1Pandas
1. 安装
1-1 Pandas 安装
在开始使用Pandas之前,需要确保该库已正确安装。Pandas是一个用于数据操作和分析的强大工具,常与NumPy结合使用。以下是两种常用的安装方式:使用pip和conda。
1-1-1 使用pip安装
pip是Python的包管理工具,适用于在命令行中安装Python库。
步骤:
打开命令行界面:
- Windows: 可以使用
cmd或者PowerShell。 - macOS和Linux: 打开终端。
- Windows: 可以使用
检查pip是否已安装: 在命令行中输入以下命令来检查pip的版本。如果pip没有安装,可以参考相应的文档进行安装。
pip --version安装Pandas: 使用以下命令安装Pandas。可以使用
--upgrade参数来确保安装最新版本。pip install pandas或者,如果您需要更新到最新版本,可以使用:
pip install --upgrade pandas安装完成后验证: 安装完成后,可以在Python交互式命令行或脚本中验证安装是否成功:
import pandas as pd print(pd.__version__) # 输出Pandas的版本如果没有出现错误并且打印出版本号,则表示安装成功。
注意事项:
- 确保您的Python版本为3.6及以上,因为Pandas在此版本上才能正常工作。
- 在某些操作系统上,您可能需要使用
pip3来代替pip,以确保使用Python 3的包管理工具。 - 如果出现权限错误,可以尝试使用
sudo(在Linux和macOS上)或以管理员身份运行命令提示符(在Windows上)。
1-1-2 使用conda安装
conda是Anaconda的包管理器,适用于创建和管理Python环境以及安装软件包。
步骤:
打开Anaconda Prompt: 在Windows上,您可以搜索“Anaconda Prompt”,在macOS和Linux上使用终端。
创建一个新的虚拟环境(可选): 使用conda创建一个新的虚拟环境,可以避免与其他项目的包冲突:
conda create --name myenv python=3.8将
myenv替换为您想要的环境名称,您可以选择Python的版本。激活虚拟环境: 激活新创建的虚拟环境:
conda activate myenv安装Pandas: 在激活的环境中,使用以下命令安装Pandas:
conda install pandas安装完成后验证: 同样地,在Python交互式命令行中验证安装是否成功:
import pandas as pd print(pd.__version__) # 输出Pandas的版本
注意事项:
- 使用
conda时,您可以通过conda install pandas --update-deps来安装最新版本的Pandas并更新其依赖项。 - 创建和使用虚拟环境有助于管理不同项目的依赖,避免版本冲突。
2. 数据结构
2-1 Pandas 数据结构 - Series
Pandas中的Series是一个一维数组,能够存储任意类型的数据(整数、浮点数、字符串等),并且可以通过标签(索引)来访问这些数据。
2-1-1 创建Series
代码示例:
import pandas as pd
# 从列表创建Series
data_list = [1, 2, 3, 4, 5]
series_from_list = pd.Series(data_list)
print("从列表创建的Series:\n", series_from_list)
# 从字典创建Series
data_dict = {'a': 1, 'b': 2, 'c': 3}
series_from_dict = pd.Series(data_dict)
print("\n从字典创建的Series:\n", series_from_dict)
# 创建带有自定义索引的Series
custom_index_series = pd.Series(data_list, index=['one', 'two', 'three', 'four', 'five'])
print("\n带有自定义索引的Series:\n", custom_index_series)代码解释:
pd.Series(data_list)从列表创建Series。pd.Series(data_dict)从字典创建Series,字典的键成为索引。- 可以自定义Series的索引。
2-1-2 访问Series元素
代码示例:
# 访问单个元素
print("访问第一个元素:", series_from_list[0]) # 按位置访问
print("访问索引为'b'的元素:", series_from_dict['b']) # 按标签访问
# 访问多个元素
print("\n访问前两个元素:\n", series_from_list[:2]) # 切片
print("\n访问自定义索引:\n", custom_index_series[['one', 'three']]) # 按索引列表访问代码解释:
- 使用索引位置和标签访问Series中的元素。
- 切片和按索引列表访问也可以获取多个元素。
2-1-3 Series的属性和方法
代码示例:
# Series属性
print("\nSeries的长度:", len(series_from_list)) # 获取Series的长度
print("Series的索引:\n", series_from_list.index) # 获取索引
print("Series的值:\n", series_from_list.values) # 获取值
# 常用方法
print("\nSeries的最大值:", series_from_list.max()) # 最大值
print("Series的最小值:", series_from_list.min()) # 最小值
print("Series的和:", series_from_list.sum()) # 求和
print("Series的均值:", series_from_list.mean()) # 均值代码解释:
len()、index、values获取Series的基本信息。- 使用
max()、min()、sum()、mean()等方法进行统计计算。
2-2 Pandas 数据结构 - DataFrame
DataFrame是一个二维表格,类似于电子表格或数据库表,具有行和列。
2-2-1 创建DataFrame
代码示例:
# 从字典创建DataFrame
data_dict = {
'Name': ['Alice', 'Bob', 'Charlie'],
'Age': [25, 30, 35],
'City': ['New York', 'Los Angeles', 'Chicago']
}
df_from_dict = pd.DataFrame(data_dict)
print("从字典创建的DataFrame:\n", df_from_dict)
# 从二维数组创建DataFrame
data_array = np.array([[1, 'Alice', 25], [2, 'Bob', 30], [3, 'Charlie', 35]])
df_from_array = pd.DataFrame(data_array, columns=['ID', 'Name', 'Age'])
print("\n从数组创建的DataFrame:\n", df_from_array)代码解释:
- 从字典和二维数组创建DataFrame,指定列名。
2-2-2 访问DataFrame元素
代码示例:
# 访问单个元素
print("访问第一行第二列元素:", df_from_dict.iloc[0, 1]) # 按位置
print("访问第二行的'Name'列:", df_from_dict.loc[1, 'Name']) # 按标签
# 访问整行和整列
print("\n访问第二行:\n", df_from_dict.iloc[1]) # 整行
print("\n访问'City'列:\n", df_from_dict['City']) # 整列代码解释:
- 使用
iloc按位置访问,使用loc按标签访问特定元素、行或列。
2-2-3 DataFrame的属性和方法
代码示例:
# DataFrame属性
print("\nDataFrame的形状:", df_from_dict.shape) # 行列数
print("DataFrame的列名:", df_from_dict.columns) # 列名
print("DataFrame的索引:\n", df_from_dict.index) # 索引
# 常用方法
print("\nDataFrame的描述性统计:\n", df_from_dict.describe()) # 描述性统计
print("DataFrame的头五行:\n", df_from_dict.head()) # 查看前五行
print("DataFrame的尾五行:\n", df_from_dict.tail()) # 查看最后五行代码解释:
shape、columns、index属性获取DataFrame的基本信息。- 使用
describe()、head()、tail()等方法进行统计和数据预览。
2-2-4 读取DataFrame(CSV、Excel、JSON等)
代码示例:
# 读取CSV文件
df_csv = pd.read_csv('data.csv') # 请确保在当前目录下存在data.csv文件
print("\n从CSV文件读取的DataFrame:\n", df_csv)
# 读取Excel文件
df_excel = pd.read_excel('data.xlsx') # 请确保在当前目录下存在data.xlsx文件
print("\n从Excel文件读取的DataFrame:\n", df_excel)
# 读取JSON文件
df_json = pd.read_json('data.json') # 请确保在当前目录下存在data.json文件
print("\n从JSON文件读取的DataFrame:\n", df_json)代码解释:
- 使用
pd.read_csv()、pd.read_excel()和pd.read_json()从不同格式的文件读取DataFrame。 - 确保提供的文件路径正确。
综合练习
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
# 1. 创建Series
data_list = [1, 2, 3, 4, 5]
series_from_list = pd.Series(data_list)
data_dict = {'a': 1, 'b': 2, 'c': 3}
series_from_dict = pd.Series(data_dict)
# 2. 访问Series元素
first_element = series_from_list[0]
second_element = series_from_dict['b']
# 3. Series属性和方法
series_length = len(series_from_list)
series_max = series_from_list.max()
# 4. 创建DataFrame
data_dict_df = {
'Name': ['Alice', 'Bob', 'Charlie'],
'Age': [25, 30, 35],
'City': ['New York', 'Los Angeles', 'Chicago']
}
df_from_dict = pd.DataFrame(data_dict_df)
# 5. 访问DataFrame元素
first_row = df_from_dict.iloc[0]
city_column = df_from_dict['City']
# 6. DataFrame属性和方法
df_shape = df_from_dict.shape
df_description = df_from_dict.describe()
# 7. 读取数据(需要在当前目录下准备相应文件)
# df_csv = pd.read_csv('data.csv')
# df_excel = pd.read_excel('data.xlsx')
# df_json = pd.read_json('data.json')
# 打印结果
print("从列表创建的Series:\n", series_from_list)
print("访问Series元素(第二个元素):", second_element)
print("Series的最大值:", series_max)
print("\n从字典创建的DataFrame:\n", df_from_dict)
print("访问DataFrame的第一行:\n", first_row)
print("DataFrame的描述性统计:\n", df_description)3. 数据输入与输出
3-1 读取CSV文件
代码示例:
import pandas as pd
