有需要再打开。 在项目配置文件bysms/settings.py中,将MIDDLEWARE配置项里的django.middleware.csrf.CsrfViewMiddleware注释掉。 ### 6.3 修改客户信息 根据接口文档,修改客户数据接口,前端提供的数据格式如下:
{ "action":"modify_customer", "id": 6, "newdata":{ "name":"武汉市桥北医院", "phonenumber":"13345678888", "address":"武汉市桥北医院北路" }}我们可以使用如下函数处理:
def modifycustomer(request): customerid = request.params['id'] newdata = request.params['newdata'] try: # 根据 id 从数据库中找到相应的客户记录 customer = Customer.objects.get(id=customerid) except Customer.DoesNotExist: return { 'ret': 1, 'msg': f'id 为`{customerid}`的客户不存在' } # 存在相应的列就更新 if 'name' in newdata: customer.name = newdata['name'] if 'phonenumber' in newdata: customer.phonenumber = newdata['phonenumber'] if 'address' in newdata: customer.address = newdata['address'] # 保存到数据库 customer.save() return JsonResponse({'ret': 0})6.4 删除客户
根据接口文档,删除客户数据接口如下:
{ "action":"del_customer", "id": 6}def deletecustomer(request): customerid = request.params['id'] try: # 根据 id 从数据库中找到相应的客户记录 customer = Customer.objects.get(id=customerid) except Customer.DoesNotExist: return { 'ret': 1, 'msg': f'id 为`{customerid}`的客户不存在' } # delete 方法就将该记录从数据库中删除了 customer.delete() return JsonResponse({'ret': 0})6.5 Web API 接口测试
Python可直接使用 requests 库做 Web API 接口测试。只需使用 requests库构建各种接口规定的 http 请求消息, 并且检查响应。比如,要检查 列出客户 的接口。
import requests,pprintresponse = requests.get('http://localhost/api/mgr/customers?action=list_customer')pprint.pprint(response.json())要检查 添加客户 的接口,如下:
import requests,pprint# 构建添加 客户信息的 消息体,是json格式payload = { "action":"add_customer", "data":{ "name":"武汉市桥西医院", "phonenumber":"13345679934", "address":"武汉市桥西医院北路" }}# 发送请求给web服务response = requests.post('http://localhost/api/mgr/customers', json=payload)pprint.pprint(response.json())6.6 自定义User表
Django 内置模块 contrib.auth的用户表 user 如果不符合我们的需求,推荐通过继承 contrib.auth.models 里面的 AbstractUser 类来创建。在 models 里面进行如下定义:
from django.contrib.auth.models import AbstractUserfrom django.contrib.auth.hashers import make_password,check_password# 可以通过 命令 python manage.py createsuperuser 来创建超级管理员# 就是在这User表中添加记录class User(AbstractUser): id = models.BigAutoField(primary_key=True) # 用户类型 usertype = models.PositiveIntegerField() # 真实姓名 realname = models.CharField(max_length=30, db_index=True) # 学号 studentno = models.CharField( max_length=10, db_index=True, null=True, blank=True ) # 备注描述 desc = models.CharField(max_length=500, null=True, blank=True) REQUIRED_FIELDS = ['usertype', 'realname'] class Meta: db_table = "by_user"这样就在原来 contrib.auth 的 user表的基础上:
- 新增了 usertype、realname、phone、studentno、desc 这些字段
- 修改了 字段 id 的类型 为 BigAuto
- 声明了 用命令 createsuperuser 添加用户时, ‘usertype’,‘realname’ 是需要提示用户填写的内容
在 settings.py 中,添加设置AUTH_USER_MODEL = ‘myapp.User’。一定要确保 这个 myapp 在你的 INSTALLED_APPS 里面设置了。 ### 6.7 用户表中的password Django 的密码不是明文存储的,可以使用 Django 库提供的方法 产生 password 字段值(通常hash处理过)。
from django.contrib.auth.hashers import make_password,check_password# 添加一条记录user = User.objects.create( username = username, # 使用 make_password 函数 产生password字段 password = make_password(data['password']), # 其他字段...)Django auth 库的 authenticate 方法 就包含了 校验用户名、密码的过程user = authenticate(username=userName, password=passWord) 有的系统设计完全弃用了 Django 的 auth、session 机制,我们仍然可以使用 hashers库里面的 check_password 方法 校验密码,如下
from django.contrib.auth.hashers import make_password,check_password# 检查密码if not check_password('密码明文', user.password): return JsonResponse({'retcode': 1, 'msg': '密码错误'})7. 使用Django实现登录
创建sign_in_out.py来处理管理员登录和登出的API请求。Django中有个内置app django.contrib.auth ,缺省包含在项目Installed App设置中。这个app 的 models 包含了一张 用户表,名为 auth_user 。django.contrib.auth 已经 为我们做好了登录验证功能。只需要使用这个app库里面的方法就可以了。 在sign_in_out.py中添加如下代码:
