2Numpy
1-1 安装NumPy
1-1-1 使用pip安装NumPy
打开命令行界面
- 在Windows上,可以按
Win + R,输入cmd,然后按回车键。 - 在Mac或Linux上,可以打开终端(Terminal)。
- 在Windows上,可以按
确保已安装Python和pip
- 在命令行中输入以下命令检查Python版本:
python --version - 输入以下命令检查pip版本:
pip --version - 如果未安装pip,可以参考官方文档进行安装。
- 在命令行中输入以下命令检查Python版本:
使用pip安装NumPy
- 输入以下命令来安装NumPy:
pip install numpy - 如果需要安装特定版本,可以使用:
pip install numpy==1.21.0 - 安装完成后,命令行会显示安装成功的消息。
- 输入以下命令来安装NumPy:
1-1-2 使用conda安装NumPy
打开命令行界面
- 同样的,打开命令行界面(cmd或Terminal)。
确保已安装Anaconda或Miniconda
- 输入以下命令检查conda版本:
conda --version - 如果未安装conda,请访问Anaconda官方网站下载并安装。
- 输入以下命令检查conda版本:
使用conda创建新的虚拟环境(可选)
- 创建一个新的虚拟环境(例如:
myenv):conda create --name myenv - 激活虚拟环境:
conda activate myenv
- 创建一个新的虚拟环境(例如:
使用conda安装NumPy
- 输入以下命令来安装NumPy:
conda install numpy - 安装完成后,会显示安装成功的消息。
- 输入以下命令来安装NumPy:
1-1-3 安装过程中的常见问题及解决方法
问题1:无法找到pip或conda命令
- 确保Python和Anaconda的安装路径已添加到系统的环境变量中。
- 可以参考Python环境变量配置和Anaconda环境变量配置。
问题2:权限错误
- 如果在安装过程中遇到权限错误,可以尝试以管理员身份运行命令提示符(在Windows上右键点击cmd选择“以管理员身份运行”),或者在Linux/Mac上使用
sudo命令:sudo pip install numpy
- 如果在安装过程中遇到权限错误,可以尝试以管理员身份运行命令提示符(在Windows上右键点击cmd选择“以管理员身份运行”),或者在Linux/Mac上使用
问题3:安装超时或失败
- 检查网络连接,确保能够访问PyPI(Python Package Index)或Anaconda仓库。
- 可以尝试更换安装源,例如使用国内的镜像:
pip install numpy -i https://pypi.tuna.tsinghua.edu.cn/simple
1-1-4 验证NumPy安装是否成功
打开Python交互式环境
- 在命令行中输入
python,进入Python的交互式命令行界面。
- 在命令行中输入
导入NumPy库
- 输入以下命令:
import numpy as np
- 输入以下命令:
检查NumPy版本
- 输入以下命令来查看安装的NumPy版本:
print(np.__version__) - 如果能够成功导入NumPy且显示版本号,说明NumPy安装成功。
- 输入以下命令来查看安装的NumPy版本:
执行简单的NumPy操作
- 你可以执行以下简单操作来测试NumPy是否工作正常:
a = np.array([1, 2, 3]) print(a) - 如果输出
[1 2 3],说明NumPy功能正常。
- 你可以执行以下简单操作来测试NumPy是否工作正常:
2. NumPy Ndarray对象
2-1 NumPy Ndarray对象概述
2-1-1 Ndarray的定义与特性
定义:Ndarray(N-dimensional array)是NumPy库中用于存储多维数组的核心对象。它是一个同质(homogeneous)数据容器,意味着所有元素的数据类型必须相同。
特性:
- 多维性:Ndarray可以是1维、2维或更高维度的数组,适用于各种复杂数据的存储。
- 高效性:由于使用连续的内存块存储数据,Ndarray在数据操作上具有高效性。
- 功能丰富:NumPy提供了大量的内置函数,可以方便地对Ndarray进行数学运算、逻辑运算等。
- 广播机制:在进行运算时,NumPy能够自动扩展数组的形状,支持不同形状数组之间的操作。
2-1-2 如何创建Ndarray对象
创建Ndarray对象的方法有很多,以下是几种常用的方法:
从列表或元组创建:
import numpy as np # 从列表创建一维数组 arr1 = np.array([1, 2, 3, 4]) print("一维数组:", arr1) # 从嵌套列表创建二维数组 arr2 = np.array([[1, 2, 3], [4, 5, 6]]) print("二维数组:\n", arr2)使用
arange函数创建数组:# 创建一个从0到9的数组 arr3 = np.arange(10) print("使用arange创建的数组:", arr3) # 创建从0到9的数组,步长为2 arr4 = np.arange(0, 10, 2) print("步长为2的数组:", arr4)使用
linspace函数创建数组:# 创建一个包含5个均匀分布的数的数组 arr5 = np.linspace(0, 1, 5) print("使用linspace创建的数组:", arr5)创建特殊数组:
# 创建全为0的数组 arr6 = np.zeros((2, 3)) # 2行3列 print("全为0的数组:\n", arr6) # 创建全为1的数组 arr7 = np.ones((2, 3)) print("全为1的数组:\n", arr7) # 创建未初始化的数组 arr8 = np.empty((2, 3)) print("未初始化的数组:\n", arr8)使用随机数生成数组:
# 创建包含5个随机数的数组 arr9 = np.random.rand(5) # 均匀分布的随机数 print("随机数数组:", arr9) # 创建一个2x3的随机整数数组 arr10 = np.random.randint(0, 10, (2, 3)) # 0到10之间的随机整数 print("随机整数数组:\n", arr10)
2-2 Ndarray的基本操作
2-2-1 数据访问与修改
访问元素:
arr = np.array([[1, 2, 3], [4, 5, 6]]) # 访问第一行第二列的元素 print("访问元素:", arr[0, 1]) # 输出: 2修改元素:
arr[0, 1] = 10 print("修改后的数组:\n", arr)访问整行或整列:
# 访问第一行 print("第一行:", arr[0]) # 访问第二列 print("第二列:", arr[:, 1]) # 使用冒号(:)表示选择所有行
2-2-2 数据切片与索引
基本切片:
# 获取前两行和前两列的子数组 sub_array = arr[:2, :2] print("切片后的数组:\n", sub_array)高级切片:
# 使用步长切片 arr2 = np.array([[1, 2, 3, 4, 5], [6, 7, 8, 9, 10]]) print("步长切片:", arr2[0, ::2]) # 获取第一行的每隔一个元素布尔索引:
# 获取大于5的元素 bool_idx = arr > 5 print("布尔索引结果:", arr[bool_idx])花式索引(Fancy Indexing):
# 使用整数数组索引 indices = np.array([0, 1]) print("花式索引结果:\n", arr[indices, [1, 2]]) # 访问(0,1)和(1,2)的元素
2-3 Ndarray与Python列表的比较
2-3-1 性能差异
- 内存占用:Ndarray使用连续的内存块存储数据,相比Python列表可以更有效地利用内存。
- 运算速度:Ndarray的操作在C语言层面实现,速度通常比Python列表要快得多,尤其是在处理大型数据时。
import time
# 测试性能
size = 1000000
# 使用Python列表
py_list = list(range(size))
start_time = time.time()
py_list = [x * 2 for x in py_list]
print("Python列表运算时间:", time.time() - start_time)
# 使用NumPy Ndarray
np_array = np.arange(size)
start_time = time.time()
np_array = np_array * 2
print("NumPy Ndarray运算时间:", time.time() - start_time)2-3-2 功能差异
- 数据类型限制:Ndarray中所有元素的数据类型必须相同,而Python列表可以存储不同类型的对象。
- 操作便利性:NumPy提供了许多便捷的数学运算和函数,支持广播、向量化运算等,方便进行数据分析和科学计算。
# 使用Ndarray进行数学运算
a = np.array([1, 2, 3])
b = np.array([4, 5, 6])
print("NumPy数组加法:", a + b) # 元素逐个相加
# 使用Python列表进行相同操作
list_a = [1, 2, 3]
list_b = [4, 5, 6]
print("Python列表加法:", [x + y for x, y in zip(list_a, list_b)]) # 使用zip进行逐个相加3. 数据类型
3-1 NumPy数据类型概述
NumPy中的数据类型(dtype)用于描述数组中元素的类型,合理的数据类型选择对于内存使用和运算性能至关重要。以下是一些常见的数据类型:
3-1-1 常见数据类型(int, float, complex, str等)
整数类型(int):
np.int8:8位整数,范围为-128到127np.int16:16位整数,范围为-32768到32767np.int32:32位整数,范围为-2147483648到2147483647np.int64:64位整数,范围为-9223372036854775808到9223372036854775807
import numpy as np int_array = np.array([1, 2, 3], dtype=np.int32) print("整数数组:", int_array) print("数据类型:", int_array.dtype) # 输出: int32浮点数类型(float):
np.float16:16位浮点数np.float32:32位浮点数np.float64:64位浮点数,通常为默认类型
float_array = np.array([1.0, 2.5, 3.7], dtype=np.float64) print("浮点数数组:", float_array) print("数据类型:", float_array.dtype) # 输出: float64复数类型(complex):
np.complex64:64位复数(32位实部和32位虚部)np.complex128:128位复数(64位实部和64位虚部)
complex_array = np.array([1+2j, 3+4j], dtype=np.complex128) print("复数数组:", complex_array) print("数据类型:", complex_array.dtype) # 输出: complex128字符串类型(str):
np.str_:字符串类型,默认大小为256字符(可以通过指定大小来改变)。
str_array = np.array(['hello', 'world'], dtype=np.str_) print("字符串数组:", str_array) print("数据类型:", str_array.dtype) # 输出: <U5布尔类型(bool):
np.bool_:布尔类型,值为True或False。
bool_array = np.array([True, False, True], dtype=np.bool_) print("布尔数组:", bool_array) print("数据类型:", bool_array.dtype) # 输出: bool
3-2 数据类型转换
在使用NumPy时,可能需要将数组从一种数据类型转换为另一种数据类型。NumPy提供了几种方法来实现这一点。
3-2-1 如何转换数据类型
使用
astype()方法:astype()方法用于转换数组的数据类型。
arr = np.array([1.5, 2.7, 3.9]) int_arr = arr.astype(np.int32) # 转换为整数类型 print("转换后的整数数组:", int_arr) # 输出: [1 2 3]直接创建数组时指定数据类型:
- 在创建数组时,可以直接通过
dtype参数指定数据类型。
arr_float = np.array([1, 2, 3], dtype=np.float32) print("创建时指定浮点数类型:", arr_float)- 在创建数组时,可以直接通过
3-2-2 常见的数据类型转换示例
浮点数转整数:
- 浮点数转换为整数时,会丢失小数部分。
float_arr = np.array([1.9, 2.8, 3.5]) int_arr = float_arr.astype(np.int32) print("浮点数转整数:", int_arr) # 输出: [1 2 3]整数转浮点数:
- 整数转换为浮点数时,不会丢失数据。
int_arr = np.array([1, 2, 3]) float_arr = int_arr.astype(np.float64) print("整数转浮点数:", float_arr) # 输出: [1. 2. 3.]布尔数组转整数:
- 在将布尔数组转换为整数时,
True会转换为1,False会转换为0。
bool_arr = np.array([True, False, True]) int_from_bool = bool_arr.astype(np.int32) print("布尔转整数:", int_from_bool) # 输出: [1 0 1]- 在将布尔数组转换为整数时,
字符串转浮点数:
- 字符串数组可以转换为浮点数数组,前提是字符串格式正确。