# 从CSV文件读取数据
df_csv = pd.read_csv('data.csv') # 读取整个CSV文件
print("读取的CSV数据:\n", df_csv)
# 逐行读取CSV文件
with open('data.csv', 'r') as file:
for line in file:
print("逐行读取的CSV数据:", line.strip()) # 去掉每行末尾的换行符代码解释:
pd.read_csv('data.csv')一次性读取整个CSV文件并返回DataFrame。- 使用标准的文件操作逐行读取CSV文件,适合处理较大文件时逐行解析。
3-2 写入CSV文件
代码示例:
# 将DataFrame写入CSV文件
df_csv.to_csv('output.csv', index=False) # index=False表示不写入行索引
print("数据已写入output.csv")
# 逐行写入CSV文件
with open('output_row_by_row.csv', 'w') as file:
for index, row in df_csv.iterrows(): # 使用iterrows逐行遍历DataFrame
file.write(','.join(map(str, row.values)) + '\n') # 将每行数据转换为字符串并写入代码解释:
df_csv.to_csv('output.csv', index=False)将整个DataFrame写入CSV文件。- 使用
iterrows()逐行遍历DataFrame,手动写入每一行数据,适合按需处理。
3-3 读取Excel文件
代码示例:
# 从Excel文件读取数据
df_excel = pd.read_excel('data.xlsx', sheet_name='Sheet1') # 指定读取的工作表
print("读取的Excel数据:\n", df_excel)
# 逐行读取Excel文件
for index, row in df_excel.iterrows():
print(f"逐行读取的Excel数据: {row['Column1']}, {row['Column2']}") # 替换为实际列名代码解释:
pd.read_excel('data.xlsx', sheet_name='Sheet1')读取指定工作表的内容。- 使用
iterrows()逐行遍历DataFrame,适合处理具体的行数据。
3-4 写入Excel文件
代码示例:
# 将DataFrame写入Excel文件
df_excel.to_excel('output.xlsx', index=False, sheet_name='Results') # 指定工作表名称
print("数据已写入output.xlsx")
# 逐行写入Excel文件
with pd.ExcelWriter('output_row_by_row.xlsx', engine='openpyxl') as writer:
for index, row in df_excel.iterrows():
row_df = pd.DataFrame([row]) # 将单行转换为DataFrame
row_df.to_excel(writer, index=False, header=writer.sheets['Results'].max_row == 0) # 如果是第一行则写入列名代码解释:
df_excel.to_excel('output.xlsx', index=False)将整个DataFrame写入Excel文件。- 使用
ExcelWriter逐行写入Excel文件,动态生成DataFrame适合进行写入。
3-5 读取JSON文件
代码示例:
# 从JSON文件读取数据
df_json = pd.read_json('data.json') # 假设data.json文件在当前目录下
print("读取的JSON数据:\n", df_json)
# 逐行读取JSON数据
import json
with open('data.json', 'r') as file:
json_data = json.load(file) # 加载整个JSON文件
for record in json_data: # 假设每个记录是一个字典
print("逐行读取的JSON数据:", record)代码解释:
pd.read_json('data.json')读取JSON文件并返回DataFrame。- 使用标准JSON库逐行解析,适合处理JSON格式复杂的文件。
3-6 写入JSON文件
代码示例:
# 将DataFrame写入JSON文件
df_json.to_json('output.json', orient='records', lines=True) # orient='records'每行作为一个记录
print("数据已写入output.json")
# 逐行写入JSON文件
with open('output_row_by_row.json', 'w') as file:
for index, row in df_json.iterrows():
json_record = row.to_dict() # 将行转换为字典
file.write(json.dumps(json_record) + '\n') # 将字典写入JSON文件代码解释:
df_json.to_json('output.json', orient='records', lines=True)将DataFrame保存为JSON文件。- 使用
iterrows()逐行遍历DataFrame,将每行数据转换为字典格式并写入文件。
3-7 从数据库读取数据
代码示例:
import sqlite3
# 连接到SQLite数据库(如果数据库文件不存在,会自动创建)
conn = sqlite3.connect('example.db') # 假设数据库文件为example.db
# 从数据库读取数据
df_sql = pd.read_sql_query("SELECT * FROM tablename", conn) # 替换tablename为您的表名
print("从数据库读取的数据:\n", df_sql)
# 逐行读取数据库数据
for index, row in df_sql.iterrows():
print(f"逐行读取的数据库数据: {row['column_name']}") # 替换column_name为您的列名
# 关闭数据库连接
conn.close()代码解释:
- 使用
sqlite3库连接到SQLite数据库,并执行SQL查询以读取数据。 - 使用
iterrows()逐行访问DataFrame,适合逐条处理。
3-8 将数据写入数据库
代码示例:
# 将DataFrame写入SQLite数据库
conn = sqlite3.connect('example.db') # 连接到数据库
# 将DataFrame写入指定表(如果表不存在,会自动创建)
df_sql.to_sql('tablename', conn, if_exists='replace', index=False) # 替换tablename为您的表名
print("数据已写入数据库的tablename表")
# 逐行写入数据库
for index, row in df_sql.iterrows():
row.to_frame().T.to_sql('tablename', conn, if_exists='append', index=False) # 逐行插入
# row.to_frame().T将Series转换为DataFrame并插入数据库
# 关闭数据库连接
conn.close()代码解释:
- 使用
to_sql()将整个DataFrame写入SQLite数据库。 - 逐行写入数据库的方式是将Series转换为DataFrame后插入。
综合练习
import pandas as pd
import numpy as np
import sqlite3
import json
# 1. 读取CSV文件
df_csv = pd.read_csv('data.csv') # 确保文件存在
print("读取的CSV数据:\n", df_csv)
# 2. 逐行读取CSV文件
with open('data.csv', 'r') as file:
for line in file:
print("逐行读取的CSV数据:", line.strip())
# 3. 写入CSV文件
df_csv.to_csv('output.csv', index=False) # 不写入行索引
print("数据已写入output.csv")
# 4. 逐行写入CSV文件
with open('output_row_by_row.csv', 'w') as file:
for index, row in df_csv.iterrows():
file.write(','.join(map(str, row.values)) + '\n')
# 5. 读取Excel文件
df_excel = pd.read_excel('data.xlsx') # 确保文件存在
print("读取的Excel数据:\n", df_excel)
# 6. 逐行读取Excel文件
for index, row in df_excel.iterrows():
print(f"逐行读取的Excel数据: {row['Column1']}, {row['Column2']}") # 替换为实际列名
# 7. 写入Excel文件
df_excel.to_excel('output.xlsx', index=False) # 不写入行索引
print("数据已写入output.xlsx")
# 8. 读取JSON文件
df_json = pd.read_json('data.json') # 确保文件存在
print("读取的JSON数据:\n", df_json)
# 9. 逐行读取JSON数据
with open('data.json', 'r') as file:
json_data = json.load(file)
for record in json_data:
print("逐行读取的JSON数据:", record)
# 10. 写入JSON文件
df_json.to_json('output.json', orient='records', lines=True)
print("数据已写入output.json")4. 数据清洗
4-1 数据清洗概述
数据清洗是数据分析过程中的关键步骤,主要用于确保数据的质量,以便于后续分析。数据清洗的任务包括处理缺失值、去除重复数据、修正错误、标准化数据格式等。
4-2 处理缺失值
缺失值是指数据集中缺少某些数据点,处理缺失值的方式有多种,包括检查、填充和删除等。
4-2-1 检查缺失值
代码示例:
import pandas as pd
# 创建示例数据
data = {'A': [1, 2, None, 4],
'B': [None, 2, 3, 4],
'C': [1, None, None, 4]}
df = pd.DataFrame(data)
# 检查缺失值
missing_values = df.isnull() # 返回一个布尔DataFrame,指示缺失值的位置
print("缺失值检查:\n", missing_values)
# 统计缺失值的总数
total_missing = df.isnull().sum() # 统计每列缺失值的数量
print("\n每列缺失值的数量:\n", total_missing)代码解释:
df.isnull()返回一个布尔DataFrame,缺失值的位置为True。- 使用
sum()函数统计每列的缺失值数量。
4-2-2 填充缺失值
代码示例:
# 用均值填充缺失值
df_filled_mean = df.fillna(df.mean()) # 对数值列使用均值填充
print("\n用均值填充缺失值后的数据:\n", df_filled_mean)
# 用特定值填充缺失值
df_filled_value = df.fillna(0) # 将所有缺失值填充为0
print("\n用0填充缺失值后的数据:\n", df_filled_value)代码解释:
df.fillna(df.mean())对每列使用均值填充缺失值。df.fillna(0)将所有缺失值填充为0。
4-2-3 删除缺失值
代码示例:
# 删除包含缺失值的行
df_dropped_rows = df.dropna() # 删除任何包含缺失值的行
print("\n删除包含缺失值的行后的数据:\n", df_dropped_rows)
# 删除特定列中的缺失值
df_dropped_specific = df.dropna(subset=['A']) # 仅删除'A'列中包含缺失值的行
print("\n删除'A'列中缺失值后的数据:\n", df_dropped_specific)代码解释:
df.dropna()删除任何包含缺失值的行。dropna(subset=['A'])仅对'A'列进行缺失值检查,删除相关行。