from django.http import JsonResponsefrom django.contrib.auth import authenticate, login, logout# 登录处理def signin( request): # 从 HTTP POST 请求中获取用户名、密码参数 userName = request.POST.get('username') passWord = request.POST.get('password') # 使用 Django auth 库里面的 方法校验用户名、密码 user = authenticate(username=userName, password=passWord) # 如果能找到用户,并且密码正确 if user is not None: if user.is_active: if user.is_superuser: login(request, user) # 在session中存入用户类型 request.session['usertype'] = 'mgr' return JsonResponse({'ret': 0}) else: return JsonResponse({'ret': 1, 'msg': '请使用管理员账户登录'}) else: return JsonResponse({'ret': 0, 'msg': '用户已经被禁用'}) # 否则就是用户名、密码有误 else: return JsonResponse({'ret': 1, 'msg': '用户名或者密码错误'})# 登出处理def signout( request): # 使用登出方法 logout(request) return JsonResponse({'ret': 0})在 urls.py 的urlpatterns中添加path(‘signin’, sign_in_out.signin), path(‘signout’, sign_in_out.signout), 在先前的处理中,前端发来的 Customer API 请求, 我们后端代码就直接处理了, 并没有验证 这个请求是不是已经登录的管理员发出的。如果是这样,客户端可以不需要登录,直接访问 登录后的主页。对于请求消息的合法性验证, 通常有两种方案: session 和 token ### 7.1 session(会话) 服务端在数据库中保存了一张session表。 这张表记录了一次用户登录的相关信息。记录的信息 不同的系统各有差异, 通常会记录该用户的ID 、姓名 、登录名之类的。Django中该表名字叫 django_session:
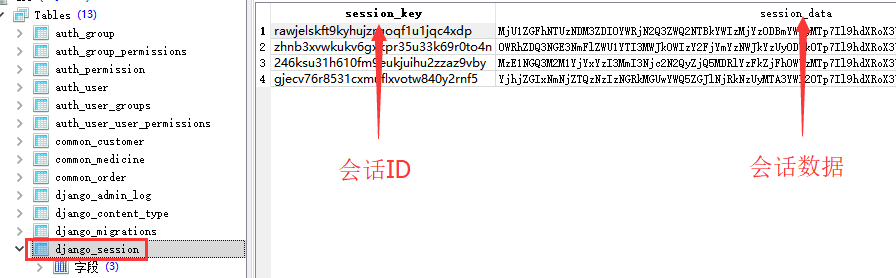
sessionid 是一串字符串用,对应的数据在这里是加密的。通过这张表,服务端可根据 session ID查到 session 的信息数据。用户登录成功后, 服务端就在数据库session表中创建一条记录,记录这次会话。然后在该登录请求的HTTP响应消息中的头字段 Set-Cookie 里填入 sessionid 数据。如Set-Cookie: sessionid=6qu1cuk8cxvtf4w9rjxeppexh2izy0hh 根据http协议, 这个Set-Cookie字段的意思就是 要求前端将其中的数据存入 cookie中。 并且随后访问该服务端的时候, 在HTTP请求消息中必须带上 这些 cookie数据。cookie 通常就是存储在客户端浏览器的一些数据。 服务端可以通过http响应消息 要求 浏览器存储 一些数据。以后每次访问 同一个网站服务, 必须在HTTP请求中再带上 这些cookie里面的数据。cookie数据由多个 键值对组成, 比如:
sessionid=6qu1cuk8cxvtf4w9rjxeppexh2izy0hhusername=byhyfavorite=phone_laptop_watch该用户的后续操作,触发的HTTP请求, 都会在请求头的Cookie字段带上sessionid。服务端接受到该请求后,只需要到session表中查看是否有该 sessionid 对应的记录,就可以判断这个请求是否是前面已经登录的用户发出的。如果不是,就可以拒绝服务,重定向http请求到登录页面让用户登录。 本章的sign_in_out.py文件中需要 加上一个验证逻辑。验证请求的cookie里面是否有sessionid,并且检查session表,看看是否存在session_key为该sessionid 的一条记录,该记录的数据字典里面是否 包含了 usertype 为 mgr 的 数据。前面实现的代码中, 这些请求都是在dispatcher入口函数处理的,我们就只需在该dispatch中进行验证。
# 根据session判断用户是否是登录的管理员用户 if 'usertype' not in request.session: return JsonResponse({ 'ret': 302, 'msg': '未登录', 'redirect': '/mgr/sign.html'}, status=302) if request.session['usertype'] != 'mgr' : return JsonResponse({ 'ret': 302, 'msg': '用户非mgr类型', 'redirect': '/mgr/sign.html'} , status=302)注意request对象里面的session属性对应的就是 session记录里面的 数据。 ### 7.2 token机制 session验证用户请求合法性 的主要缺点有两个:
- 性能问题:验证请求是根据sessionid 到数据库中查找session表的,而数据库操作是服务端常见的性能瓶颈,尤其是当用户量比较大的时候。
- 扩展性问题:当系统用户特别多的时候,后端处理请求的服务端通常部署在多个节点上。 但是多个节点都要访问session表,这样就要求数据库服务能够被多个节点访问,不方便切分数据库以提高性能。
token 简单来说,就是包含了 数据信息 和 校验信息的 数据包。Session 机制是把 数据信息(比如session表)放到 服务端,服务端数据是客户无法篡改的,从而保证验证的 可靠性。而 token机制 数据信息 直接传给 客户端,客户每次请求再携带过来给服务端。服务端无需查找数据库,直接根据token里面的数据信息进行校验。token 机制的原理如下:
- 服务端配置一个密钥(secret key),该密钥是服务端私密保存的,不能外泄
- 在用户登录成功后, 服务端将 用户的信息数据 + 密钥 一起进行一个哈希计算, 得到一个哈希值。如果谁修改了用户信息, 除非他知道密钥,再次使用哈希算法才能得到 正确的新的 哈希值。然后将 用户数据信息 和 哈希值 一起 做成一个字节串 ,这个字节串就称之为 token 。token 里面 包含了用户数据信息 和 用于校验完整性的哈希值。然后,服务端返回给客户的HTTP响应中 返回了这个token。 通常token是放在HTTP响应的头部中的。 具体哪个头部字段没有规定,开发者可以自行定义。
- 该用户的后续操作,触发的HTTP API请求, 会在请求消息里面 带上 token 。具体在请求消息的什么地方 存放 token, 由开发者自己定义,通常也存放在http 请求 的头部中。服务端接收到请求后,会根据 数据信息 和 密钥 使用哈希算法再次 生成 哈希值。校验通过后,就确信了数据没有被修改,可以放心的使用token里面的数据 进行后续的业务逻辑处理了。
上述处理中,由于不需要服务端访问查找数据库,从而大大了提高了处理性能。 ## 8. 数据库表的关联 ### 8.1 一对多 一对多的关系其实就是外键关联关系。Django使用ORM进行表创建:
import datetimeclass Order(models.Model): # 订单名 name = models.CharField(max_length=200,null=True,blank=True) # 创建日期 create_date = models.DateTimeField(default=datetime.datetime.now) # 客户。指向Customer类主键的外键 customer = models.ForeignKey(Customer,on_delete=models.PROTECT)当删除Customer记录时,Order的不同处理策略:
- CASCADE:删除主键记录和相应的外键表相关的所有记录。
- PROTECT:禁止删除记录。