str_arr = np.array(['1.1', '2.2', '3.3']) float_from_str = str_arr.astype(np.float64) print("字符串转浮点数:", float_from_str) # 输出: [1.1 2.2 3.3]复数转换为浮点数:
- 将复数转换为浮点数时,只保留实部。
complex_arr = np.array([1+2j, 3+4j]) float_from_complex = complex_arr.astype(np.float64) print("复数转浮点数:", float_from_complex) # 输出: [1. 3.]处理异常数据类型转换:
- 尝试将无效的字符串转换为数值类型将会抛出错误。
invalid_str_arr = np.array(['1.1', 'two', '3.3']) try: float_invalid = invalid_str_arr.astype(np.float64) except ValueError as e: print("错误:", e) # 输出: could not convert string to float: 'two'
4. 数组属性
4-1 数组的属性介绍
NumPy数组具有多个重要的属性,这些属性可以帮助用户理解数组的结构和内容。以下是一些常用的数组属性:
4-1-1 shape、ndim、size、dtype等属性
shape属性:shape属性返回一个元组,表示数组在每个维度上的大小。它可以帮助我们了解数组的结构,例如行数和列数。
import numpy as np arr = np.array([[1, 2, 3], [4, 5, 6]]) print("数组形状:", arr.shape) # 输出: (2, 3),表示2行3列ndim属性:ndim属性返回数组的维度数。可以用来判断数组是几维的。
print("数组维度数:", arr.ndim) # 输出: 2,表示这是一个二维数组size属性:size属性返回数组中所有元素的总数,即数组的大小。
print("数组大小:", arr.size) # 输出: 6,表示数组中总共有6个元素dtype属性:dtype属性返回数组中元素的数据类型。可以用来检查数组元素的类型。
print("数组数据类型:", arr.dtype) # 输出: int64,表示数组元素是64位整数itemsize属性:itemsize属性返回数组中每个元素所占用的字节数。可以用来估算数组占用的内存大小。
print("每个元素占用的字节数:", arr.itemsize) # 输出: 8,表示每个元素占用8字节(对于int64)nbytes属性:nbytes属性返回数组的总字节数,即数组大小和每个元素大小的乘积。
print("数组总占用字节数:", arr.nbytes) # 输出: 48,表示数组总共占用48字节(6个元素,每个8字节)
4-2 如何获取与修改数组属性
4-2-1 获取数组属性
获取数组的属性非常简单,只需访问对应的属性即可。例如:
# 创建一个3x4的二维数组
arr2 = np.array([[1, 2, 3, 4], [5, 6, 7, 8], [9, 10, 11, 12]])
# 获取属性
print("数组形状:", arr2.shape) # 输出: (3, 4)
print("数组维度数:", arr2.ndim) # 输出: 2
print("数组大小:", arr2.size) # 输出: 12
print("数组数据类型:", arr2.dtype) # 输出: int64
print("每个元素占用的字节数:", arr2.itemsize) # 输出: 8
print("数组总占用字节数:", arr2.nbytes) # 输出: 964-2-2 修改数组属性
虽然某些属性(如ndim和dtype)无法直接修改,但可以通过其他方法间接修改数组的结构。下面是一些常见的操作:
修改数组的形状:
- 使用
reshape()方法可以更改数组的形状,但前提是总元素数量不变。
arr3 = np.arange(12) # 创建一个包含12个元素的数组 print("原数组:", arr3) reshaped_arr = arr3.reshape(3, 4) # 将其重塑为3行4列 print("重塑后的数组:\n", reshaped_arr)- 使用
更改数据类型:
- 可以通过
astype()方法将数组转换为其他数据类型。
arr4 = np.array([1.5, 2.3, 3.1]) print("原始数组:", arr4) arr4_int = arr4.astype(np.int32) # 转换为整数类型 print("转换后的整数数组:", arr4_int)- 可以通过
改变元素的值:
- 直接通过索引访问并修改数组元素的值。
arr5 = np.array([[1, 2], [3, 4]]) print("修改前的数组:\n", arr5) arr5[0, 1] = 10 # 修改第一行第二列的值 print("修改后的数组:\n", arr5)添加新维度:
- 使用
np.newaxis或reshape方法添加新维度。
arr6 = np.array([1, 2, 3]) print("原数组:", arr6) # 使用np.newaxis添加新维度 arr6_2d = arr6[:, np.newaxis] # 将一维数组转换为二维列数组 print("添加新维度后的数组:\n", arr6_2d)- 使用
5. 创建数组
5-1 NumPy创建数组的方法
在NumPy中,可以通过多种方式创建数组,以下是一些常用的方法。
5-1-1 从已有数组创建
可以通过将现有的数组传递给np.array()函数来创建新数组。这对于复制数组或对数组进行类型转换非常有用。
import numpy as np
# 从列表创建数组
original_array = np.array([1, 2, 3, 4, 5])
print("原始数组:", original_array)
# 从已有数组创建新数组
new_array = np.array(original_array)
print("从已有数组创建的新数组:", new_array)
# 修改新数组不会影响原始数组
new_array[0] = 10
print("修改后的新数组:", new_array) # 输出: [10 2 3 4 5]
print("原始数组不变:", original_array) # 输出: [1 2 3 4 5]5-1-2 从数值范围创建(arange, linspace)
使用
arange()函数:np.arange(start, stop, step)返回一个范围内的数组,类似于Python的range()函数,但返回的是NumPy数组。
# 创建从0到9的数组 arr_arange = np.arange(10) print("使用arange创建的数组:", arr_arange) # 输出: [0 1 2 3 4 5 6 7 8 9] # 创建从0到9的数组,步长为2 arr_arange_step = np.arange(0, 10, 2) print("步长为2的数组:", arr_arange_step) # 输出: [0 2 4 6 8]使用
linspace()函数:np.linspace(start, stop, num)返回一个数组,该数组包含从start到stop之间的num个均匀分布的样本。