4-3 清洗空值
空值与缺失值类似,但在数据中表示为特定的空字符串或空数据。可以使用replace()方法来处理。
代码示例:
# 替换空值
df_cleaned_empty = df.replace('', None) # 将空字符串替换为None
print("\n将空字符串替换为None后的数据:\n", df_cleaned_empty)代码解释:
df.replace('', None)将DataFrame中的空字符串替换为None,后续可以对这些值进行缺失值处理。
4-4 数据格式转换
数据格式转换是将数据转换为适合分析的格式的过程,常见的转换包括数据类型的转换和字符串到日期的转换。
4-4-1 转换数据类型
代码示例:
# 创建示例数据
data = {'A': ['1', '2', '3', '4'],
'B': ['5.5', '6.1', '7.3', '8.2']}
df_types = pd.DataFrame(data)
# 转换数据类型
df_types['A'] = df_types['A'].astype(int) # 将'A'列转换为整数
df_types['B'] = df_types['B'].astype(float) # 将'B'列转换为浮点数
print("\n转换数据类型后的数据:\n", df_types)代码解释:
astype(int)将'A'列的数据转换为整数。astype(float)将'B'列的数据转换为浮点数。
4-4-2 字符串到日期转换
代码示例:
# 创建示例数据
data_dates = {'date_str': ['2021-01-01', '2021-02-01', '2021-03-01']}
df_dates = pd.DataFrame(data_dates)
# 转换为日期格式
df_dates['date'] = pd.to_datetime(df_dates['date_str']) # 转换为日期时间格式
print("\n字符串转换为日期后的数据:\n", df_dates)代码解释:
pd.to_datetime(df_dates['date_str'])将字符串格式的日期转换为Pandas的日期时间格式。
4-5 数据去重
去重是确保数据集中每条记录都是唯一的,Pandas提供了方便的方法来删除重复数据。
代码示例:
# 创建示例数据
data_duplicates = {'A': [1, 1, 2, 3, 4],
'B': ['a', 'a', 'b', 'c', 'd']}
df_duplicates = pd.DataFrame(data_duplicates)
# 删除重复行
df_unique = df_duplicates.drop_duplicates() # 默认保留第一条出现的记录
print("\n去重后的数据:\n", df_unique)代码解释:
drop_duplicates()方法删除重复行,保留第一次出现的记录。
4-6 处理异常值
异常值是指显著偏离正常数据分布的值。识别和处理异常值是数据清洗的重要部分。
4-6-1 识别异常值
代码示例:
# 创建示例数据
data_outliers = {'A': [10, 12, 13, 100, 15]}
df_outliers = pd.DataFrame(data_outliers)
# 使用描述性统计识别异常值
mean = df_outliers['A'].mean()
std = df_outliers['A'].std()
# 设置阈值
threshold = 3
df_outliers['is_outlier'] = np.abs(df_outliers['A'] - mean) > (threshold * std)
print("\n识别的异常值:\n", df_outliers)代码解释:
- 计算列的均值和标准差,使用阈值(通常为3倍标准差)来识别异常值。
4-6-2 处理异常值的方法
代码示例:
# 处理异常值
df_cleaned_outliers = df_outliers[~df_outliers['is_outlier']] # 删除异常值
print("\n处理后的数据(已删除异常值):\n", df_cleaned_outliers)代码解释:
~df_outliers['is_outlier']选择不是异常值的行,删除异常值后返回的清洗数据。
综合练习
import pandas as pd
import numpy as np
# 1. 创建示例数据
data = {
'A': [1, 2, None, 4],
'B': [None, 2, 3, 4],
'C': [1, None, None, 4]
}
df = pd.DataFrame(data)
# 2. 检查缺失值
missing_values = df.isnull().sum() # 统计每列缺失值的数量
print("每列缺失值的数量:\n", missing_values)
# 3. 填充缺失值
df_filled = df.fillna(df.mean()) # 用均值填充缺失值
print("\n填充缺失值后的数据:\n", df_filled)
# 4. 删除缺失值
df_dropped = df.dropna() # 删除任何包含缺失值的行
print("\n删除缺失值后的数据:\n", df_dropped)
# 5. 替换空值
df_cleaned_empty = df.replace('', None) # 将空字符串替换为None
print("\n将空字符串替换为None后的数据:\n", df_cleaned_empty)
# 6. 转换数据类型
data_types = {'A': ['1', '2', '3', '4'], 'B': ['5.5', '6.1', '7.3', '8.2']}
df_types = pd.DataFrame(data_types)
# 转换数据类型
df_types['A'] = df_types['A'].astype(int) # 将'A'列转换为整数
df_types['B'] = df_types['B'].astype(float) # 将'B'列转换为浮点数
print("\n转换数据类型后的数据:\n", df_types)
# 7. 字符串到日期转换
data_dates = {'date_str': ['2021-01-01', '2021-02-01', '2021-03-01']}
df_dates = pd.DataFrame(data_dates)
# 转换为日期格式
df_dates['date'] = pd.to_datetime(df_dates['date_str']) # 转换为日期时间格式
print("\n字符串转换为日期后的数据:\n", df_dates)
# 8. 数据去重
data_duplicates = {'A': [1, 1, 2, 3, 4], 'B': ['a', 'a', 'b', 'c', 'd']}
df_duplicates = pd.DataFrame(data_duplicates)
# 删除重复行
df_unique = df_duplicates.drop_duplicates() # 默认保留第一条出现的记录
print("\n去重后的数据:\n", df_unique)
# 9. 处理异常值
data_outliers = {'A': [10, 12, 13, 100, 15]}
df_outliers = pd.DataFrame(data_outliers)
# 使用描述性统计识别异常值
mean = df_outliers['A'].mean()
std = df_outliers['A'].std()
# 设置阈值
threshold = 3
df_outliers['is_outlier'] = np.abs(df_outliers['A'] - mean) > (threshold * std)
print("\n识别的异常值:\n", df_outliers)
# 处理异常值
df_cleaned_outliers = df_outliers[~df_outliers['is_outlier']] # 删除异常值
print("\n处理后的数据(已删除异常值):\n", df_cleaned_outliers)代码总结
- 创建示例数据: 创建一个包含缺失值的DataFrame。
- 检查缺失值: 使用
isnull()方法统计每列的缺失值数量。 - 填充缺失值: 使用
fillna()方法用均值填充缺失值。 - 删除缺失值: 使用
dropna()方法删除包含缺失值的行。 - 替换空值: 使用
replace()方法将空字符串替换为None。 - 转换数据类型: 使用
astype()方法转换数据列的类型。 - 字符串到日期转换: 使用
pd.to_datetime()将字符串转换为日期格式。 - 数据去重: 使用
drop_duplicates()方法删除重复行。 - 处理异常值: 通过描述性统计识别异常值,并基于设定阈值进行处理。
5. 数据操作
5-1 数据选择与过滤
数据选择与过滤是处理数据时的基本操作,可以根据标签、位置或条件来选择数据。
5-1-1 按标签选择
代码示例:
import pandas as pd
# 创建示例DataFrame
data = {
'Name': ['Alice', 'Bob', 'Charlie', 'David'],
'Age': [25, 30, 35, 40],
'City': ['New York', 'Los Angeles', 'Chicago', 'Houston']
}
df = pd.DataFrame(data)
# 按标签选择单列
age_series = df['Age'] # 使用列名选择
print("选择的年龄列:\n", age_series)
# 按标签选择多列
name_age_df = df[['Name', 'Age']] # 使用列名列表选择
print("\n选择的姓名和年龄列:\n", name_age_df)
# 按行标签选择
row_bob = df.loc[1] # 使用行索引选择
print("\n选择的Bob行数据:\n", row_bob)
# 按行标签和列标签选择
row_age = df.loc[1, 'Age'] # 选择Bob的年龄
print("\n选择的Bob的年龄:", row_age)代码解释:
- 使用
df['Age']按列标签选择单列数据。 - 使用
df[['Name', 'Age']]选择多列数据。 loc[]用于按标签访问特定的行和列。
5-1-2 按位置选择
代码示例:
# 按位置选择单个元素
first_row_first_col = df.iat[0, 0] # 选择第一行第一列的元素
print("\n第一行第一列的元素:", first_row_first_col)
# 按位置选择多行多列
subset = df.iloc[0:2, 1:3] # 选择第一到第二行和第二到第三列
print("\n选择的子集数据:\n", subset)代码解释:
iat[]用于选择特定位置的单个元素,基于行列索引。iloc[]用于选择多行多列,使用整数索引。
5-1-3 布尔索引
代码示例:
# 创建一个布尔条件
condition = df['Age'] > 30 # 年龄大于30的条件
# 使用布尔索引选择数据
filtered_df = df[condition] # 选择符合条件的行
print("\n年龄大于30的人员:\n", filtered_df)
# 结合多个条件
filtered_multiple = df[(df['Age'] > 30) & (df['City'] == 'Chicago')]
print("\n年龄大于30且城市为Chicago的人员:\n", filtered_multiple)代码解释:
- 创建布尔条件并使用其作为索引选择符合条件的行。
- 使用逻辑运算符结合多个条件。
5-2 数据排序
排序是将数据按指定列的值进行排列的操作。
5-2-1 按列排序
代码示例:
# 按年龄列排序
sorted_by_age = df.sort_values(by='Age') # 默认升序排序
print("\n按年龄排序后的数据:\n", sorted_by_age)
# 按年龄列降序排序
sorted_by_age_desc = df.sort_values(by='Age', ascending=False) # 设置ascending=False进行降序排序
print("\n按年龄降序排序后的数据:\n", sorted_by_age_desc)代码解释:
sort_values(by='Age')按年龄列进行升序排序。- 使用
ascending=False进行降序排序。
5-2-2 按多列排序
代码示例:
# 按城市和年龄进行排序
sorted_by_city_age = df.sort_values(by=['City', 'Age']) # 按城市升序,再按年龄升序