- SET_NULL:删除主键记录,并且将外键记录中外键字段的值置为null。 前提是外键字段允许是null。
定义 Model类时,如果没有指定主键字段,migrate 时 Django 会为该Model对应的数据库表自动生成一个id字段,作为主键。 注意: 外键字段在数据库表中的 字段名, 是 Django ForeignKey 定义 字段名加上后缀 _id 。比如这里 customer 外键字段在 数据库表中的字段名 是 customer_id。 ### 8.2 一对一 即 一条主键所在表的记录 只能对应一条 外键所在表的记录。Django 中 用 OneToOneField 对象 实现 一对一 的关系,如下:
class Student(models.Model): # 姓名 name = models.CharField(max_length=200) # 班级 classname = models.CharField(max_length=200) # 描述 desc = models.CharField(max_length=200)class ContactAddress(models.Model): # 一对一 对应学生 student = models.OneToOneField(Student, on_delete=models.PROTECT) # 家庭 homeaddress = models.CharField(max_length=200) # 电话号码 phone = models.CharField(max_length=200)在migrate时,数据库定义该字段为外键的同时会加上 unique=True 约束。 ### 8.3 多对多 Django是通过 ManyToManyField 对象 表示 多对多的关系的。
import datetimeclass Order(models.Model): # 订单名 name = models.CharField(max_length=200,null=True,blank=True) # 创建日期 create_date = models.DateTimeField(default=datetime.datetime.now) # 客户 customer = models.ForeignKey(Customer,on_delete=models.PROTECT) # 订单购买的药品,和Medicine表是多对多 的关系 medicines = models.ManyToManyField(Medicine, through='OrderMedicine')class OrderMedicine(models.Model): order = models.ForeignKey(Order, on_delete=models.PROTECT) medicine = models.ForeignKey(Medicine, on_delete=models.PROTECT) # 订单中药品的数量 amount = models.PositiveIntegerField()在指定Order表和 Medicine 表 的多对多关系后, Order表并不会产生medicines 字段。它们的多对多关系 是 通过另外一张表, 也就是 through 参数 指定的 OrderMedicine 表 来确定的。migrate的时候,Django会自动产生一张新表 (这里就是 common_ordermedicine)来 实现 order 表 和 medicine 表之间的多对多关系。 ### 8.4 ORM关联表 接下来演示Django ORM 如何 操作 外键关联关系。
# 国家表class Country(models.Model): name = models.CharField(max_length=100)# 学生表, country 字段是国家表的外键,形成一对多的关系class Student(models.Model): name = models.CharField(max_length=100) grade = models.PositiveSmallIntegerField() country = models.ForeignKey(Country,on_delete=models.PROTECT)然后命令行中执行 python manage.py shell ,直接启动Django命令行,执行如下命令创建一些数据:
from common.models import *c1 = Country.objects.create(name='中国')c2 = Country.objects.create(name='美国')c3 = Country.objects.create(name='法国')Student.objects.create(name='白月', grade=1, country=c1)Student.objects.create(name='黑羽', grade=2, country=c1)Student.objects.create(name='大罗', grade=1, country=c1)Student.objects.create(name='真佛', grade=2, country=c1)Student.objects.create(name='Mike', grade=1, country=c2)Student.objects.create(name='Gus', grade=1, country=c2)Student.objects.create(name='White', grade=2, country=c2)Student.objects.create(name='Napolen', grade=2, country=c3)外键表字段 的访问,只需执行如下代码:
s1 = Student.objects.get(name='白月')s1.country.name如果我们要查找Student表中所有 一年级 学生需要进行如下条件过滤:
Student.objects.filter(grade=1).values()对外键进行country进行条件过滤与字段过滤:
Student.objects.filter(grade=1,country__name='中国').values('name','country__name')使用annotate关键字进行字段重命名:
Student.objects.annotate( countryname=F('country__name'), studentname=F('name') ).filter(grade=1,countryname='中国').values('studentname','countryname')Django ORM中,关联表 正向关系是通过表外键字段 表示, 比如前面例子中Student表的 country字段。而反向关系,是通过 表Model名转化为小写 加上一个 _set 来获取所有的反向外键关联对象。比如,已经获取了一个Country对象,现在需要获取属于这个国家的学生可以执行如下代码:
cn = Country.objects.get(name='中国')cn.student_set.all()8.5 多对多记录添加
如果需要在2张表中添加记录,则意味着要有两次数据库操作。如果第一次插入成功, 而第二次插入失败, 数据库就会出现数据不一致,称为 脏数据。 可使用数据库 的 事务 机制来解决这个问题。把一批数据库操作放在 事务 中, 该事务中的任何一次数据库操作如果失败了, 数据库系统就会让 整个事务发生回滚,回滚到事务操作之前的状态。可使用 Django 的 with transaction.atomic()实现事务操作。
def addorder(request): info = request.params['data'] with transaction.atomic(): new_order = Order.objects.create(name=info['name'] , customer_id=info['customerid']) batch = [OrderMedicine(order_id=new_order.id,medicine_id=mid,amount=1) for mid in info['medicineids']] # 在多对多关系表中添加了多条关联记录。使用这条语句插入多条记录比一条记录一个语句快 OrderMedicine.objects.bulk_create(batch)# 参数是包含所有 该表的 Model 对象的 列表 return JsonResponse({'ret': 0,'id':new_order.id})8.6 分页