# 创建一个包含5个均匀分布的数的数组 arr_linspace = np.linspace(0, 1, 5) print("使用linspace创建的数组:", arr_linspace) # 输出: [0. 0.25 0.5 0.75 1. ]
5-1-3 创建特殊数组(zeros, ones, empty)
使用
np.zeros()创建全零数组:np.zeros(shape)返回指定形状的数组,所有元素初始化为0。
# 创建一个2x3的全零数组 zeros_array = np.zeros((2, 3)) print("全零数组:\n", zeros_array)使用
np.ones()创建全一数组:np.ones(shape)返回指定形状的数组,所有元素初始化为1。
# 创建一个3x2的全一数组 ones_array = np.ones((3, 2)) print("全一数组:\n", ones_array)使用
np.empty()创建未初始化数组:np.empty(shape)返回指定形状的数组,但数组中的值是未初始化的,可能是随机的。
# 创建一个2x2的未初始化数组 empty_array = np.empty((2, 2)) print("未初始化数组:\n", empty_array) # 输出内容会是随机的
5-2 使用随机数创建数组
NumPy提供了random模块,可以方便地生成随机数。下面是一些常见用法。
5-2-1 random模块的使用
生成均匀分布的随机数:
np.random.rand(d0, d1, ..., dn)生成一个给定形状的数组,其中包含在半开区间[0.0, 1.0)上的随机浮点数。
# 创建一个2x3的数组,随机数在[0, 1)之间 random_uniform = np.random.rand(2, 3) print("均匀分布随机数数组:\n", random_uniform)生成标准正态分布的随机数:
np.random.randn(d0, d1, ..., dn)生成一个给定形状的数组,其中包含标准正态分布(均值为0,标准差为1)的随机数。
# 创建一个3x2的数组,随机数符合标准正态分布 random_normal = np.random.randn(3, 2) print("标准正态分布随机数数组:\n", random_normal)生成指定范围内的随机整数:
np.random.randint(low, high, size)生成指定范围内的随机整数。
# 创建一个2x3的数组,随机整数范围在[0, 10) random_integers = np.random.randint(0, 10, (2, 3)) print("随机整数数组:\n", random_integers)设置随机种子:
- 使用
np.random.seed(seed)可以设置随机种子,以便在多次运行代码时生成相同的随机数。
np.random.seed(42) # 设置随机种子 seed_random = np.random.rand(3) print("设置种子的随机数:\n", seed_random) # 每次运行都会得到相同的输出- 使用
6. 切片和索引
6-1 基本切片与索引
切片和索引是NumPy数组处理的基础,可以方便地访问和修改数组中的元素。
6-1-1 一维、二维和多维数组的索引
一维数组的索引:
- 一维数组使用单个索引值访问元素。
import numpy as np one_d_array = np.array([10, 20, 30, 40, 50]) print("一维数组:", one_d_array) # 访问第一个元素 print("第一个元素:", one_d_array[0]) # 输出: 10 # 访问最后一个元素 print("最后一个元素:", one_d_array[-1]) # 输出: 50二维数组的索引:
- 二维数组使用两个索引值访问元素,第一个索引表示行,第二个索引表示列。
two_d_array = np.array([[1, 2, 3], [4, 5, 6]]) print("二维数组:\n", two_d_array) # 访问第一行第二列的元素 print("第一行第二列的元素:", two_d_array[0, 1]) # 输出: 2 # 访问第二行第三列的元素 print("第二行第三列的元素:", two_d_array[1, 2]) # 输出: 6多维数组的索引:
- 多维数组的索引方法与二维数组相似,只是增加了更多的索引。
three_d_array = np.array([[[1, 2], [3, 4]], [[5, 6], [7, 8]]]) print("三维数组:\n", three_d_array) # 访问第一组第二行第一列的元素 print("第一组第二行第一列的元素:", three_d_array[0, 1, 0]) # 输出: 3
6-2 高级切片
高级切片提供了更多灵活的方式来选择和操作数组元素。
6-2-1 布尔索引
布尔索引使用条件表达式生成布尔数组,从而选择满足条件的元素。
# 创建一个数组
data = np.array([10, 20, 30, 40, 50])
# 使用布尔条件选择元素
condition = data > 25
print("满足条件(data > 25):", condition) # 输出: [False False True True True]
# 使用布尔索引选择元素
filtered_data = data[condition]
print("选择的元素:", filtered_data) # 输出: [30 40 50]
# 直接在选择中使用条件
filtered_data_direct = data[data < 30]
print("直接使用条件选择的元素:", filtered_data_direct) # 输出: [10 20]6-2-2 花式索引(Fancy Indexing)
花式索引允许通过整数数组选择数组中的特定元素。
# 创建一个数组
arr = np.array([10, 20, 30, 40, 50])
# 使用整数数组进行花式索引
indices = np.array([0, 2, 4]) # 选择第0、2、4个元素
fancy_indexed_array = arr[indices]
print("花式索引结果:", fancy_indexed_array) # 输出: [10 30 50]
# 对于二维数组的花式索引
two_d_array = np.array([[1, 2, 3], [4, 5, 6], [7, 8, 9]])
row_indices = np.array([0, 2]) # 选择第0行和第2行
col_indices = np.array([1, 1]) # 选择第1列
fancy_indexed_2d = two_d_array[row_indices, col_indices]
print("二维数组的花式索引结果:", fancy_indexed_2d) # 输出: [2 8]6-3 练习
import numpy as np
# 创建一维数组
one_d_array = np.array([10, 20, 30, 40, 50])
print("一维数组:", one_d_array)
print("第一个元素:", one_d_array[0]) # 访问第一个元素