print("\n按城市和年龄排序后的数据:\n", sorted_by_city_age)代码解释:
sort_values(by=['City', 'Age'])先按城市排序,再按年龄排序。
5-3 数据分组与聚合
数据分组与聚合是对数据进行分组并进行汇总分析的操作。
5-3-1 groupby 操作
代码示例:
# 创建示例数据
data_group = {
'Name': ['Alice', 'Bob', 'Charlie', 'David', 'Eve'],
'Age': [25, 30, 35, 25, 30],
'City': ['New York', 'Los Angeles', 'Chicago', 'New York', 'Chicago']
}
df_group = pd.DataFrame(data_group)
# 使用groupby进行分组
grouped = df_group.groupby('City') # 按城市分组
print("\n按城市分组后:\n", grouped.groups) # 查看每个组的索引代码解释:
groupby('City')根据城市将数据分组,返回一个分组对象。
5-3-2 聚合函数
代码示例:
# 对分组数据进行聚合操作
age_mean = grouped['Age'].mean() # 计算每个城市的平均年龄
print("\n每个城市的平均年龄:\n", age_mean)
# 进行多个聚合操作
agg_results = grouped.agg({
'Age': ['mean', 'max'], # 计算平均年龄和最大年龄
'Name': 'count' # 统计每个城市的人数
})
print("\n每个城市的聚合结果:\n", agg_results)代码解释:
mean()计算每个城市的平均年龄。agg()可以同时进行多个聚合操作。
5-3-3 多重聚合
代码示例:
# 多重聚合示例
multiple_agg = df_group.groupby('Age').agg({
'City': pd.Series.nunique, # 计算不同城市的数量
'Name': 'count' # 统计每个年龄段的人数
})
print("\n按年龄的多重聚合结果:\n", multiple_agg)代码解释:
- 使用
agg()结合nunique和count对不同年龄段的数据进行统计。
综合练习
以下是前面所有代码的综合练习部分,便于整体理解和使用。
import pandas as pd
import numpy as np
# 创建示例DataFrame
data = {
'Name': ['Alice', 'Bob', 'Charlie', 'David'],
'Age': [25, 30, 35, 40],
'City': ['New York', 'Los Angeles', 'Chicago', 'Houston']
}
df = pd.DataFrame(data)
# 1. 按标签选择
age_series = df['Age']
name_age_df = df[['Name', 'Age']]
print("选择的姓名和年龄列:\n", name_age_df)
# 2. 按位置选择
first_row_first_col = df.iat[0, 0]
print("\n第一行第一列的元素:", first_row_first_col)
# 3. 布尔索引
filtered_df = df[df['Age'] > 30]
print("\n年龄大于30的人员:\n", filtered_df)
# 4. 数据排序
sorted_by_age = df.sort_values(by='Age', ascending=True)
print("\n按年龄排序后的数据:\n", sorted_by_age)
# 5. 数据分组与聚合
grouped = df.groupby('City')
age_mean = grouped['Age'].mean()
print("\n每个城市的平均年龄:\n", age_mean)
# 6. 多重聚合
data_group = {
'Name': ['Alice', 'Bob', 'Charlie', 'David', 'Eve'],
'Age': [25, 30, 35, 25, 30],
'City': ['New York', 'Los Angeles', 'Chicago', 'New York', 'Chicago']
}
df_group = pd.DataFrame(data_group)
multiple_agg = df_group.groupby('Age').agg({
'City': pd.Series.nunique,
'Name': 'count'
})
print("\n按年龄的多重聚合结果:\n", multiple_agg)5-4 数据合并与连接
数据合并与连接是将多个DataFrame合并为一个的过程,可以通过不同的方式实现,如基于特定列的合并、垂直或水平拼接等。
5-4-1 merge 函数
merge函数用于根据一个或多个键(列)合并两个DataFrame。它类似于SQL中的JOIN操作。
代码示例:
import pandas as pd
# 创建示例数据
df1 = pd.DataFrame({
'EmployeeID': [1, 2, 3, 4],
'Name': ['Alice', 'Bob', 'Charlie', 'David']
})
df2 = pd.DataFrame({
'EmployeeID': [3, 4, 5, 6],
'Salary': [70000, 80000, 60000, 75000]
})
# 使用merge函数进行合并
merged_df = pd.merge(df1, df2, on='EmployeeID', how='inner') # 内连接
print("内连接的合并结果:\n", merged_df)
# 使用左连接
left_merged_df = pd.merge(df1, df2, on='EmployeeID', how='left') # 左连接
print("\n左连接的合并结果:\n", left_merged_df)
# 使用右连接
right_merged_df = pd.merge(df1, df2, on='EmployeeID', how='right') # 右连接
print("\n右连接的合并结果:\n", right_merged_df)
# 使用外连接
outer_merged_df = pd.merge(df1, df2, on='EmployeeID', how='outer') # 外连接
print("\n外连接的合并结果:\n", outer_merged_df)代码解释:
pd.merge()函数合并两个DataFrame,可以指定连接的键(on参数)。how参数指定连接的类型:inner(默认)、left、right、outer。
5-4-2 concat 函数
concat函数用于沿指定轴将多个DataFrame连接在一起,适合用于拼接行或列。
代码示例:
# 创建示例数据
df3 = pd.DataFrame({
'Name': ['Alice', 'Bob'],
'Age': [25, 30]
})
df4 = pd.DataFrame({
'Name': ['Charlie', 'David'],
'Age': [35, 40]
})
# 垂直拼接(沿行拼接)
concatenated_df = pd.concat([df3, df4], axis=0, ignore_index=True) # ignore_index=True重新索引
print("\n垂直拼接后的数据:\n", concatenated_df)
# 水平拼接(沿列拼接)
df5 = pd.DataFrame({
'Salary': [70000, 80000]
})
horizontal_concatenated_df = pd.concat([df3, df5], axis=1) # 沿列拼接
print("\n水平拼接后的数据:\n", horizontal_concatenated_df)代码解释:
pd.concat()函数用于拼接多个DataFrame,axis=0表示沿行拼接,axis=1表示沿列拼接。ignore_index=True参数可以重新索引,避免重复索引。
5-4-3 join 函数
join函数用于连接DataFrame,通常用于基于索引进行连接。
代码示例:
# 创建示例数据
df6 = pd.DataFrame({
'EmployeeID': [1, 2, 3],
'Department': ['HR', 'Finance', 'IT']
}).set_index('EmployeeID') # 将'EmployeeID'设置为索引
df7 = pd.DataFrame({
'EmployeeID': [1, 2, 4],
'Salary': [70000, 80000, 60000]
}).set_index('EmployeeID') # 将'EmployeeID'设置为索引
# 使用join函数进行连接
joined_df = df6.join(df7, how='inner') # 默认内连接
print("\n使用join进行内连接的结果:\n", joined_df)
# 使用左连接
left_joined_df = df6.join(df7, how='left') # 左连接
print("\n使用join进行左连接的结果:\n", left_joined_df)
# 使用右连接
right_joined_df = df6.join(df7, how='right') # 右连接
print("\n使用join进行右连接的结果:\n", right_joined_df)
# 使用外连接
outer_joined_df = df6.join(df7, how='outer') # 外连接
print("\n使用join进行外连接的结果:\n", outer_joined_df)代码解释:
join()函数根据索引合并两个DataFrame。- 可以使用
how参数来指定连接方式(inner、left、right、outer)。
综合练习
以下是前面所有代码的综合练习部分,便于整体理解和使用。
import pandas as pd
# 1. 创建示例数据
df1 = pd.DataFrame({
'EmployeeID': [1, 2, 3, 4],
'Name': ['Alice', 'Bob', 'Charlie', 'David']
})
df2 = pd.DataFrame({
'EmployeeID': [3, 4, 5, 6],
'Salary': [70000, 80000, 60000, 75000]
})
# 2. merge 函数
merged_df = pd.merge(df1, df2, on='EmployeeID', how='inner') # 内连接
print("内连接的合并结果:\n", merged_df)
# 3. concat 函数
df3 = pd.DataFrame({
'Name': ['Alice', 'Bob'],
'Age': [25, 30]
})
df4 = pd.DataFrame({
'Name': ['Charlie', 'David'],
'Age': [35, 40]
})
concatenated_df = pd.concat([df3, df4], axis=0, ignore_index=True) # 垂直拼接
print("\n垂直拼接后的数据:\n", concatenated_df)
# 4. join 函数
df5 = pd.DataFrame({
'EmployeeID': [1, 2, 3],
'Department': ['HR', 'Finance', 'IT']
}).set_index('EmployeeID')
df6 = pd.DataFrame({
'EmployeeID': [1, 2, 4],
'Salary': [70000, 80000, 60000]
}).set_index('EmployeeID')
joined_df = df5.join(df6, how='inner') # 内连接
print("\n使用join进行内连接的结果:\n", joined_df)6. 数据分析
6-1 描述性统计
描述性统计用于总结和描述数据集的基本特征。
6-1-1 计算均值、中位数、方差
代码示例:
import pandas as pd
# 创建示例数据
data = {
'A': [1, 2, 3, 4, 5],
'B': [5, 6, 7, 8, 9]
}
df = pd.DataFrame(data)
# 计算均值
mean_A = df['A'].mean()
mean_B = df['B'].mean()
print("均值:\n", {'A': mean_A, 'B': mean_B})
# 计算中位数
median_A = df['A'].median()