分页 就是每次只读取一页的信息返回给前端。前端发送的请求中需要携带 两个信息: 每页包含多少条记录 和 需要获取第几页。下面以列出药品的代码为例子:
# 增加对分页的支持from django.core.paginator import Paginator, EmptyPagedef listmedicine(request): try: # 要获取的第几页 pagenum = request.params['pagenum'] # 每页要显示多少条记录 pagesize = request.params['pagesize'] # 返回一个 QuerySet 对象 ,包含所有的表记录 qs = Medicine.objects.values().order_by('-id')# 按照 id字段的值 倒序排列 # 使用分页对象,设定每页多少条记录 pgnt = Paginator(qs, pagesize) # 从数据库中读取数据,指定读取其中第几页 page = pgnt.page(pagenum) # 将 QuerySet 对象 转化为 list 类型 retlist = list(page) # total指定了 一共有多少数据 return JsonResponse({'ret': 0, 'retlist': retlist,'total': pgnt.count}) # 返回共有多少页方便前端处理 except EmptyPage: return JsonResponse({'ret': 0, 'retlist': [], 'total': 0}) except: return JsonResponse({'ret': 2, 'msg': f'未知错误\n{traceback.format_exc()}'})8.7 过滤
过滤 就是 根据用户提供的筛选条件,只读取符合条件的部分信息。下面以查询药品信息为例子。
# 下述两种写法是一样的,表示一种AND关系qs.filter(name__contains='乳酸',name__contains='注射液') # Django执行的SQL代码是WHERE name LIKE '%乳酸%' AND name LIKE '%注射液%'qs.filter(name__contains='乳酸').filter(name__contains='注射液')如果 过滤涉及到关联表,结果可能会不同 表示OR关系可以用Django 里面提供 的 Q 对象 。Q 对象 的初始化参数里面 携带 和 filter 语法一致的 条件,比如:
from django.db.models import Qqs.filter( Q(name__contains='乳酸') | Q(name__contains='注射液')) # 等价于 WHERE name LIKE '%乳酸%' OR name LIKE '%注射液%'qs.filter( Q(name__contains='乳酸') & Q(name__contains='注射液')) # 等价于 WHERE name LIKE '%乳酸%' AND name LIKE '%注射液%'除了 等于、包含 这两种过滤类型, 还有 值大于、值小于、值在(列表中)等等。还有对 过滤值的一些 特殊处理,比如 购买时间的 年、月、日 部分在某个范围内 等等,这些底层都是对应SQL的一些内置函数。详情请参考官方文档
# 查看是否有 关键字 搜索 参数keywords = request.params.get('keywords',None)if keywords: conditions = [Q(name__contains=one) for one in keywords.split(' ') if one]# 先构建一个空Q对象 , 表示没有任何过滤条件, 然后 循环取出过滤关键字, 使用 & 叠加过滤条件。query = Q()for condition in conditions: query &= conditionqs = qs.filter(query) # query 就是 多个 过滤条件 同时满足 的 Q 对象Analyzer.objects.values('product_id_id').distinct().count()# product_id_id9. 使用Python发送邮件
邮箱发送邮件通常经过下述几个步骤:
- 登录邮箱
- 确定发送邮件的账号,确定是群发还是单发。
- 添加内容,一般包括对方信息、标题、正文、附件等等。
- 点击发送。
使用Python发送邮件首先要开通邮箱的
SMTP
。
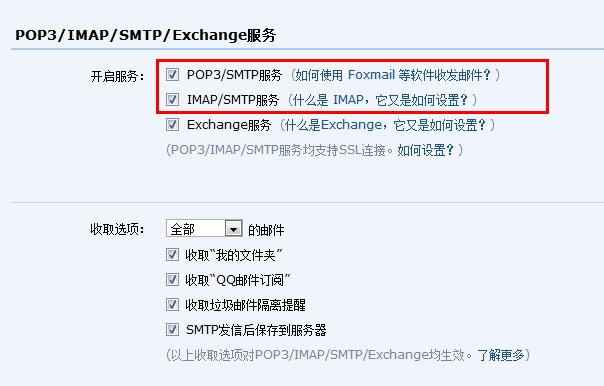
开启该服务后,系统将会授予密钥(该密钥只会显示一次),该密钥会在邮件发送时使用。在Python中主要有两个和邮件发送相关的模块,分别为:
- smtplib:这个模块是关于SMTP(简单邮件传输协议)的操作模块,在发送邮件的过程中使用这个模块来和你的发送账户的服务器建立通信。
- email:这个模块用来编辑添加各种需要发送的内容,比如编辑正文添加附件等。
import smtplibfrom email.mime.text import MIMETextfrom email.mime.multipart import MIMEMultipartMIMEText是一个用来处理文本内容的模块,比如我们的正文一般是文本内容,我们也会上传文本附件等。 MIMEMultipart代表我们要发送的邮件对象,可以把MIMEMultipart理解为一个容器,MIMEText、MIMEImage等模块都包含在容器之中。 我们发送邮件可以简单理解为先产生一个容器(邮件),然后把其它东西(正文、附件等)放进去,最后把容器发送出去。注意,邮件不可发送给自己。
# 设置建立通信的服务器信息email_host = 'smtp.163.com' # 'stmp.qq.com'# 设置登录邮箱的用户名和密匙email_user = '用户名'email_pass = '密匙'# 发送邮件的邮箱账户sender = '你的邮箱账户'# 接收邮件的邮箱账户100receivers = ['邮箱账户1','邮箱账户2']# 创建MIMEMultipart对象,相当于一封邮件message = MIMEMultipart()# 设置发送方message['From'] = sender# 设置接收方message['To'] = ';'.join(receivers)# 设置邮件大标题,它是一个字符串message['Subject'] = '我喜欢你'# 设置邮件正文content = '你好,我是goldsunC,这是我发送给你的一封情书。'part1 = MIMEText(content,'plain','utf-8')# 添加txt附件with open('text.txt','r') as f: content1 = f.read()part2 = MIMEText(content1,'plain','utf-8')# 设置其附件类型,便于发送part2['Content-Type'] = 'application/octet-stream'part2['Content-Disposition'] = 'attachment;filename="text.txt"'# 添加一个图片附件with open('picture.jpg','rb') as f: content2 = f.read()part3 = MIMEImage(content2)# 设置附件类型part3['Content-Type'] = 'application/octet-stream'part3['Content-Disposition'] = 'attachment;filename="picture.jpg"'# 将内容添加到邮件中message.attach(part1)message.attach(part2)message.attach(part3)# 与服务器建立通信并发送邮件try: receivers = receivers + [sender] # 给自己发一份是防止邮件被163识别为垃圾邮件 email_stmp = smtplib.SMTP_SSL(email_host,465) # email_stmp.login(mail_user,mail_pass) #登录 email_stmp.sendmail(sender,receivers,message.as_string()) #发送! print('success')except smtplib.SMTPException as e: print('error',e)10. Windows部署
10.1 部署过程