print("最后一个元素:", one_d_array[-1]) # 访问最后一个元素
# 创建二维数组
two_d_array = np.array([[1, 2, 3], [4, 5, 6]])
print("\n二维数组:\n", two_d_array)
print("第一行第二列的元素:", two_d_array[0, 1]) # 访问元素
# 创建三维数组
three_d_array = np.array([[[1, 2], [3, 4]], [[5, 6], [7, 8]]])
print("\n三维数组:\n", three_d_array)
print("第一组第二行第一列的元素:", three_d_array[0, 1, 0]) # 访问元素
# 布尔索引示例
data = np.array([10, 20, 30, 40, 50])
print("\n布尔索引结果:", data[data > 25]) # 选择满足条件的元素
# 花式索引示例
arr = np.array([10, 20, 30, 40, 50])
indices = np.array([0, 2, 4]) # 选择第0、2、4个元素
print("\n花式索引结果:", arr[indices]) # 输出: [10 30 50]
# 二维数组的花式索引
two_d_array = np.array([[1, 2, 3], [4, 5, 6], [7, 8, 9]])
row_indices = np.array([0, 2]) # 选择第0行和第2行
col_indices = np.array([1, 1]) # 选择第1列
print("二维数组的花式索引结果:", two_d_array[row_indices, col_indices]) # 输出: [2 8]7. 高级索引
7-1 使用切片与索引获取子数组
高级索引允许用户更灵活地选择数组的特定部分。可以使用切片和多个索引来获取子数组。
获取一维数组的子数组:
- 可以通过切片语法(start:stop:step)选择一维数组的一部分。
import numpy as np one_d_array = np.array([10, 20, 30, 40, 50]) sub_array = one_d_array[1:4] # 获取从索引1到索引4(不包括4)的子数组 print("一维数组的子数组:", sub_array) # 输出: [20 30 40]获取二维数组的子数组:
- 对于二维数组,可以指定行和列的切片。
two_d_array = np.array([[1, 2, 3], [4, 5, 6], [7, 8, 9]]) sub_array_2d = two_d_array[0:2, 1:3] # 获取前两行和第二、第三列的子数组 print("二维数组的子数组:\n", sub_array_2d)
7-2 修改子数组的值
可以直接通过索引访问并修改子数组的值。这会影响原始数组,因为NumPy数组在切片时返回的是对原数组的视图,而不是副本。
# 创建一个二维数组
original_array = np.array([[1, 2, 3], [4, 5, 6], [7, 8, 9]])
print("原始数组:\n", original_array)
# 获取子数组并修改其值
sub_array = original_array[1:3, 0:2] # 获取子数组
print("子数组:\n", sub_array)
# 修改子数组的值
sub_array[0, 0] = 99
print("修改后的子数组:\n", sub_array)
print("修改后原始数组:\n", original_array) # 原始数组也随之修改7-3 复杂数据选择与操作
复杂数据选择包括使用布尔索引和花式索引等方法,可以选择特定元素或条件下的多个元素。
使用布尔索引选择特定元素:
- 通过条件表达式选择数组中的元素。
data = np.array([1, 2, 3, 4, 5, 6]) condition = data % 2 == 0 # 条件选择偶数 even_numbers = data[condition] print("选择的偶数:", even_numbers) # 输出: [2 4 6]使用花式索引选择特定行或列:
- 使用整数数组选择特定的行和列。
two_d_array = np.array([[1, 2, 3], [4, 5, 6], [7, 8, 9]]) row_indices = np.array([0, 2]) # 选择第一行和第三行 selected_rows = two_d_array[row_indices] print("选择的行:\n", selected_rows)综合使用切片和布尔索引:
- 可以将切片与布尔索引结合起来,选择特定的子集。
arr = np.array([[1, 2, 3], [4, 5, 6], [7, 8, 9]]) # 选择大于5的元素并获取其行和列 result = arr[arr > 5] print("选择的元素(大于5):", result) # 输出: [6 7 8 9]
7-4 练习
以下是一个练习代码块,回顾并实践上述知识点:
import numpy as np
# 创建一个3x3的二维数组
array = np.array([[1, 2, 3], [4, 5, 6], [7, 8, 9]])
print("原始数组:\n", array)
# 7-1: 使用切片获取子数组
sub_array = array[0:2, 1:3] # 获取前两行的第二、第三列
print("\n子数组:\n", sub_array)
# 7-2: 修改子数组的值
sub_array[0, 0] = 99
print("\n修改后的子数组:\n", sub_array)
print("修改后原始数组:\n", array) # 原始数组的值也会随之变化
# 7-3: 使用布尔索引选择特定元素
bool_condition = array > 5
selected_elements = array[bool_condition]
print("\n选择的元素(大于5):", selected_elements)
# 7-3: 使用花式索引选择特定行
row_indices = np.array([0, 2])
selected_rows = array[row_indices]
print("\n选择的行:\n", selected_rows)
# 7-3: 综合使用切片和布尔索引
result = array[array < 5]
print("\n选择的元素(小于5):", result) # 输出: [1 2 3 4]8. 数组运算
8-1 数组的基本运算
NumPy提供了对数组的基本运算,包括加、减、乘、除等操作,所有这些运算都是元素级的,即每个操作都应用于数组中的相应元素。
8-1-1 加减乘除操作
加法:
- 对两个数组执行元素相加操作。
import numpy as np a = np.array([1, 2, 3]) b = np.array([4, 5, 6]) sum_array = a + b print("加法结果:", sum_array) # 输出: [5 7 9]减法:
- 对两个数组执行元素相减操作。