median_B = df['B'].median()
print("\n中位数:\n", {'A': median_A, 'B': median_B})
# 计算方差
variance_A = df['A'].var()
variance_B = df['B'].var()
print("\n方差:\n", {'A': variance_A, 'B': variance_B})代码解释:
mean()计算均值,median()计算中位数,var()计算方差,结果以字典形式输出。
6-1-2 数据的分位数
代码示例:
# 计算分位数
quantiles_A = df['A'].quantile([0.25, 0.5, 0.75]) # 计算25%、50%、75%分位数
print("\n分位数:\n", quantiles_A)代码解释:
quantile()方法用于计算特定分位数,结果显示为Series。
6-2 相关性分析
相关性分析用于评估两个或多个变量之间的关系。
6-2-1 计算相关系数
代码示例:
# 计算相关系数
correlation_A_B = df['A'].corr(df['B']) # 计算A与B的相关系数
print("\nA与B的相关系数:", correlation_A_B)代码解释:
corr()方法用于计算两个Series之间的相关系数,结果为标量。
6-2-2 生成相关性矩阵
代码示例:
# 生成相关性矩阵
correlation_matrix = df.corr() # 计算DataFrame中所有列之间的相关系数
print("\n相关性矩阵:\n", correlation_matrix)代码解释:
corr()方法用于生成整个DataFrame的相关性矩阵,结果为一个DataFrame,显示所有列之间的相关性。
6-3 数据透视表
数据透视表用于对数据进行汇总和分组,以便进行多维分析。
6-3-1 创建数据透视表
代码示例:
# 创建示例数据
data_pivot = {
'Name': ['Alice', 'Bob', 'Charlie', 'David', 'Eve', 'Frank'],
'City': ['New York', 'New York', 'Chicago', 'Chicago', 'Los Angeles', 'Los Angeles'],
'Sales': [100, 150, 200, 300, 250, 400]
}
df_pivot = pd.DataFrame(data_pivot)
# 创建数据透视表
pivot_table = df_pivot.pivot_table(values='Sales', index='City', aggfunc='sum') # 按城市汇总销售额
print("\n数据透视表:\n", pivot_table)代码解释:
pivot_table()方法用于创建数据透视表,values参数指定需要汇总的列,index参数指定分组依据,aggfunc指定汇总函数(如求和)。
6-3-2 数据透视表的聚合操作
代码示例:
# 创建更复杂的数据透视表,进行多重聚合
pivot_table_multiple = df_pivot.pivot_table(values='Sales', index='City', columns='Name', aggfunc='sum', fill_value=0) # 将缺失值填充为0
print("\n多重聚合的数据透视表:\n", pivot_table_multiple)代码解释:
columns参数用于指定数据透视表中要按列分组的字段。fill_value=0用于将缺失值填充为0。
6-4 时间序列分析
时间序列分析用于处理随时间变化的数据,能够帮助我们识别趋势和季节性变化。
6-4-1 时间序列的创建与索引
代码示例:
# 创建时间序列
date_range = pd.date_range(start='2021-01-01', periods=5, freq='D') # 创建日期范围
data_time_series = [1, 3, 5, 7, 9]
df_time_series = pd.DataFrame(data_time_series, index=date_range, columns=['Value'])
print("\n创建的时间序列数据:\n", df_time_series)代码解释:
- 使用
pd.date_range()生成一个日期范围,将其作为DataFrame的索引。
6-4-2 时间序列的重采样
代码示例:
# 重采样
df_resampled = df_time_series.resample('2D').sum() # 每两天汇总
print("\n重采样后的时间序列数据:\n", df_resampled)代码解释:
- 使用
resample()方法对时间序列进行重采样,'2D'表示每两天。
6-4-3 时间序列的趋势分析
代码示例:
import matplotlib
matplotlib.use('TkAgg') # 或 'Qt5Agg'
import matplotlib.pyplot as plt
# 绘制时间序列数据
plt.figure(figsize=(10, 5))
plt.plot(df_time_series.index, df_time_series['Value'], marker='o', label='原始数据')
plt.title('时间序列数据')
plt.xlabel('日期')
plt.ylabel('值')
plt.legend()
plt.grid()
plt.show()代码解释:
- 使用Matplotlib绘制时间序列图,显示数据随时间的变化趋势。
综合练习
import pandas as pd
import numpy as np
import matplotlib
matplotlib.use('TkAgg') # 或 'Qt5Agg'
import matplotlib.pyplot as plt
# 1. 创建示例数据
data = {
'A': [1, 2, 3, 4, 5],
'B': [5, 6, 7, 8, 9]
}
df = pd.DataFrame(data)
# 2. 描述性统计
mean_A = df['A'].mean()
mean_B = df['B'].mean()
median_A = df['A'].median()
variance_A = df['A'].var()
quantiles_A = df['A'].quantile([0.25, 0.5, 0.75])
print("均值:\n", {'A': mean_A, 'B': mean_B})
print("中位数:\n", {'A': median_A, 'B': df['B'].median()})
print("方差:\n", {'A': variance_A, 'B': df['B'].var()})
print("分位数:\n", quantiles_A)
# 3. 相关性分析
correlation_A_B = df['A'].corr(df['B']) # 计算相关系数
correlation_matrix = df.corr() # 生成相关性矩阵
print("\nA与B的相关系数:", correlation_A_B)
print("\n相关性矩阵:\n", correlation_matrix)
# 4. 创建数据透视表
data_pivot = {
'Name': ['Alice', 'Bob', 'Charlie', 'David', 'Eve', 'Frank'],
'City': ['New York', 'New York', 'Chicago', 'Chicago', 'Los Angeles', 'Los Angeles'],
'Sales': [100, 150, 200, 300, 250, 400]
}
df_pivot = pd.DataFrame(data_pivot)
# 创建数据透视表,按城市汇总销售额
pivot_table = df_pivot.pivot_table(values='Sales', index='City', aggfunc='sum')
print("\n数据透视表:\n", pivot_table)
# 5. 多重聚合的数据透视表
multiple_agg = df_pivot.pivot_table(values='Sales', index='City', columns='Name', aggfunc='sum', fill_value=0) # 将缺失值填充为0
print("\n多重聚合的数据透视表:\n", multiple_agg)
# 6. 时间序列分析
date_range = pd.date_range(start='2021-01-01', periods=5, freq='D') # 创建日期范围
data_time_series = [1, 3, 5, 7, 9] # 示例数据
df_time_series = pd.DataFrame(data_time_series, index=date_range, columns=['Value']) # 创建时间序列DataFrame
print("\n创建的时间序列数据:\n", df_time_series)
# 7. 重采样
df_resampled = df_time_series.resample('2D').sum() # 每两天汇总
print("\n重采样后的时间序列数据:\n", df_resampled)
# 8. 绘制时间序列数据
plt.figure(figsize=(10, 5))
plt.plot(df_time_series.index, df_time_series['Value'], marker='o', label='原始数据') # 绘制原始数据
plt.title('时间序列数据')
plt.xlabel('日期')
plt.ylabel('值')
plt.legend()
plt.grid()
plt.show()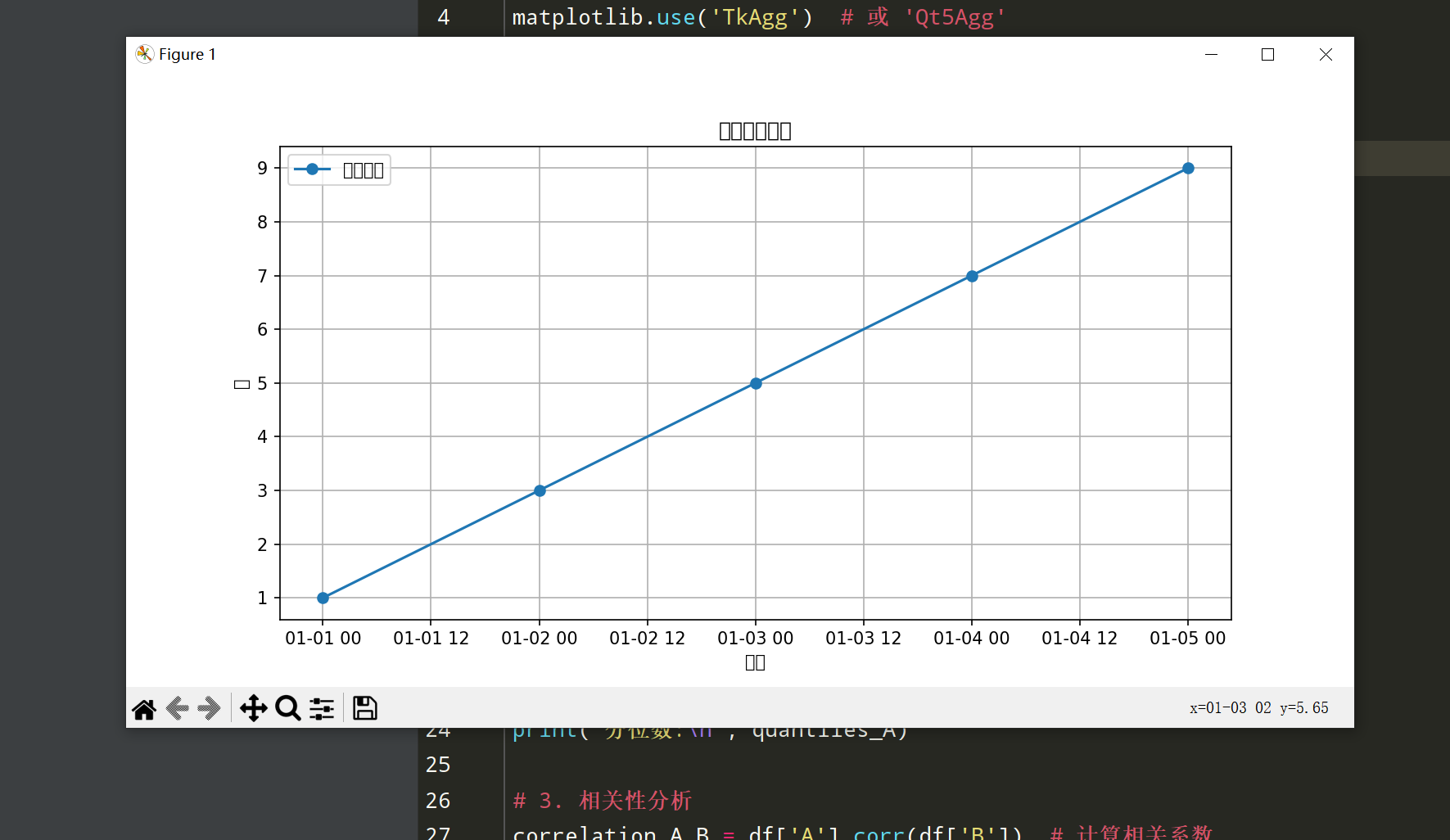
代码总结
- 创建示例数据: 创建一个包含两列数字的DataFrame。
- 描述性统计: 计算均值、中位数、方差和分位数,输出结果。
- 相关性分析: 计算相关系数并生成相关性矩阵。
- 创建数据透视表: 按城市汇总销售额,并演示如何进行多重聚合。
- 时间序列分析: 创建时间序列数据,进行重采样,并绘制时间序列图。
7. 常用函数
7-1 常用统计函数
Pandas提供了多种统计函数,用于对数据进行基本统计分析。
代码示例:
import matplotlib
matplotlib.use('TkAgg') # 或 'Qt5Agg'
import matplotlib.pyplot as plt
import pandas as pd
# 创建示例数据
data = {
'A': [1, 2, 3, 4, 5],
'B': [5, 6, 7, 8, 9]
}
df = pd.DataFrame(data)
# 计算均值
mean_A = df['A'].mean() # A列的均值
mean_B = df['B'].mean() # B列的均值
print("均值:\n", {'A': mean_A, 'B': mean_B})
# 计算中位数
median_A = df['A'].median() # A列的中位数
median_B = df['B'].median() # B列的中位数
print("\n中位数:\n", {'A': median_A, 'B': median_B})
# 计算标准差
std_A = df['A'].std() # A列的标准差
std_B = df['B'].std() # B列的标准差
print("\n标准差:\n", {'A': std_A, 'B': std_B})代码解释:
mean()、median()、std()等函数用于计算均值、中位数和标准差等统计量。
7-2 字符串处理函数
Pandas的字符串处理函数用于对包含文本数据的列进行操作。
代码示例:
# 创建包含字符串的示例数据
data_strings = {
'Name': [' Alice ', ' Bob ', 'Charlie', ' David ']
}
df_strings = pd.DataFrame(data_strings)
# 去掉字符串两端的空格
df_strings['Name'] = df_strings['Name'].str.strip()
print("\n去掉空格后的姓名:\n", df_strings)
# 转换为大写
df_strings['Name'] = df_strings['Name'].str.upper()
print("\n转换为大写后的姓名:\n", df_strings)
# 检查包含特定字符串的行
contains_charlie = df_strings['Name'].str.contains('CHARLIE')