- 安装IIS:控制面板-程序-程序和功能-启动或关闭Windows功能,勾选以下部分:

image-20220408193204063.png
- 关闭调试与wfastcgi应用服务安装:修改settings.py如下
DEBUG = False # 关闭调试ALLOWED_HOSTS = ['*'] # 指定能访问网站的主机IP以管理员身份运行 命令提示符,安装wfastcgi`并启动:
pip install wfastcgiwfastcgi-enable # 启动服务,需要以管理员方式执行#wfastcgi-disable # 停止服务# 该服务仅可启动一次,再次启动将会报错在执行服务启动命令后,要将出现的python路径和wfastcgi路径保存下来,例如:
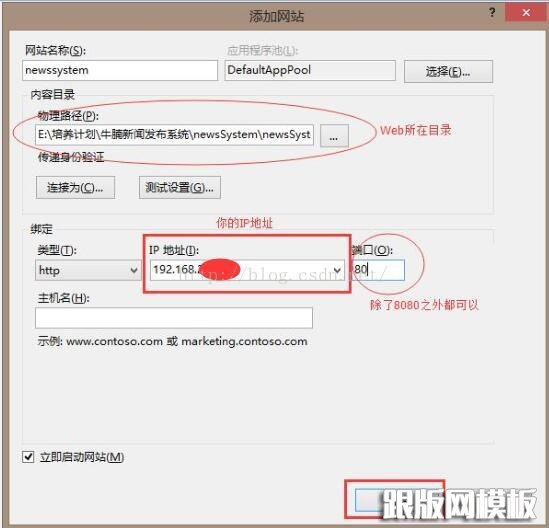
D:\anaconda3\python.exe|D:\anaconda3\lib\site-packages\wfastcgi.py- 网站发布:此电脑-管理- 服务和应用程序-Internet Information Services(IIS)管理器-网站-添加网站:
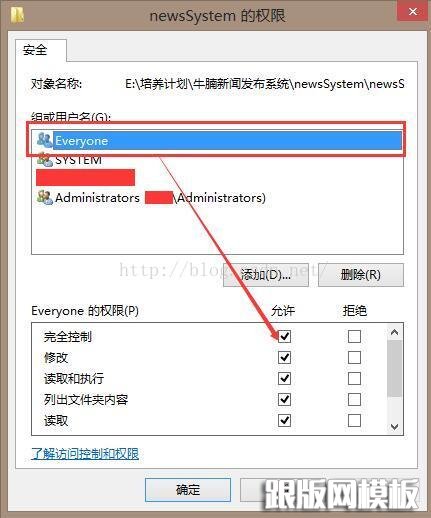
点击创建的网站,编辑权限→安全→编辑→添加→高级→立即查找→Everyone。将Everyone设置为完全 控制。
- 添加配置文件:在项目根目录下新建 “web.config” 配置文件,复制粘贴以下内容。
<?xml version="1.0" encoding="UTF-8"?><configuration> <system.webServer> <handlers> <add name="Python FastCGI" path="*" verb="*" modules="FastCgiModule" scriptProcessor="<Path to Python>\python.exe|<Path to Python>\lib\site-packages\wfastcgi.py" resourceType="Unspecified" requireAccess="Script"/> </handlers> </system.webServer> <appSettings> <add key="WSGI_HANDLER" value="django.core.wsgi.get_wsgi_application()" /> <add key="PYTHONPATH" value="<Path to Django App>" /> <add key="DJANGO_SETTINGS_MODULE" value="<Django App>.settings" /> </appSettings></configuration>分别按要求对上述scriptProcessor、PYTHONPATH、DJANGO_SETTINGS_MODULE属性进行修改。
- 添加静态文件虚拟目录:
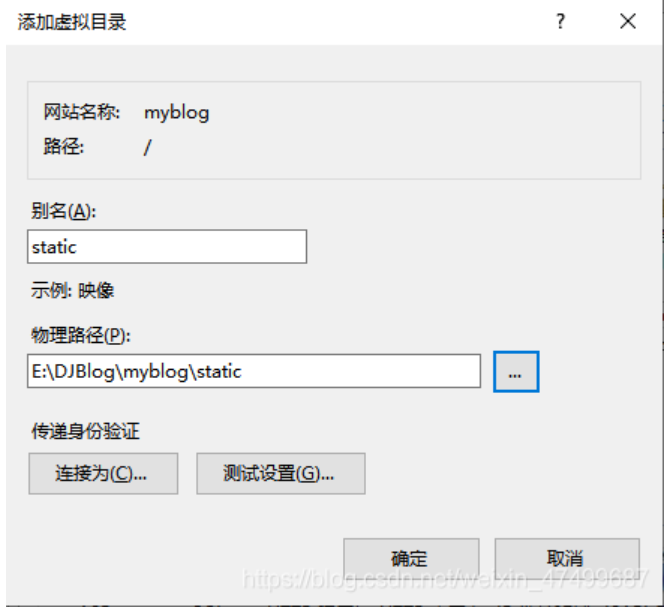
虚拟目录别名与settings里设置的一致,物理路径就是静态资源的实际目录。在 static 目录下新建一个 “web.config” 文件,然后添加下面的内容。
<?xml version="1.0" encoding="UTF-8"?><configuration> <system.webServer> <!-- this configuration overrides the FastCGI handler to let IIS serve the static files --> <handlers> <clear/> <add name="StaticFile" path="*" verb="*" modules="StaticFileModule" resourceType="File" requireAccess="Read" /> </handlers> </system.webServer></configuration>10.2 出现的问题
绝大部分问题都是版本不对应造成的。
# Anaconda创建指定python虚拟环境conda create -n 虚拟环境名称 python=3.6.7 亲测3.6.7conda env list # 查看虚拟环境列表conda activate 虚拟环境名称 #conda install pytorch==1.10.1 torchvision==0.11.2 torchaudio==0.10.1 cudatoolkit=11.3 -c pytorch -c conda-forge11. Linux云服务部署
Web服务通常部署在云服务厂商的云主机上,操作系统普遍采用 Linux ,数据库通常是 MySQL、Oracle等。本章将把基于Django和MySQL的Web系统部署到Linux操作系统上。
部署网站结构 对于下面的简单网站结构,需要注意以下几点:
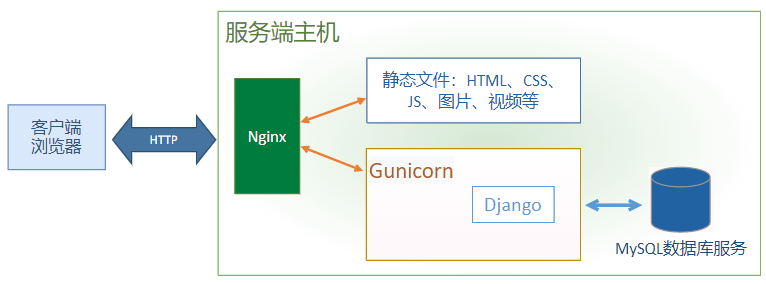
- 应当使用Nginx来处理静态资源请求,而不是Django。
- Django 不应直接处理 HTTP请求,应当借助uWSGI、Gunicorn等专业工具处理。Django虽然是wsgi web application 框架,它只有一个单线程 wsgi web server,性能很低。
如上所示,首先由 Nginx 实现 负载均衡、反向代理、请求缓存、响应缓存 、负荷控制等一系列功能。接着再调用相应的静态文件或Gunicorn。这里为了简单,把整个后端系统部署在同一台Linux主机上,包括:Nginx、Gunicorn、Django、MySQL。
- Nginx:运行起来是多个进程,接收客户端请求。 根据请求的URL进行相应的功能调用。如果请求的是 静态资源,比如HTML文档、图片等,它直接从配置的路径进行读取并返回给客户端。如果请求的是动态数据, 转发给 Gunicorn+Django 进行处理。
- Gunicorn + Django:两者运行在同一个 Python进程里。Gunicorn启动时会根据配置加载Django入口模块,这个入口模块提供了WSGI接口。当 Gunicorn 收到 Nginx 转发的 HTTP请求后,调用 WSGI入口函数,Django框架根据请求的 URL 和项目配置的 URL 路由表,找到对应的消息处理函数进行处理。 ### 安装步骤 练习的时候可以用一台安装了Linux的虚拟机。可以根据此教程安装Ubuntu虚拟机。安装好后, 为了方便后续apt安装其它软件时,能从国内的apt源高速下载,需要设置一下apt源 产品往往会涉及好多子系统,前端通常包括 web前端、app前端, 后端 包括 业务处理系统、数据库系统、消息队列、异步任务系统、缓存系统等等。我们现在的系统 包括 web前端系统(包括web前端的HTML、css、图片、js业务代码、js库等文件)、后端业务处理系统、数据库系统。 不同的运营架构,部署的方式不同,需要构建发布包的方式也不同。根据我们的架构图,可以把 前端系统代码 做在一个发布包中, 后端系统做在另一个发布包中。我们完全可以 把 前后端系统 分别部署到 两台 Linux主机上。 目前我们先按照简单的来, 根据我们的架构图, 都部署在同一台机器上。现在我们假定发布的版本号为 1.5。前端发布包,由前端开发人员提供bysms_front_v1.5.zip提取码是9w2u。基于Django开发的后端系统,要发布正式版本:
- 首先拷贝你的开发项目目录到一个新的目录中,可以改名为 bysms_back_v1.5。修改其中 bysms/settings.py ,把下面的配置项DEBUG值为 False
- 把数据库改为生产环境的数据库。配置的 MySQL连接的 用户名、密码、数据库名、数据库服务主机名、端口 都要和你的环境匹配。