difference_array = b - a print("减法结果:", difference_array) # 输出: [3 3 3]乘法:
- 对两个数组执行元素相乘操作。
product_array = a * b print("乘法结果:", product_array) # 输出: [4 10 18]除法:
- 对两个数组执行元素相除操作。
division_array = b / a print("除法结果:", division_array) # 输出: [4. 2.5 2. ]标量运算:
- NumPy数组也可以与标量进行运算,标量将应用于数组中的每个元素。
scalar_add = a + 10 print("与标量相加:", scalar_add) # 输出: [11 12 13]
8-2 广播机制(Broadcasting)
广播机制是NumPy的一个重要特性,它允许不同形状的数组之间进行运算。小数组会被“广播”到大数组的形状以进行元素级运算。
8-2-1 广播的原理与应用示例
广播的原理:
- 当两个数组的形状不同时,NumPy会按照一定的规则来扩展小数组的形状,使其与大数组的形状一致。这种扩展不会占用额外的内存。
广播示例:
- 例如,一个1维数组与一个2维数组相加:
a = np.array([[1, 2, 3], [4, 5, 6]]) b = np.array([10, 20, 30]) # 1维数组 # b会被广播到与a相同的形状 result_broadcast = a + b print("广播加法结果:\n", result_broadcast) # 输出: # [[11 22 33] # [14 25 36]]不同形状的数组相加:
- 广播也适用于不同维度的数组。例如:
c = np.array([[1], [2], [3]]) # 形状为(3, 1) result_broadcast_2 = a + c print("不同形状广播加法结果:\n", result_broadcast_2) # 输出: # [[ 2 3 4] # [ 6 7 8] # [ 9 10 11]]
8-3 数组的聚合操作
NumPy提供了一系列聚合函数,用于对数组进行统计计算,例如求和、平均值、最小值和最大值等。
8-3-1 sum、mean、min、max等函数的使用
sum()函数:
- 计算数组元素的总和。
total_sum = np.sum(a) print("总和:", total_sum) # 输出: 6mean()函数:
- 计算数组元素的平均值。
average = np.mean(a) print("平均值:", average) # 输出: 2.0min()和max()函数:
- 计算数组元素的最小值和最大值。
minimum = np.min(a) maximum = np.max(a) print("最小值:", minimum) # 输出: 1 print("最大值:", maximum) # 输出: 3沿特定轴的聚合:
- 可以指定轴(axis)进行聚合操作,例如对二维数组进行行或列的求和。
two_d_array = np.array([[1, 2, 3], [4, 5, 6]]) sum_axis0 = np.sum(two_d_array, axis=0) # 沿着列求和 sum_axis1 = np.sum(two_d_array, axis=1) # 沿着行求和 print("按列求和:", sum_axis0) # 输出: [5 7 9] print("按行求和:", sum_axis1) # 输出: [ 6 15]
8-4 练习
以下是一个练习代码块,回顾并实践上述知识点:
import numpy as np
# 8-1: 数组的基本运算
a = np.array([1, 2, 3])
b = np.array([4, 5, 6])
print("a + b:", a + b) # 加法
print("b - a:", b - a) # 减法
print("a * b:", a * b) # 乘法
print("b / a:", b / a) # 除法
# 8-2: 广播机制
c = np.array([[1, 2, 3], [4, 5, 6]])
d = np.array([10, 20, 30]) # 1维数组
broadcast_result = c + d
print("\n广播加法结果:\n", broadcast_result)
# 8-3: 聚合操作
total_sum = np.sum(c)
average = np.mean(c)
minimum = np.min(c)
maximum = np.max(c)
print("\n聚合操作:")
print("总和:", total_sum)
print("平均值:", average)
print("最小值:", minimum)
print("最大值:", maximum)
# 按行和按列的求和
sum_axis0 = np.sum(c, axis=0)
sum_axis1 = np.sum(c, axis=1)
print("按列求和:", sum_axis0) # 输出: [5 7 9]
print("按行求和:", sum_axis1) # 输出: [ 6 15]9. 数组操作
9-1 数组的拼接与分割
NumPy提供了多种方法来拼接(连接)和分割数组,以便进行更复杂的数据操作。
9-1-1 vstack、hstack、dstack、concatenate
使用
vstack()进行垂直拼接:vstack()将多个数组沿垂直方向(行)拼接,前提是它们的列数相同。
import numpy as np arr1 = np.array([[1, 2, 3], [4, 5, 6]]) # 2行3列 arr2 = np.array([[7, 8, 9]]) # 1行3列 vertical_stack = np.vstack((arr1, arr2)) print("垂直拼接结果:\n", vertical_stack) # 输出: # [[1 2 3] # [4 5 6] # [7 8 9]]使用
hstack()进行水平拼接:hstack()将多个数组沿水平方向(列)拼接,前提是它们的行数相同。
arr3 = np.array([[10, 11, 12], [13, 14, 15]]) # 2行3列 horizontal_stack = np.hstack((arr1, arr3)) # 水平拼接 print("水平拼接结果:\n", horizontal_stack) # 输出: # [[ 1 2 3 10 11 12] # [ 4 5 6 13 14 15]]使用
dstack()进行深度拼接:dstack()将多个数组沿第三个维度(深度)拼接,适用于三维数组。
arr4 = np.array([[1, 2, 3], [4, 5, 6]]) depth_stack = np.dstack((arr4, arr4)) print("深度拼接结果:\n", depth_stack) # 输出: # [[[1 1] # [2 2] # [3 3]] # # [[4 4] # [5 5] # [6 6]]]使用
concatenate()进行拼接:concatenate()可以沿任意指定的轴拼接数组。