print("\n包含'CHARLIE'的行:\n", df_strings[contains_charlie])代码解释:
str.strip()用于去掉字符串两端的空格。str.upper()用于将字符串转换为大写。str.contains()用于检查字符串是否包含特定子字符串,返回布尔值。
7-3 应用函数
Pandas提供的应用函数用于对DataFrame的行或列进行自定义操作。
7-3-1 apply()函数
apply()函数用于将自定义函数应用到DataFrame的行或列。
代码示例:
# 创建示例数据
data_apply = {
'A': [1, 2, 3, 4],
'B': [10, 20, 30, 40]
}
df_apply = pd.DataFrame(data_apply)
# 定义自定义函数
def add_ten(x):
return x + 10
# 使用apply()将自定义函数应用于A列
df_apply['A_plus_ten'] = df_apply['A'].apply(add_ten)
print("\n应用add_ten函数后的数据:\n", df_apply)代码解释:
- 定义一个函数
add_ten(),然后使用apply()将该函数应用于A列,生成新列。
7-3-2 map()函数
map()函数用于对Series中的每个元素应用函数,可以用于替换或映射值。
代码示例:
# 创建示例数据
data_map = {
'A': ['apple', 'banana', 'cherry'],
'B': [1, 2, 3]
}
df_map = pd.DataFrame(data_map)
# 使用map()替换值
map_dict = {'apple': 'fruit_1', 'banana': 'fruit_2', 'cherry': 'fruit_3'}
df_map['A'] = df_map['A'].map(map_dict) # 替换A列的值
print("\n使用map()替换后的数据:\n", df_map)代码解释:
- 使用
map()将A列的水果名称替换为指定的新名称,通过字典映射实现。
综合练习
以下是前面所有代码的综合练习部分,便于整体理解和使用。
import matplotlib
matplotlib.use('TkAgg') # 或 'Qt5Agg'
import matplotlib.pyplot as plt
import pandas as pd
import numpy as np
# 1. 创建示例数据
data = {
'A': [1, 2, 3, 4, 5],
'B': [5, 6, 7, 8, 9]
}
df = pd.DataFrame(data)
# 2. 计算均值、中位数、标准差
mean_A = df['A'].mean()
mean_B = df['B'].mean()
median_A = df['A'].median()
std_A = df['A'].std()
print("均值:\n", {'A': mean_A, 'B': mean_B})
print("中位数:\n", {'A': median_A, 'B': df['B'].median()})
print("标准差:\n", {'A': std_A, 'B': df['B'].std()})
# 3. 字符串处理
data_strings = {
'Name': [' Alice ', ' Bob ', 'Charlie', ' David ']
}
df_strings = pd.DataFrame(data_strings)
df_strings['Name'] = df_strings['Name'].str.strip()
df_strings['Name'] = df_strings['Name'].str.upper()
print("\n处理后的姓名:\n", df_strings)
# 4. 使用apply()函数
data_apply = {
'A': [1, 2, 3, 4],
'B': [10, 20, 30, 40]
}
df_apply = pd.DataFrame(data_apply)
def add_ten(x):
return x + 10
df_apply['A_plus_ten'] = df_apply['A'].apply(add_ten)
print("\n应用add_ten函数后的数据:\n", df_apply)
# 5. 使用map()函数
data_map = {
'A': ['apple', 'banana', 'cherry'],
'B': [1, 2, 3]
}
df_map = pd.DataFrame(data_map)
map_dict = {'apple': 'fruit_1', 'banana': 'fruit_2', 'cherry': 'fruit_3'}
df_map['A'] = df_map['A'].map(map_dict)
print("\n使用map()替换后的数据:\n", df_map)8. 数据可视化
8-1 使用 Matplotlib 可视化数据
Matplotlib是一个强大的绘图库,适用于创建静态、动态和交互式的图表。
8-1-1 基础绘图
代码示例:
import matplotlib
matplotlib.use('TkAgg') # 或 'Qt5Agg'
import matplotlib.pyplot as plt
import pandas as pd
# 创建示例数据
data = {
'Year': [2017, 2018, 2019, 2020, 2021],
'Sales': [150, 200, 250, 300, 350]
}
df = pd.DataFrame(data) # 将字典转换为DataFrame
# 绘制基础柱状图
plt.figure(figsize=(10, 5)) # 设置图形大小
plt.bar(df['Year'], df['Sales'], color='skyblue') # 绘制柱状图
plt.title('Annual Sales') # 设置标题
plt.xlabel('Year') # 设置x轴标签
plt.ylabel('Sales') # 设置y轴标签
plt.xticks(rotation=45) # 旋转x轴标签以便于阅读
plt.show() # 显示图形代码解释:
- 使用
plt.bar()绘制柱状图,传入x轴和y轴数据。 - 设置图表的标题和标签,
plt.show()用于展示绘制的图形。
8-1-2 绘制散点图和折线图
代码示例:
# 创建示例数据
data_line = {
'Month': ['Jan', 'Feb', 'Mar', 'Apr', 'May', 'Jun'],
'Temperature': [30, 32, 35, 28, 25, 30]
}
df_line = pd.DataFrame(data_line) # 将字典转换为DataFrame
# 绘制折线图
plt.figure(figsize=(10, 5))
plt.plot(df_line['Month'], df_line['Temperature'], marker='o', color='orange', label='Temperature') # 绘制折线图
plt.title('Monthly Temperature') # 设置标题
plt.xlabel('Month') # 设置x轴标签
plt.ylabel('Temperature (°C)') # 设置y轴标签
plt.xticks(rotation=45) # 旋转x轴标签
plt.grid() # 添加网格线
plt.legend() # 添加图例
plt.show() # 显示图形
# 绘制散点图
plt.figure(figsize=(10, 5))
plt.scatter(df['Year'], df['Sales'], color='green', s=100, label='Sales') # 绘制散点图
plt.title('Sales Scatter Plot') # 设置标题
plt.xlabel('Year') # 设置x轴标签
plt.ylabel('Sales') # 设置y轴标签
plt.xticks(rotation=45) # 旋转x轴标签
plt.legend() # 添加图例
plt.show() # 显示图形代码解释:
- 使用
plt.plot()绘制折线图,设置点标记和颜色。 - 使用
plt.scatter()绘制散点图,s参数控制点的大小。
8-2 使用 Seaborn 可视化数据
Seaborn是基于Matplotlib构建的高级绘图库,提供了更简洁的接口和更美观的图形。
8-2-1 绘制分布图
代码示例:
import seaborn as sns
# 创建示例数据
data_distribution = np.random.normal(loc=0, scale=1, size=1000) # 生成正态分布数据
# 绘制分布图
plt.figure(figsize=(10, 5))
sns.histplot(data_distribution, bins=30, kde=True, color='blue') # 绘制直方图并添加KDE曲线
plt.title('Distribution of Random Data') # 设置标题
plt.xlabel('Value') # 设置x轴标签
plt.ylabel('Frequency') # 设置y轴标签
plt.grid() # 添加网格线
plt.show() # 显示图形代码解释:
sns.histplot()用于绘制数据的直方图,同时可以通过kde=True添加核密度估计曲线。- 生成的随机数据模拟正态分布,方便观察数据的分布情况。
8-2-2 绘制箱型图和小提琴图
代码示例:
# 创建示例数据
data_box = {
'Category': ['A', 'A', 'A', 'B', 'B', 'B'],
'Value': [1, 2, 3, 4, 5, 6]
}
df_box = pd.DataFrame(data_box) # 创建DataFrame
# 绘制箱型图
plt.figure(figsize=(10, 5))
sns.boxplot(x='Category', y='Value', data=df_box, palette='Set2') # 绘制箱型图
plt.title('Box Plot of Values by Category') # 设置标题
plt.grid() # 添加网格线
plt.show() # 显示图形
# 绘制小提琴图
plt.figure(figsize=(10, 5))
sns.violinplot(x='Category', y='Value', data=df_box, palette='Set2') # 绘制小提琴图
plt.title('Violin Plot of Values by Category') # 设置标题
plt.grid() # 添加网格线
plt.show() # 显示图形代码解释:
sns.boxplot()绘制箱型图,显示数据的分布和异常值。sns.violinplot()绘制小提琴图,结合了箱型图和核密度估计的特征。
综合练习
import matplotlib
matplotlib.use('TkAgg') # 或 'Qt5Agg'
import matplotlib.pyplot as plt
import pandas as pd
import numpy as np
import seaborn as sns
# 1. 创建示例数据
data = {
'Year': [2017, 2018, 2019, 2020, 2021],
'Sales': [150, 200, 250, 300, 350]
}
df = pd.DataFrame(data) # 将字典转换为DataFrame
# 2. 绘制柱状图
plt.figure(figsize=(10, 5))
plt.bar(df['Year'], df['Sales'], color='skyblue') # 绘制柱状图
plt.title('Annual Sales') # 设置标题
plt.xlabel('Year') # 设置x轴标签
plt.ylabel('Sales') # 设置y轴标签
plt.xticks(rotation=45) # 旋转x轴标签
plt.show() # 显示图形
# 3. 绘制折线图
data_line = {
'Month': ['Jan', 'Feb', 'Mar', 'Apr', 'May', 'Jun'],
'Temperature': [30, 32, 35, 28, 25, 30]
}
df_line = pd.DataFrame(data_line) # 创建DataFrame
plt.figure(figsize=(10, 5))
plt.plot(df_line['Month'], df_line['Temperature'], marker='o', color='orange', label='Temperature') # 绘制折线图