DATABASES = { 'default': { 'ENGINE': 'django.db.backends.mysql', 'NAME': 'bysms', # 数据库名 'USER': 'byhy', # 数据库 用户名 'PASSWORD': 'Mima123$',# 数据库 用户密码 'HOST': '127.0.0.1', # 数据库服务主机名 'PORT': '3306', # 数据库服务端口 'CONN_MAX_AGE': 0 }}- 添加 Linux 启动shell脚本:使用 Gunicorn 作为 Django的WSGI前端,首先我们需要创建一个 Gunicorn启动配置文件 ./bysms/gunicorn_conf.py ,内容如下:
# gunicorn/django 服务监听地址、端口bind = '127.0.0.1:8000'# gunicorn worker 进程个数,建议为: CPU核心个数 * 2 + 1workers = 3# gunicorn worker 类型, 使用异步的event类型IO效率比较高worker_class = "gevent"# 日志文件路径errorlog = "/home/byhy/gunicorn.log"loglevel = "info"import sys,oscwd = os.getcwd()sys.path.append(cwd)要保证我们的Django后端服务在linux上一个命令就能启动,需要开发一个 Linux 启动shell脚本 ./run.sh 。可以参考下面的 shell脚本内容:
#!/bin/bashDIR="$( cd "$( dirname "$0" )" && pwd )"echo $DIRcd $DIR# ulimit -n 50000nohup gunicorn --config=bysms/gunicorn_conf.py bysms.wsgi &> /dev/null &- 我们可以在该文件的末尾,加上版本号VERSION = ‘1.5’。
然后,删除 所有app 的 migrations 目录。最好把整个Django后端的代码打包,包名为 bysms_back_v1.5.zip ### 安装配置Nginx 首先以root 用户 登录Ubuntu主机,执行命令 apt install nginx 安装好 Nginx。Nginx的配置文件路径是: /etc/nginx/nginx.conf。可以使用vim去编辑这个文件,但是建议大家使用 winscp 连接 Linux主机并且,配置用notepad++远程打开。因为这样看起来更清楚,特别是配置文件中如果有中文,vi看起来可能会比较乱。打开该配置文件,修改其中的配置项,以满足你的网站需求。下面是一个Nginx配置示例,列出了其中核心的配置:
user byhy; # 用byhy用户运行Nginx进程worker_processes 2; # 启动两个Nginx worker 进程events { # 每个工作进程 可以同时接收 1024 个连接 worker_connections 1024;}# 配置 Nginx worker 进程 最大允许 2000个网络连接worker_rlimit_nofile 2000;http { include mime.types; default_type application/octet-stream; sendfile on; keepalive_timeout 30; gzip on; # 配置 动态服务器(比如Gunicorn/Django) # 主要配置 名称(这里是apiserver) 地址和端口 upstream apiserver { # maintain a maximum of 20 idle connections to each upstream server keepalive 20; server 127.0.0.1:8000; # 地址和端口 } # 配置 HTTP 服务器信息 server { # 配置网站的域名,这里请改为你申请的域名, 如果没有域名,使用IP地址。 server_name www.byhy.com; # 配置访问静态文件的根目录, root /home/byhy/bysms_frontend/z_dist; # 配置动态数据请求怎么处理 # 下面这个配置项说明了,当 HTTP 请求 URL以 /api/ 开头, # 则转发给 apiserver 服务器进程去处理 location /api/ { proxy_pass http://apiserver; proxy_set_header Host $host; } }}修改好配置后,必须重启Nginx,可以执行命令systemctl restart nginx。 如果启动报错, 可以打开 /var/log/nginx/error.log 查看nginx的错误日志文件。 为了使http服务的 80端口可以从外部访问,需要我们让防火墙开放80端口。对于Ubuntu 20 来说,就是执行命令ufw allow 80或者ufw allow ‘Nginx HTTP’ ### 安装Django
# 这是先安装pipapt install python3-pip# 再安装 Djangopip3 install Django -i https://pypi.douban.com/simple/安装 Gunicorn
pip3 install greenlet -i https://pypi.douban.com/simple/ # 异步需要pip3 install gevent # 异步需要pip3 install gunicorn安装MySQL
Ubuntu上MySQL的教程有 修改 mysql 绑定所有网络接口的设置, 如果你的机器是生产环境,通常不要这样做。 安装 好MySQL 服务后,执行 mysql 启动客户端 :
- 先使用root用户创建数据库bysms,指定使用utf8的缺省字符编码,执行命令
CREATE DATABASE bysms CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_520_ci;- 创建 bysms系统用来连接数据库的用户,保证该用户有访问 bysms数据库的权限,比如:
CREATE USER 'byhy'@'localhost' IDENTIFIED BY 'Mima123$';CREATE USER 'byhy'@'%' IDENTIFIED BY 'Mima123$';- 随后输入如下命令,赋予byhy 用户所有权限,就是可以 该DBMS系统上 访问所有数据库里面所有的表
GRANT ALL ON *.* TO 'byhy'@'localhost';GRANT ALL ON *.* TO 'byhy'@'%';安装MySQL客户端
执行 下面两个命令分别安装 MySQL 客户端开发库 和 Python 绑定库 mysqlclient
apt install libmysqlclient-devpip3 install mysqlclient -i https://pypi.douban.com/simple/创建产品运行用户
通常我们需要为运行产品进程,比如 Nginx work进程、Gunicorn 等,创建一个专门的用户。这里我们使用byhy用户。执行命令创建用户 adduser byhy 。 ### 安装产品发布包 以root以后登录,执行如下命令安装工具:dos2unix 、unzip
apt install dos2unixapt install unzip然后再以 byhy用户 登录Linux 主机,下载拷贝 前端、后端 发布包 bysms_front_v1.5.zip 和 bysms_back_v1.5.zip 到 byhy 用户home目录下面,也就是 /home/byhy 。 实际项目中,发布包如果不能直接wget下载,可以使用 winscp 拷贝到 Linux 主机上。然后执行下面的命令进行解压。
unzip bysms_front_v1.5.zipunzip bysms_back_v1.5.zip为了让Django认为你使用的虚拟机的IP地址或者域名是允许使用的, 需要修改settings.py 里面的配置项ALLOWED_HOSTS,加上一个你当前虚拟机的IP,也可以使用 ’*’ , 表示所有IP都可以。