arr5 = np.array([[1, 2, 3], [4, 5, 6]]) arr6 = np.array([[7, 8, 9]]) concat_result = np.concatenate((arr5, arr6), axis=0) # 沿着行拼接 print("拼接结果(axis=0):\n", concat_result) # 输出: # [[1 2 3] # [4 5 6] # [7 8 9]]
9-2 数组的重塑(reshape)
重塑数组是指改变数组的形状,但保持数据的顺序不变。使用reshape()方法可以实现这一点。
# 创建一个一维数组
arr = np.arange(12) # 创建一个包含12个元素的数组
print("原始数组:", arr)
# 使用reshape将其转换为二维数组
reshaped_array = arr.reshape(4, 3) # 变为4行3列
print("重塑后的数组:\n", reshaped_array)注意:重塑时,数组的总元素数量必须保持不变。
9-3 数组的复制与视图
NumPy提供了两种方式来处理数组的引用:复制和视图。理解它们之间的区别非常重要,以避免不必要的错误。
9-3-1 copy与view的区别及使用场景
copy()方法:- 创建数组的独立副本。对副本的修改不会影响原始数组。
original_array = np.array([1, 2, 3]) copied_array = original_array.copy() copied_array[0] = 99 # 修改副本 print("副本修改后:", copied_array) # 输出: [99 2 3] print("原始数组未变:", original_array) # 输出: [1 2 3]视图(View):
- 创建原始数组的视图,任何对视图的修改都会影响原始数组。
view_array = original_array[1:3] # 创建视图 view_array[0] = 100 # 修改视图 print("视图修改后:", view_array) # 输出: [100 3] print("原始数组受影响:", original_array) # 输出: [1 100 3]使用场景:
- 当需要独立操作数组内容而不影响原始数组时,使用
copy()。 - 当希望对数组进行修改且希望原数组也相应更新时,使用视图。
- 当需要独立操作数组内容而不影响原始数组时,使用
9-4 练习
以下是一个练习代码块,回顾并实践上述知识点:
import numpy as np
# 9-1: 数组的拼接
arr1 = np.array([[1, 2, 3], [4, 5, 6]]) # 2行3列
arr2 = np.array([[7, 8, 9]]) # 1行3列
# 使用vstack进行垂直拼接
vertical_stack = np.vstack((arr1, arr2))
print("垂直拼接结果:\n", vertical_stack)
# 创建arr3,确保它与arr1有相同的行数
arr3 = np.array([[10, 11, 12], [13, 14, 15]]) # 2行3列
# 水平拼接
horizontal_stack = np.hstack((arr1, arr3)) # 水平拼接
print("水平拼接结果:\n", horizontal_stack)
# 9-2: 数组的重塑
arr4 = np.arange(12)
reshaped_array = arr4.reshape(4, 3)
print("\n重塑后的数组:\n", reshaped_array)
# 9-3: 数组的复制与视图
original_array = np.array([1, 2, 3, 4, 5])
copied_array = original_array.copy()
view_array = original_array[1:4] # 视图
view_array[0] = 99 # 修改视图
print("\n原始数组:", original_array) # 应受影响
print("副本未受影响:", copied_array) # 应保持不变
# 确保结果
print("\n视图:", view_array) # 输出: [99 3 4]
print("原始数组:", original_array) # 输出: [ 1 99 3 4 5]10. 数学函数
10-1 NumPy数学函数概述
NumPy提供了丰富的数学函数,可以用于对数组执行各种数学运算。这些函数通常都是元素级的,即它们会对数组中的每个元素进行操作,返回一个新的数组。
注意: 使用数学函数时,确保输入数组的元素类型适合所执行的数学操作。例如,对于对数和平方根等函数,输入值必须是非负数。
10-2 常用数学函数
NumPy中常用的数学函数包括三角函数、指数函数和对数函数等。
10-2-1 sin、cos、exp、log等
三角函数:
np.sin()、np.cos()和np.tan()分别计算正弦、余弦和正切值。输入值通常是弧度。
import numpy as np angles = np.array([0, np.pi/2, np.pi]) # 0, 90, 180度 sin_values = np.sin(angles) cos_values = np.cos(angles) print("正弦值:", sin_values) # 输出: [0. 1. 0.] print("余弦值:", cos_values) # 输出: [ 1. 0. -1.]指数函数:
np.exp()计算以e为底的指数。
x = np.array([0, 1, 2]) exp_values = np.exp(x) print("指数值:", exp_values) # 输出: [1. 2.71828183 7.3890561 ]对数函数:
np.log()计算自然对数,np.log10()计算以10为底的对数。
y = np.array([1, np.e, 10]) log_values = np.log(y) log10_values = np.log10(y) print("自然对数值:", log_values) # 输出: [0. 1. 2.30258509] print("以10为底的对数值:", log10_values) # 输出: [0. 0.43429448 1. ]
10-3 应用示例
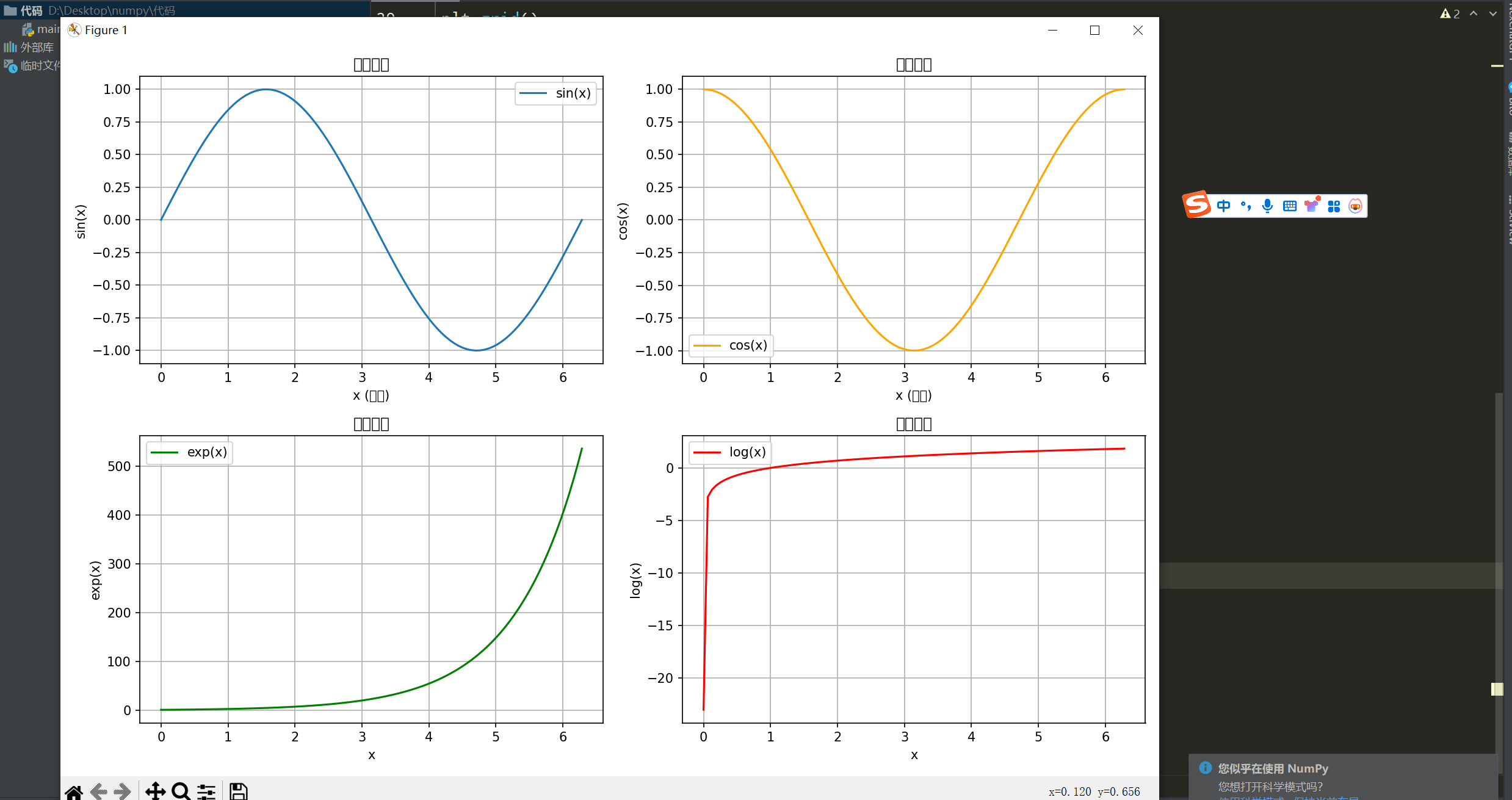
以下是一个综合示例,展示如何使用NumPy的数学函数进行实际的计算。
import numpy as np
import matplotlib
matplotlib.use('TkAgg') # 确保使用合适的后端
import matplotlib.pyplot as plt
# 生成数据
x = np.linspace(0, 2 * np.pi, 100) # 生成从0到2π的100个点
y_sin = np.sin(x) # 计算正弦值
y_cos = np.cos(x) # 计算余弦值
y_exp = np.exp(x) # 计算指数值
y_log = np.log(x + 1e-10) # 计算自然对数(避免对0取对数)
# 绘制结果
plt.figure(figsize=(12, 8))
plt.subplot(2, 2, 1)
plt.plot(x, y_sin, label='sin(x)')
plt.title('正弦函数')
plt.xlabel('x (弧度)')