plt.title('Monthly Temperature') # 设置标题
plt.xlabel('Month') # 设置x轴标签
plt.ylabel('Temperature (°C)') # 设置y轴标签
plt.xticks(rotation=45) # 旋转x轴标签
plt.grid() # 添加网格线
plt.legend() # 添加图例
plt.show() # 显示图形
# 4. 绘制散点图
plt.figure(figsize=(10, 5))
plt.scatter(df['Year'], df['Sales'], color='green', s=100, label='Sales') # 绘制散点图
plt.title('Sales Scatter Plot') # 设置标题
plt.xlabel('Year') # 设置x轴标签
plt.ylabel('Sales') # 设置y轴标签
plt.xticks(rotation=45) # 旋转x轴标签
plt.legend() # 添加图例
plt.show() # 显示图形
# 5. 绘制分布图
data_distribution = np.random.normal(loc=0, scale=1, size=1000) # 生成正态分布数据
plt.figure(figsize=(10, 5))
sns.histplot(data_distribution, bins=30, kde=True, color='blue') # 绘制直方图并添加KDE曲线
plt.title('Distribution of Random Data') # 设置标题
plt.xlabel('Value') # 设置x轴标签
plt.ylabel('Frequency') # 设置y轴标签
plt.grid() # 添加网格线
plt.show() # 显示图形
# 6. 绘制箱型图
data_box = {
'Category': ['A', 'A', 'A', 'B', 'B', 'B'],
'Value': [1, 2, 3, 4, 5, 6]
}
df_box = pd.DataFrame(data_box) # 创建DataFrame
plt.figure(figsize=(10, 5))
sns.boxplot(x='Category', y='Value', data=df_box, palette='Set2') # 绘制箱型图
plt.title('Box Plot of Values by Category') # 设置标题
plt.grid() # 添加网格线
plt.show() # 显示图形
# 7. 绘制小提琴图
plt.figure(figsize=(10, 5))
sns.violinplot(x='Category', y='Value', data=df_box, palette='Set2') # 绘制小提琴图
plt.title('Violin Plot of Values by Category') # 设置标题
plt.grid() # 添加网格线
plt.show() # 显示图形代码总结
- 创建示例数据: 创建包含销售数据和气温数据的DataFrame。
- 柱状图: 使用Matplotlib绘制柱状图以展示年度销售情况。
- 折线图: 使用Matplotlib绘制折线图以展示月份气温变化。
- 散点图: 使用Matplotlib绘制散点图展示年份与销售之间的关系。
- 分布图: 使用Seaborn绘制直方图,并添加核密度估计曲线以展示随机数据的分布情况。
- 箱型图: 使用Seaborn绘制箱型图以展示不同类别的值的分布。
- 小提琴图: 使用Seaborn绘制小提琴图,结合了箱型图和核密度估计
9. 性能优化
9-1 数据框的优化
9-1-1 数据类型的优化
优化数据类型可以显著降低内存占用,提高计算速度。
代码示例:
import pandas as pd
# 创建示例数据
data = {
'A': [1, 2, 3, 4, 5] * 1000000, # 大量整数数据
'B': [10.5, 20.5, 30.5, 40.5, 50.5] * 1000000, # 大量浮点数数据
'C': ['Category1', 'Category2', 'Category3', 'Category4', 'Category5'] * 1000000 # 字符串数据
}
df = pd.DataFrame(data)
# 查看原始数据类型和内存使用情况
print("原始数据类型:\n", df.dtypes)
print("\n原始内存使用情况:\n", df.memory_usage(deep=True))
# 优化数据类型
df['A'] = df['A'].astype('int32') # 使用较小的整数类型
df['B'] = df['B'].astype('float32') # 使用较小的浮点数类型
df['C'] = df['C'].astype('category') # 使用类别类型以节省内存
# 查看优化后的数据类型和内存使用情况
print("\n优化后的数据类型:\n", df.dtypes)
print("\n优化后的内存使用情况:\n", df.memory_usage(deep=True))代码解释:
- 原始数据使用默认的数据类型,内存占用较高。
- 通过
astype()方法将数据类型优化为更小的类型(如int32、float32和category),从而减少内存占用。
9-1-2 内存管理
在处理数据时,合理的内存管理可以提高性能和降低内存消耗。
代码示例:
# 使用del释放不再需要的列
del df['C'] # 删除不再需要的列
print("\n删除列后的内存使用情况:\n", df.memory_usage(deep=True))
# 使用gc模块强制垃圾回收
import gc
gc.collect() # 手动触发垃圾回收代码解释:
- 使用
del语句删除不再需要的列以释放内存。 - 使用
gc.collect()强制进行垃圾回收,清理不再使用的内存。
9-2 处理大数据集
处理大数据集时,Pandas可能会出现性能瓶颈,采用有效的方法来处理大数据集是必要的。
9-2-1 分块读取数据
对于大文件,可以采用分块读取的方式来避免内存溢出。
代码示例:
# 分块读取CSV文件
chunk_size = 100000 # 每次读取100000行
chunk_list = [] # 存储所有块的列表
for chunk in pd.read_csv('large_file.csv', chunksize=chunk_size): # 假设存在大CSV文件
# 对每个块进行处理,例如计算均值
chunk_mean = chunk['A'].mean() # 计算每个块的A列均值
chunk_list.append(chunk_mean) # 将均值保存到列表
# 合并所有块的结果
overall_mean = sum(chunk_list) / len(chunk_list) # 计算整体均值
print("整体均值:", overall_mean)代码解释:
- 使用
pd.read_csv()的chunksize参数进行分块读取,每次读取指定行数的数据块。 - 对每个数据块进行操作(如计算均值),并将结果保存。
9-2-2 使用Dask库处理大数据
Dask是一个用于并行计算的大数据处理库,可以高效地处理大于内存的数据集。
代码示例:
# 使用Dask读取大数据
import dask.dataframe as dd
# 读取CSV文件为Dask DataFrame
ddf = dd.read_csv('large_file.csv') # 假设存在大CSV文件
# 对Dask DataFrame进行操作,例如计算A列的均值
mean_value = ddf['A'].mean().compute() # 使用compute()触发计算
print("A列的均值(使用Dask):", mean_value)代码解释:
- 使用
dask.dataframe.read_csv()读取大文件并返回Dask DataFrame。 - 通过
compute()方法执行计算,Dask将利用多线程或分布式计算来处理数据。
综合练习
以下是前面所有代码的综合练习部分,便于整体理解和使用。
import pandas as pd
import numpy as np
import matplotlib
matplotlib.use('TkAgg') # 或 'Qt5Agg'
import matplotlib.pyplot as plt
import gc
# 1. 创建示例数据
data = {
'A': [1, 2, 3, 4, 5] * 1000000, # 大量整数数据
'B': [10.5, 20.5, 30.5, 40.5, 50.5] * 1000000, # 大量浮点数数据
'C': ['Category1', 'Category2', 'Category3', 'Category4', 'Category5'] * 1000000 # 字符串数据
}
df = pd.DataFrame(data) # 创建DataFrame
# 2. 查看原始数据类型和内存使用情况
print("原始数据类型:\n", df.dtypes)
print("\n原始内存使用情况:\n", df.memory_usage(deep=True))
# 3. 优化数据类型
df['A'] = df['A'].astype('int32') # 使用较小的整数类型
df['B'] = df['B'].astype('float32') # 使用较小的浮点数类型
df['C'] = df['C'].astype('category') # 使用类别类型以节省内存
# 4. 查看优化后的数据类型和内存使用情况
print("\n优化后的数据类型:\n", df.dtypes)
print("\n优化后的内存使用情况:\n", df.memory_usage(deep=True))
# 5. 删除不再需要的列并释放内存
del df['C'] # 删除不再需要的列
print("\n删除列后的内存使用情况:\n", df.memory_usage(deep=True))
# 6. 手动触发垃圾回收
gc.collect() # 手动触发垃圾回收
# 7. 分块读取数据
chunk_size = 100000 # 每次读取100000行
chunk_list = [] # 存储所有块的列表
for chunk in pd.read_csv('large_file.csv', chunksize=chunk_size): # 假设存在大CSV文件
chunk_mean = chunk['A'].mean() # 计算每个块的A列均值
chunk_list.append(chunk_mean) # 将均值保存到列表
# 8. 合并所有块的结果
overall_mean = sum(chunk_list) / len(chunk_list) # 计算整体均值
print("整体均值:", overall_mean)
# 9. 使用Dask读取大数据
import dask.dataframe as dd
# 读取CSV文件为Dask DataFrame
ddf = dd.read_csv('large_file.csv') # 假设存在大CSV文件
# 对Dask DataFrame进行操作,例如计算A列的均值
mean_value = ddf['A'].mean().compute() # 使用compute()触发计算
print("A列的均值(使用Dask):", mean_value)好的,以下是更复杂的案例分析,包括更复杂的数据清洗、分析、可视化、时间序列预测和销售数据分析的内容。每个部分都包含更多的数据处理和分析逻辑,示例代码更加详尽。
10. 实际案例分析
10-1 案例一:数据清洗与分析
在这个案例中,我们将处理一份包含缺失值、重复值和异常值的数据集,并进行描述性统计分析。
代码示例:
import matplotlib
matplotlib.use('TkAgg') # 或 'Qt5Agg'
import matplotlib.pyplot as plt
import pandas as pd
import numpy as np
# 创建示例数据
data = {
'Name': ['Alice', 'Bob', 'Charlie', 'David', 'Eve', 'Frank', None, 'Bob'],
'Age': [25, 30, None, 35, 40, 45, 150, 30], # 包含异常值和缺失值
'City': ['New York', 'Los Angeles', 'Chicago', 'Houston', 'Chicago', None, 'New York', 'Los Angeles'],
'Salary': [70000, 80000, None, 120000, 95000, 100000, 110000, 95000]