ALLOWED_HOSTS = ['*','localhost','127.0.0.1']然后进入到 目录 bysms_back_v1.5 中,执行命令,让启动脚本符合linux文本格式,并且有可执行权限
dos2unix run.shchmod +x run.sh创建数据库表
执行下面的命令, 让Django 在数据库中 创建 你的系统所需要的表
python3 manage.py makemigrations <your_app_label>python3 manage.py migrate注意, 需要替换成你的 Django 项目中的 app (只需要写包含了数据库表定义的App)的名字,可以是多个app,中间用空格隔开。 开始我们要创建数据库的业务管理员账号,进入到manage.py所在目录,执行python3 manage.py createsuperuser 依次输入你要创建的管理员的 登录名、email、密码。
Username (leave blank to use 'byhy'): byhyEmail address: byhy@163.comPassword:Password (again):Superuser created successfully.启动Gunicorn/Django
进入到 byhy 用户home目录,执行命令 run.sh。然后,执行命令 ps -ef | grep python |grep gunicorn_conf |grep -v grep 查看 是否启动成功。 ### HTTPS服务 我们的服务运行在80端口上,是不加密的网站服务。为了安全考虑,需要运行在HTTPS协议上。这就需要我们申请证书,并且配置Nginx 使用HTTPS。 ## 缓存 处理一个请求,服务通常有如下事情:
- 接收HTTP请求消息,解析请求消息为数据对象
- 根据业务逻辑的需要,去访问数据库(增删改查)—–最耗费时间
- 处理结果转化为HTTP响应消息给 客户端
数据库操作 涉及到 数据库服务处理请求,读写硬盘数据。往往比较耗时。所以对 数据库操作的 优化 往往是提高系统性能的 首选目标。这节课程,我们重点讲解 通过 缓存 的方法来 优化对数据库 读操作 的 性能。 缓存即把 需要读取的数据库数据 存放到内存 中, 下次客户端请求读取同样的数据,可以直接从内存中读取。程序访问内存的速度要比访问数据库快很多, 因为避免了从硬盘读取表记录的操作。 特别是当一个读操作要涉及到多张表的联合查询,或者这些表比较大,就会非常耗时。 要缓存数据到内存,最简单的可直接使用Python内置的 字典对象缓存数据。但这种方法不支持 分布式计算。当我们的网站服务量巨大时,为了提高处理能力,会部署服务到多台主机。 我们应该使用一个类似 内存数据库 的 服务系统 ,提供统一的缓存服务。Redis 和 Memcached 是目前两种主流的缓存服务方案。 ### Linux安装Redis 推荐采用源码编译安装的方式,这样可以自由的选择要安装的Redis版本。比如在centos 7 上,以root用户登录,执行下面的命令下载、解压、编译安装
wget http://download.redis.io/releases/redis-5.0.6.tar.gztar xzf redis-5.0.6.tar.gzcd redis-5.0.6makemake testmake install接下来执行配置 和 启动 Redis 服务的命令
cd utils/ ; ./install_server.sh过程中会有非常多的交互式提示,基本上一路回车确认,使用默认配置,就可以了。执行完后, Redis 服务就会启动监听在默认端口6379上,并且会每次开机自动启动。 Redis默认会保存内存数据到磁盘,如果只是把Redis作为缓存使用,这样就会影响性能。我们可以通过如下方法修改配置文件,禁止保存数据到磁盘。执行命令 vim /etc/redis/6379.conf 打开配置文件,将文件中如下3行注释掉:
#save 900 1#save 300 10#save 60 10000如果你需要让这个Redis服务给非本机的程序(比如Django) 使用,就应该把配置文件中绑定的地址 从本机loop地址 127.0.0.1 改为 0.0.0.0。找到配置文件中,如下地方bind 127.0.0.1改为bind 0.0.0.0。 如果要给远程程序使用Redis服务,别忘了打开防火墙,开放 6379 端口。最后,执行下面的命令重启 Redis服务,使修改后的配置生效。 service redis_6379 restart ### Windows上安装 Redis 下载安装包,进入到目录 Redis-x64-3.2.100 ,运行里面的 redis-server.exe 就启动了 Redis服务。 注意:Redis key 对应的value 支持 多种类型 的数据对象。可以是字符串、列表、哈希对象(类似Python中的字典)。这一点和其他 键值对(key-value)系统不同。比如memcached的值只能是字符串。 按照上面讲述的方法,安装 Redis时,也会安装一个官方Redis 客户端。Windows下面是一个exe可执行程序: redis-cli.exe, 双击它即可运行。Linux 下面执行命令 redis-cli 即可运行。 和 MySQL 一样,Redis 里面也包含了多个数据库,以数字进行编号,缺省连接是编号为 0 的数据库。可以使用命令 select 来选择使用哪个Redis数据库,比如下面的命令就选择编号为1的数据库
> select 1OK127.0.0.1:6379[1]>Redis操作
根据存入数据对象 类型 的不同,我们需要使用不同的Redis命令。假设,我们要缓存一个用户表里面的数据,可以为key指定格式 user:。比如,id为1的用户,key就是 user:1,id为200的用户,key就是 user:200。如果我们要存入 Redis的value是字符串对象,就使用客户端命令 set。比如,要为id 为2000 的用户存入等级值 33,就执行命令set user:2000 33,要从Redis获取key为 user:2000 的值,就执行命令get user:2000 要查询系统中有哪些key,可以使用命令keys,可以使用通配符 。比如查询以 med 开头的keykeys med。如果要删除一个key和其对应的对象,可以使用命令deldel user:2001。 如果我们要存入 Redis的对象比较复杂,可以使用哈希(Hash)对象,它类似Python中的字典。存入Hashes,就使用客户端命令 hmset 或者 hset ,比如hmset user:2001 level 10 coin 1977 name 白月黑羽。注意最后存入的是其实是bytes字节,所以其中的中文字符会被进行相应的编码,比如utf8或者gbk,具体使用哪种编码,由客户端程序决定。 要获取Hash里面的对象,使用 hgetall, 如hgetall user:2001 如果只要获取 hash对象的一个字段,可以使用 hget,如hget user:2001 coin 注意, hmset 是存入多个字段值, 如果只要存入(或者修改)一个字段值,就用可以使用hset。比如要修改 coin的值为 2000,hset user:2001 coin 2000 既然 Hash 本身就是一个字典,我们通常还有一种方案:就是把 整个用户表 都直接放入 一个hash 里面。可以给这个hash对应的对象 起一个key名为 usertable 。然后就可以这样:
> hmset usertable u2001 id:2001|level:10|coin:1977|name:白月黑羽1> hmset usertable u2002 id:2002|level:13|coin:1927|name:白月黑羽2OK然后,要获取一个用户的信息,就可以hget usertable u2002 两种方案,各有优缺点。前者利于修改单个field的值,但是容易造成巨大的key数量, 污染 全局的key名字空间。后者正好相反, 没法修改单个field的值,要改只能一起改。 但是全局的key名字空间就比较清爽。具体采用哪种方案存储,开发者根据当前情况 自己权衡。 ### Django项目缓存配置 首先,执行下面的命令安装 一个库 django-redis
pip install django-redis然后在 Django 的项目配置文件 settings.py 中,添加如下的缓存配置项
CACHES = { "default": { "BACKEND": "django_redis.cache.RedisCache", "LOCATION": "redis://127.0.0.1:6379/1", "OPTIONS": { "CLIENT_CLASS": "django_redis.client.DefaultClient", } }}上面的这段配置可以放在数据库 DATABASES 配置项的下方。LOCATION 配置项最后的数字1 是 DB number,指定redis的数据库号. ### 代码使用缓存 不是任何数据库的数据都应该使用缓存。应该符合如下两条规则:
- 频繁读取的数据。否则使用缓存,性能提升也不大
- 较少变动的数据。每次数据改变后,缓存都要重新读取。如果经常变动,反而会带来性能的下降。
假设,我们的 bysms系统中,药品数据是 频繁读取,且较少变动的。我们可以 在处理 列出药品 的API接口 的代码中,把 数据库读出的内容 进行 缓存。这里,我们采用上面的缓存方案二,把所有的 列出药品都放在一个哈希对象中。首先,我们需要为 列出药品的缓存 创建一个key,名字为 medicinelist。因为我们将来会有很多种类型的数据要缓存,它们有不同的key,所以建议统一放在配置文件 settings.py 中,如下
# 记录全局的缓存key,防止重复class CK: # 列出药品 的 缓存 key MedineList = 'list_medicine' # 列出客户 的 缓存 key CustomerList = 'list_customer'这样的好处是,放在一起,如果有重复的key名,比较容易发现 然后,在 mgr/medicine.py 文件开头处,进行如下修改
from django_redis import get_redis_connectionfrom bysms import settingsimport json# 获取一个和Redis服务的连接rconn = get_redis_connection("default")def listmedicine(request): try: # 查看是否有 关键字 搜索 参数 keywords = request.params.get('keywords',None) # 要获取的第几页 pagenum = request.params['pagenum'] # 每页要显示多少条记录 pagesize = request.params['pagesize'] # 先看看缓存中是否有 cacheField = f"{pagesize}|{pagenum}|{keywords}" # 缓存 field cacheObj = rconn.hget(settings.CK.MedineList, cacheField) # 缓存中有,需要反序列化 if cacheObj: print('缓存命中') retObj = json.loads(cacheObj) # 如果缓存中没有,再去数据库中查询 else: print('缓存中没有') # 返回一个 QuerySet 对象 ,包含所有的表记录 qs = Medicine.objects.values().order_by('-id') if keywords: conditions = [Q(name__contains=one) for one in keywords.split(' ') if one] query = Q() for condition in conditions: query &= condition qs = qs.filter(query) # 使用分页对象,设定每页多少条记录 pgnt = Paginator(qs, pagesize) # 从数据库中读取数据,指定读取其中第几页 page = pgnt.page(pagenum) # 将 QuerySet 对象 转化为 list 类型 retlist = list(page) retObj = {'ret': 0, 'retlist': retlist,'total': pgnt.count} # 存入缓存 rconn.hset(settings.CK.MedineList, cacheField, json.dumps(retObj)) # total指定了 一共有多少数据 return JsonResponse(retObj) except EmptyPage: return JsonResponse({'ret': 0, 'retlist': [], 'total': 0}) except: print(traceback.format_exc()) return JsonResponse({'ret': 2, 'msg': f'未知错误\n{traceback.format_exc()}'})这样,我们就确保了,处理列出药品的请求时,优先从缓存中读取,如果没有再从数据库读取。 并且数据库读取到数据后,存入缓存,这样下次同样的请求就可以从缓存中获取数据了。 ### 缓存数据更新 如果后面我们对药品数据做出了添加、修改、删除的操作,那么缓存里面的数据就很有可能和数据库里面的不一致。一旦数据被更改,就要相应的更新缓存。如果更新缓存特别麻烦,更简单的方法是:直接删除对应的缓存数据。这样下次请求,缓存中没有了数据,还是会从数据库读取,这样读取的就是最新数据,然后再缓存最新的数据。所以我们可以修改 添加、列出、删除药品的代码,如下
def addmedicine(request): info = request.params['data'] # 从请求消息中 获取要添加客户的信息 # 并且插入到数据库中 medicine = Medicine.objects.create(name=info['name'] , sn=info['sn'] , desc=info['desc']) # 同时删除整个 medicine 缓存数据 # 因为不知道这个添加的药品会影响到哪些列出的结果 # 只能全部删除 rconn.delete(settings.CK.MedineList) return JsonResponse({'ret': 0, 'id':medicine.id})def modifymedicine(request): # 从请求消息中 获取修改客户的信息 # 找到该客户,并且进行修改操作 medicineid = request.params['id'] newdata = request.params['newdata'] try: # 根据 id 从数据库中找到相应的客户记录 medicine = Medicine.objects.get(id=medicineid) except Medicine.DoesNotExist: return { 'ret': 1, 'msg': f'id 为`{medicineid}`的药品不存在' } if 'name' in newdata: medicine.name = newdata['name'] if 'sn' in newdata: medicine.sn = newdata['sn'] if 'desc' in newdata: medicine.desc = newdata['desc'] # 注意,一定要执行save才能将修改信息保存到数据库 medicine.save() # 同时删除整个 medicine 缓存数据 # 因为不知道这个修改的药品会影响到哪些列出的结果 # 只能全部删除 rconn.delete(settings.CK.MedineList) return JsonResponse({'ret': 0})def deletemedicine(request): medicineid = request.params['id'] try: # 根据 id 从数据库中找到相应的药品记录 medicine = Medicine.objects.get(id=medicineid) except Medicine.DoesNotExist: return { 'ret': 1, 'msg': f'id 为`{medicineid}`的客户不存在' } # delete 方法就将该记录从数据库中删除了 medicine.delete() # 同时删除整个 medicine 缓存数据 # 因为不知道这个删除的药品会影响到哪些列出的结果 # 只能全部删除 rconn.delete(settings.CK.MedineList) return JsonResponse({'ret': 0})