}
df = pd.DataFrame(data) # 将字典转换为DataFrame
# 数据清洗
# 1. 检查缺失值
print("缺失值数量:\n", df.isnull().sum())
# 2. 填充缺失值
df['Age'].fillna(df['Age'].mean(), inplace=True) # 用均值填充年龄
df['City'].fillna('Unknown', inplace=True) # 用'Unknown'填充城市
df['Salary'].fillna(df['Salary'].median(), inplace=True) # 用中位数填充薪水
# 3. 处理异常值(如年龄大于100)
df = df[(df['Age'] <= 100)] # 删除年龄异常值
# 4. 删除重复行
df.drop_duplicates(inplace=True)
# 数据分析
print("\n清洗后的数据:\n", df)
print("\n描述性统计:\n", df.describe(include='all')) # 输出描述性统计信息代码解释:
- 通过
isnull().sum()检查每列的缺失值数量。 - 使用
fillna()方法填充缺失值,处理异常值并删除重复行。 - 输出清洗后的数据和描述性统计信息,以便对数据集的特征有一个全面的了解。
10-2 案例二:数据可视化
在这个案例中,我们将使用Matplotlib和Seaborn对销售数据进行深入的可视化分析。
代码示例:
import matplotlib
matplotlib.use('TkAgg') # 或 'Qt5Agg'
import matplotlib.pyplot as plt
import pandas as pd
import numpy as np
import seaborn as sns # 确保导入Seaborn库
# 创建示例销售数据
data_sales = {
'Month': ['Jan', 'Jan', 'Feb', 'Feb', 'Mar', 'Mar', 'Apr', 'Apr', 'May', 'May'],
'Sales': [150, 200, 250, 300, 350, 400, 450, 500, 550, 600],
'Category': ['A', 'B', 'A', 'B', 'A', 'B', 'A', 'B', 'A', 'B']
}
df_sales = pd.DataFrame(data_sales) # 创建DataFrame
# 计算每个产品的总销售额
total_sales = df_sales.groupby('Category')['Sales'].sum().reset_index() # 按产品分组并求和
print("\n每个类别的总销售额:\n", total_sales)
# 找到最畅销的产品类别
best_selling_category = total_sales.loc[total_sales['Sales'].idxmax()] # 找到销售额最大的类别
print("\n最畅销的产品类别:\n", best_selling_category)
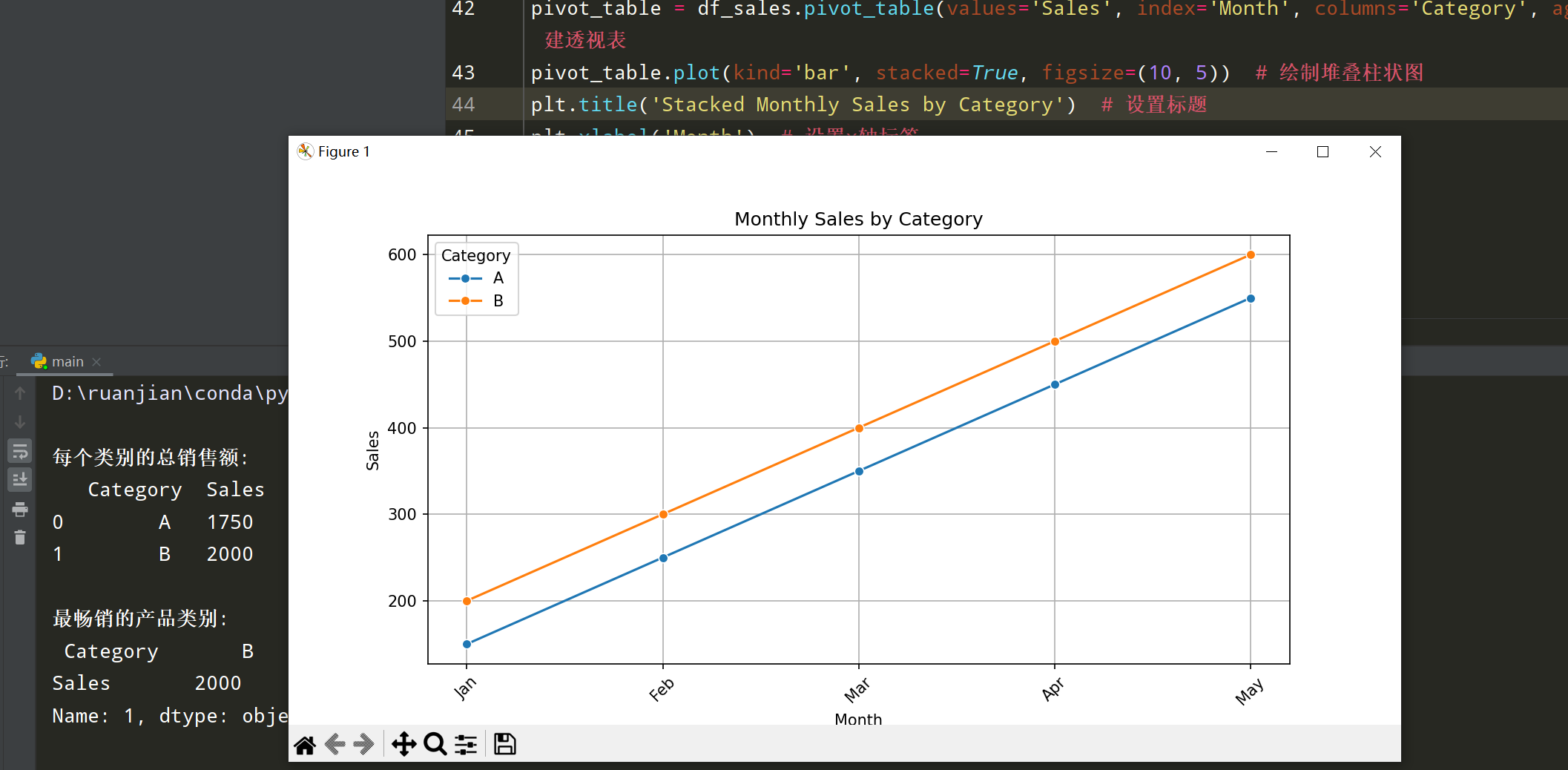
# 使用Seaborn绘制销售额随月份变化的折线图
plt.figure(figsize=(10, 5))
sns.lineplot(data=df_sales, x='Month', y='Sales', hue='Category', marker='o') # 使用不同颜色表示不同类别
plt.title('Monthly Sales by Category') # 设置标题
plt.xlabel('Month') # 设置x轴标签
plt.ylabel('Sales') # 设置y轴标签
plt.xticks(rotation=45) # 旋转x轴标签
plt.grid() # 添加网格线
plt.show() # 显示图形
# 使用Seaborn绘制箱型图
plt.figure(figsize=(10, 5))
sns.boxplot(x='Month', y='Sales', data=df_sales, palette='Set2') # 绘制箱型图
plt.title('Sales Distribution by Month') # 设置标题
plt.grid() # 添加网格线
plt.show() # 显示图形
# 使用Matplotlib绘制堆叠柱状图
pivot_table = df_sales.pivot_table(values='Sales', index='Month', columns='Category', aggfunc='sum') # 创建透视表
pivot_table.plot(kind='bar', stacked=True, figsize=(10, 5)) # 绘制堆叠柱状图
plt.title('Stacked Monthly Sales by Category') # 设置标题
plt.xlabel('Month') # 设置x轴标签
plt.ylabel('Sales') # 设置y轴标签
plt.xticks(rotation=45) # 旋转x轴标签
plt.legend(title='Category') # 添加图例
plt.grid() # 添加网格线
plt.show() # 显示图形代码解释:
- 使用
lineplot()绘制销售额随月份变化的折线图,hue参数用于区分不同的销售类别。 - 使用
boxplot()绘制箱型图,以显示每个月销售额的分布情况。 - 创建透视表并使用
plot()方法绘制堆叠柱状图,展示每个月不同类别的销售总额。
10-3 案例三:时间序列预测
在这个案例中,我们将使用时间序列数据进行预测,使用ARIMA模型进行分析。
代码示例:
from statsmodels.tsa.arima.model import ARIMA
# 创建示例时间序列数据
date_range = pd.date_range(start='2021-01-01', periods=24, freq='M') # 每月的日期范围
sales_data = [100, 120, 130, 150, 170, 180, 190, 200, 210, 220, 230, 250,
260, 270, 280, 300, 310, 320, 330, 350, 360, 370, 380, 400] # 销售数据
df_time_series = pd.DataFrame({'Date': date_range, 'Sales': sales_data})
# 设置日期为索引
df_time_series.set_index('Date', inplace=True)
# 拟合ARIMA模型
model = ARIMA(df_time_series['Sales'], order=(1, 1, 1)) # 选择ARIMA(1, 1, 1)模型
model_fit = model.fit()
# 进行预测
forecast = model_fit.forecast(steps=6) # 预测未来6个月
forecast_index = pd.date_range(start=df_time_series.index[-1] + pd.DateOffset(months=1), periods=6, freq='M') # 预测索引
# 绘制结果
plt.figure(figsize=(10, 5))
plt.plot(df_time_series.index, df_time_series['Sales'], marker='o', label='Historical Sales') # 历史数据
plt.plot(forecast_index, forecast, marker='o', linestyle='--', color='orange', label='Predicted Sales') # 预测数据
plt.title('Sales Forecast using ARIMA') # 设置标题
plt.xlabel('Date') # 设置x轴标签
plt.ylabel('Sales') # 设置y轴标签
plt.legend() # 添加图例
plt.grid() # 添加网格线
plt.show() # 显示图形代码解释:
- 创建一个包含销售数据的时间序列DataFrame,并将日期设置为索引。
- 使用
ARIMA模型进行拟合和预测,选择适当的参数(p, d, q)。 - 绘制历史销售数据和预测数据的图形,以便进行比较。
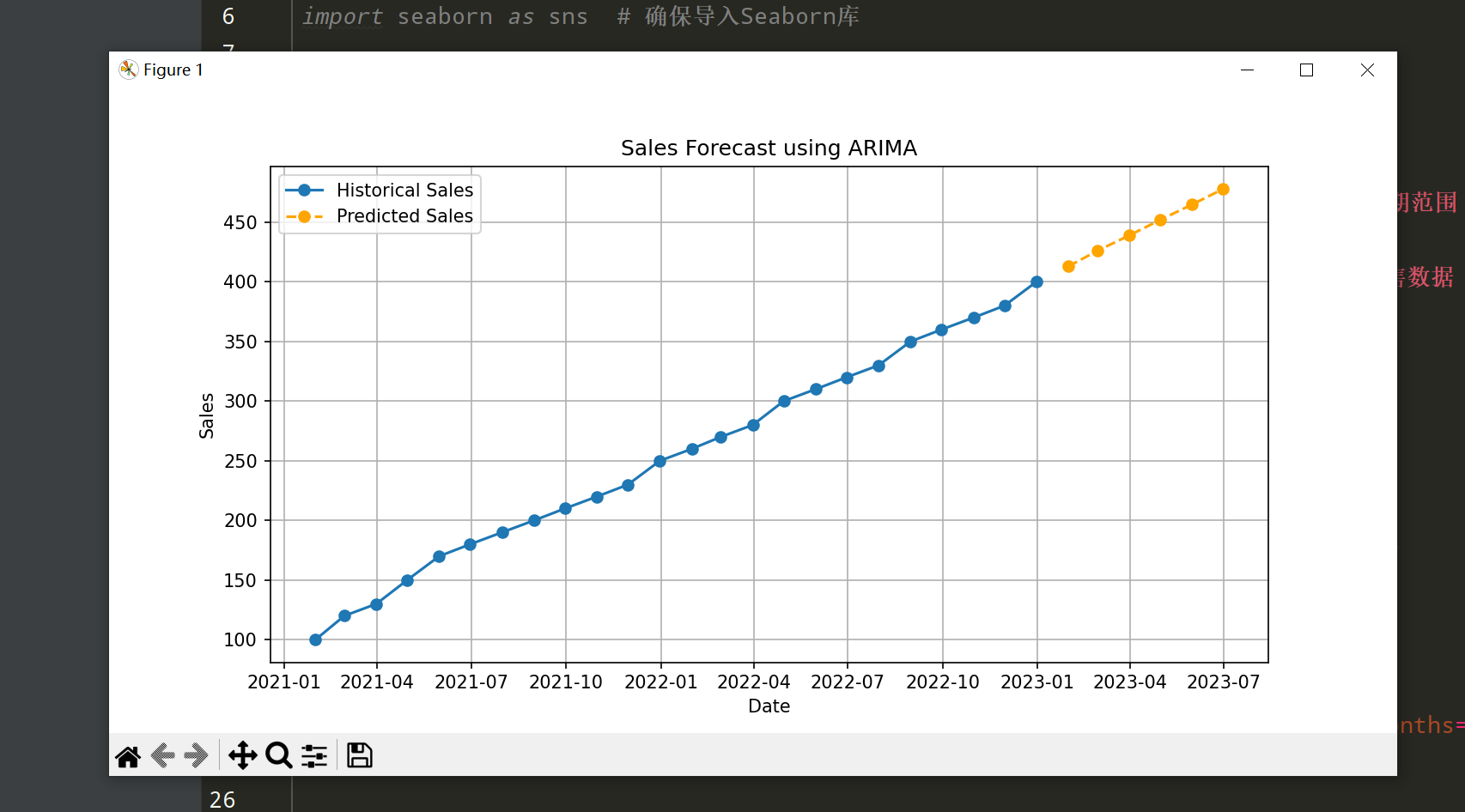
10-4 案例四:销售数据分析
在这个案例中,我们将分析销售数据,识别最畅销的产品和销售趋势。
代码示例:
import matplotlib
matplotlib.use('TkAgg') # 或 'Qt5Agg'
import matplotlib.pyplot as plt
import pandas as pd
# 创建示例销售数据
sales_data = {
'Product': ['A', 'B', 'C', 'A', 'B', 'C', 'A', 'B', 'C'],
'Sales': [100, 150, 200, 130, 170, 220, 140, 180, 250],
'Month': ['Jan', 'Jan', 'Jan', 'Feb', 'Feb', 'Feb', 'Mar', 'Mar', 'Mar']
}
df_sales = pd.DataFrame(sales_data) # 创建DataFrame
# 计算每个产品的总销售额
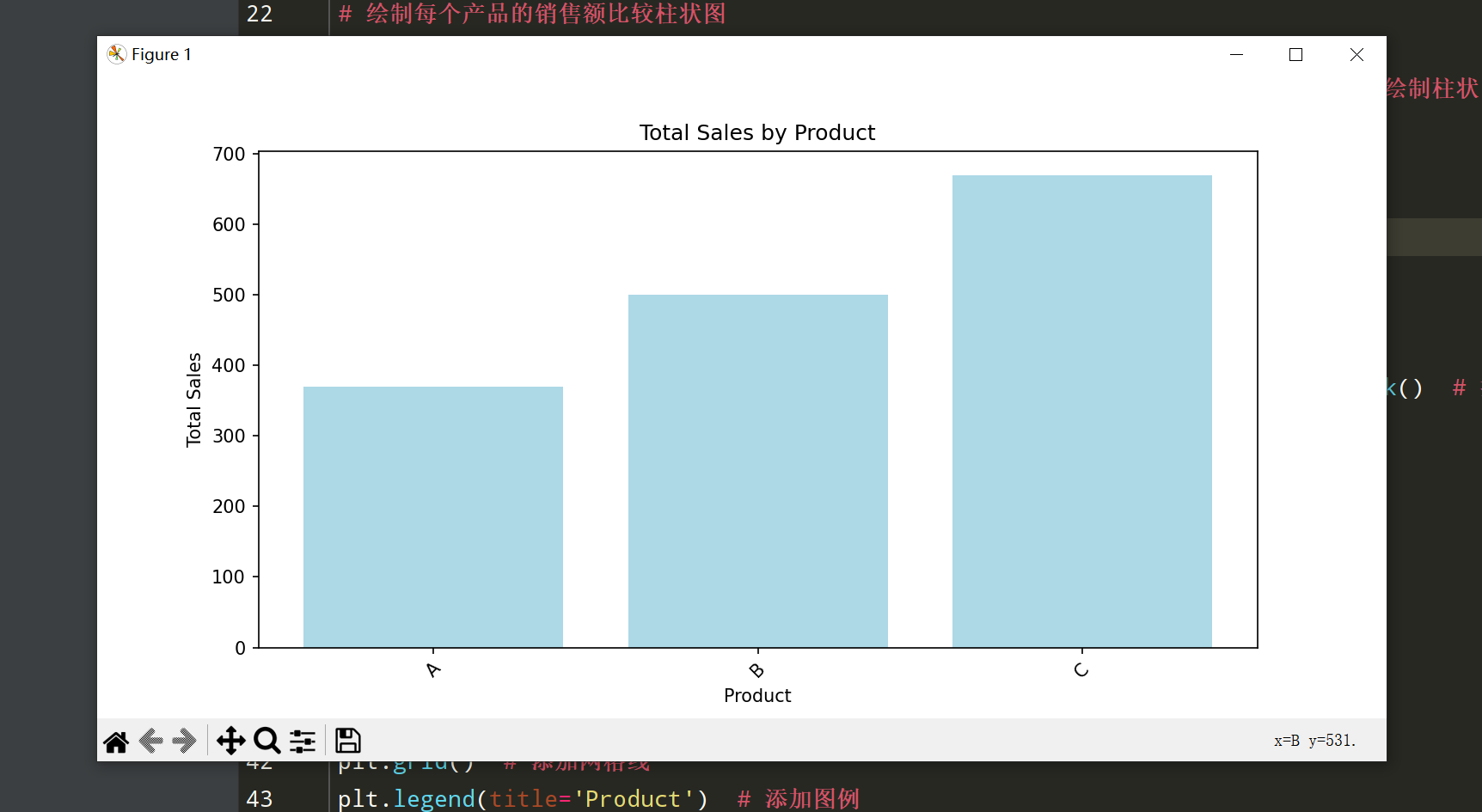
total_sales = df_sales.groupby('Product')['Sales'].sum().reset_index() # 按产品分组并求和
print("\n每个产品的总销售额:\n", total_sales)
# 找到最畅销的产品
best_selling_product = total_sales.loc[total_sales['Sales'].idxmax()] # 找到销售额最大的产品
print("\n最畅销的产品:\n", best_selling_product)
# 绘制每个产品的销售额比较柱状图
plt.figure(figsize=(10, 5))
plt.bar(total_sales['Product'], total_sales['Sales'], color='lightblue') # 绘制柱状图
plt.title('Total Sales by Product') # 设置标题
plt.xlabel('Product') # 设置x轴标签
plt.ylabel('Total Sales') # 设置y轴标签
plt.xticks(rotation=45) # 旋转x轴标签
plt.show() # 显示图形
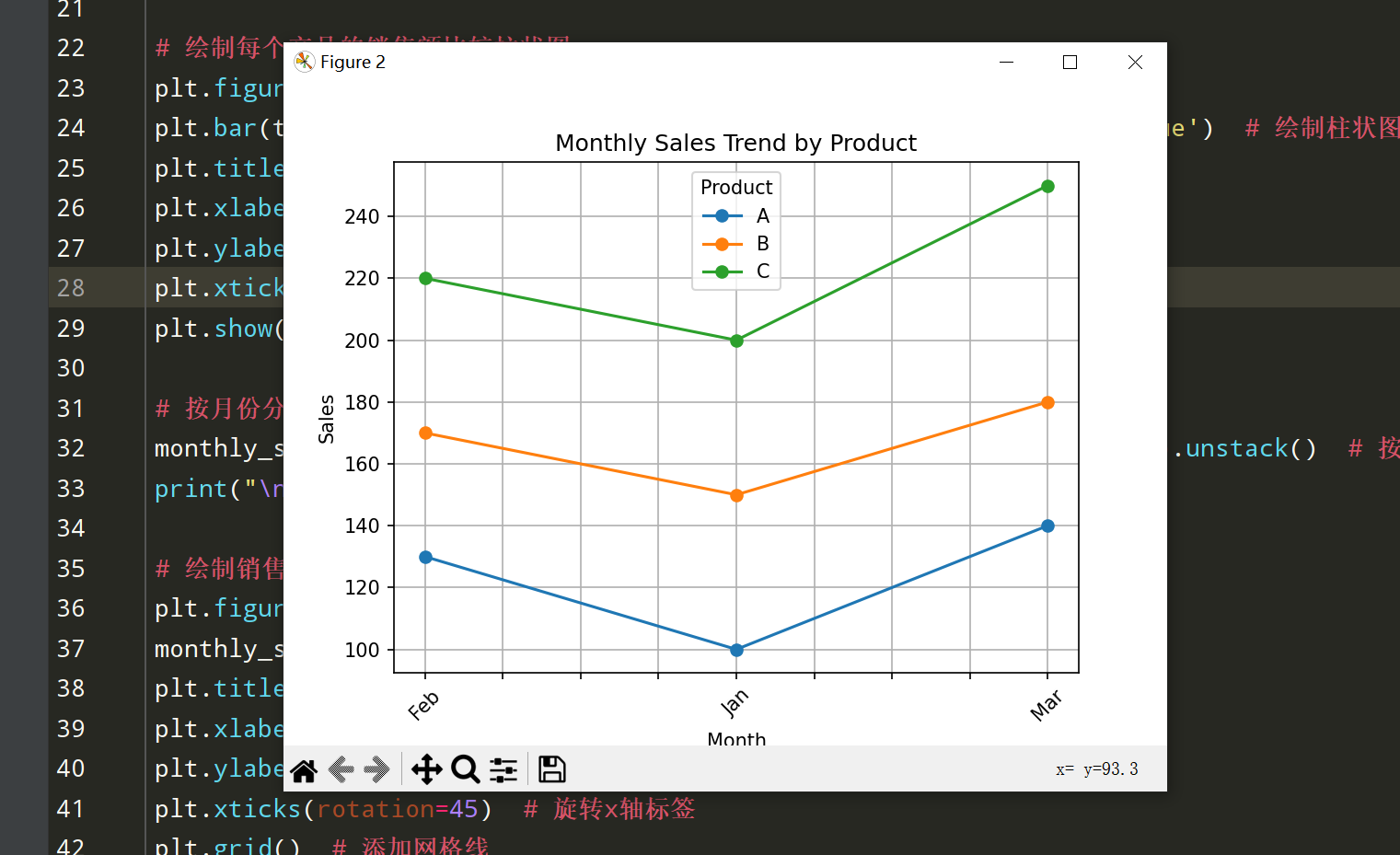
# 按月份分析销售趋势
monthly_sales = df_sales.groupby(['Month', 'Product'])['Sales'].sum().unstack() # 按月份和产品分组求和并转置
print("\n按月份和产品的销售数据:\n", monthly_sales)
# 绘制销售趋势的折线图
plt.figure(figsize=(10, 5))
monthly_sales.plot(kind='line', marker='o') # 绘制折线图
plt.title('Monthly Sales Trend by Product') # 设置标题
plt.xlabel('Month') # 设置x轴标签
plt.ylabel('Sales') # 设置y轴标签
plt.xticks(rotation=45) # 旋转x轴标签
plt.grid() # 添加网格线
plt.legend(title='Product') # 添加图例
plt.show() # 显示图形创建示例销售数据:
- 创建包含产品、销售额和月份的示例数据。
计算每个产品的总销售额:
- 使用
groupby()和sum()计算每个产品的总销售额,并将结果重置为DataFrame格式,方便后续分析。
- 使用
识别最畅销的产品:
- 使用
idxmax()找到销售额最高的产品,并输出该产品的信息。
- 使用
可视化总销售额:
- 绘制柱状图以展示各个产品的总销售额,使用
plt.bar()生成柱状图并设置标题和标签。
- 绘制柱状图以展示各个产品的总销售额,使用
分析销售趋势:
- 通过
groupby()对销售数据按月份和产品进行分组,计算每个月每种产品的销售额,并使用unstack()将结果转置为适合绘图的格式。
- 通过
绘制销售趋势的折线图:
- 使用
plot()方法绘制折线图,展示不同产品在各个月份的销售趋势,并设置图例和标题。
- 使用