plt.ylabel('sin(x)')
plt.grid()
plt.legend()
plt.subplot(2, 2, 2)
plt.plot(x, y_cos, label='cos(x)', color='orange')
plt.title('余弦函数')
plt.xlabel('x (弧度)')
plt.ylabel('cos(x)')
plt.grid()
plt.legend()
plt.subplot(2, 2, 3)
plt.plot(x, y_exp, label='exp(x)', color='green')
plt.title('指数函数')
plt.xlabel('x')
plt.ylabel('exp(x)')
plt.grid()
plt.legend()
plt.subplot(2, 2, 4)
plt.plot(x, y_log, label='log(x)', color='red')
plt.title('对数函数')
plt.xlabel('x')
plt.ylabel('log(x)')
plt.grid()
plt.legend()
plt.tight_layout()
plt.show() # 显示图形注意: 在计算对数时,确保输入值为正数,以避免出现无效的计算(例如对0取对数)。
10-4 练习
以下是一个练习代码块,回顾并实践上述知识点:
import numpy as np
# 创建一个数组
angles = np.array([0, np.pi/6, np.pi/4, np.pi/3, np.pi/2])
# 计算正弦和余弦
sin_values = np.sin(angles)
cos_values = np.cos(angles)
print("角度:", angles)
print("正弦值:", sin_values)
print("余弦值:", cos_values)
# 计算指数和对数
x = np.array([1, 2, 3, 4, 5])
exp_values = np.exp(x)
log_values = np.log(x)
print("\n指数值:", exp_values)
print("对数值:", log_values)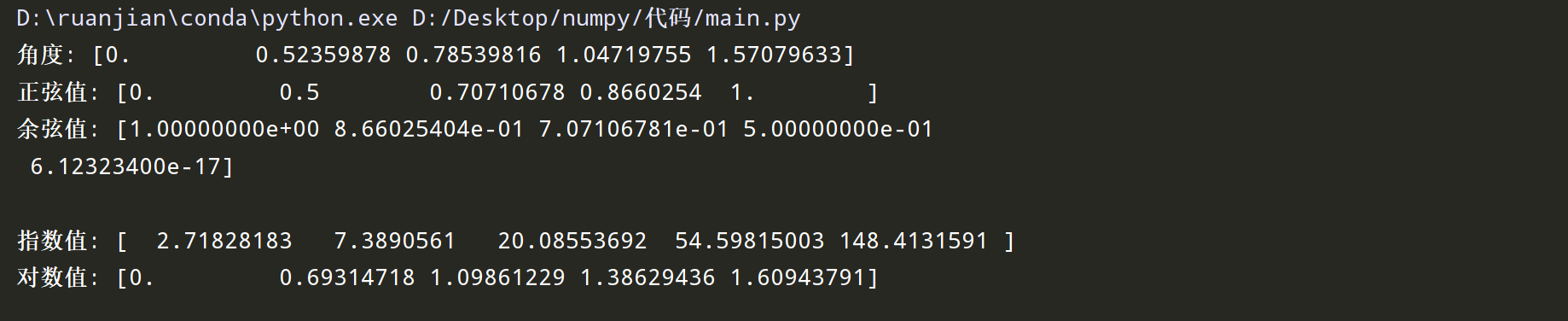
11. 统计函数
11-1 统计函数概述
NumPy提供了一系列统计函数,可以帮助用户对数组数据进行统计分析。这些函数可以用于计算均值、中位数、标准差、方差等,从而为数据分析提供重要的信息。
11-2 描述性统计
描述性统计是对数据集进行总结的统计分析,主要包括集中趋势和离散程度的度量。
11-2-1 mean、median、std、var等
均值(mean):
np.mean()用于计算数组元素的平均值。
import numpy as np data = np.array([1, 2, 3, 4, 5]) mean_value = np.mean(data) print("均值:", mean_value) # 输出: 3.0中位数(median):
np.median()用于计算数组元素的中位数。
median_value = np.median(data) print("中位数:", median_value) # 输出: 3.0标准差(std):
np.std()用于计算数组元素的标准差,表示数据的离散程度。
std_value = np.std(data) print("标准差:", std_value) # 输出: 1.4142135623730951方差(var):
np.var()用于计算数组元素的方差。
var_value = np.var(data) print("方差:", var_value) # 输出: 2.0
11-3 统计分析实例
下面是一个实际的统计分析示例,展示如何使用NumPy的统计函数对数据进行分析。
import numpy as np
import matplotlib.pyplot as plt
# 生成随机数据
data = np.random.normal(loc=0, scale=1, size=1000) # 生成1000个正态分布的随机数
# 计算统计量
mean_value = np.mean(data)
median_value = np.median(data)
std_value = np.std(data)
var_value = np.var(data)
print("数据的统计量:")
print("均值:", mean_value)
print("中位数:", median_value)
print("标准差:", std_value)
print("方差:", var_value)
# 绘制直方图
plt.figure(figsize=(10, 6))
plt.hist(data, bins=30, alpha=0.7, color='blue', edgecolor='black')
plt.axvline(mean_value, color='red', linestyle='dashed', linewidth=1, label='均值')
plt.axvline(median_value, color='yellow', linestyle='dashed', linewidth=1, label='中位数')
plt.title('正态分布随机数的直方图')
plt.xlabel('值')
plt.ylabel('频率')
plt.legend()
plt.grid()
plt.show()注意: 使用统计函数时,确保对数据的特性有足够的了解,以便更好地解释结果。
11-4 练习
以下是一个练习代码块,回顾并实践上述统计函数的知识点:
import numpy as np
# 创建一个包含随机数的数组
data = np.array([10, 20, 30, 40, 50, 60, 70, 80, 90, 100])
# 计算统计量
mean_value = np.mean(data)
median_value = np.median(data)
std_value = np.std(data)
var_value = np.var(data)
print("统计量:")
print("均值:", mean_value)
print("中位数:", median_value)
print("标准差:", std_value)
print("方差:", var_value)
12. 排序与选择
12-1 数组的排序
NumPy提供了多种排序功能,可以对数组进行排序操作。
12-1-1 sort与argsort的使用
使用
sort()进行排序:np.sort()可以对数组进行排序,返回排序后的新数组。
import numpy as np arr = np.array([3, 1, 2, 5, 4]) sorted_array = np.sort(arr) # 对数组进行排序 print("排序后的数组:", sorted_array) # 输出: [1 2 3 4 5]- 注意:
sort()返回的是新数组,原始数组不变。如果想就地排序,可以使用sort()方法:
arr.sort() # 对原数组进行就地排序 print("原数组经过就地排序:", arr) # 输出: [1 2 3 4 5]使用
argsort()获取排序索引:np.argsort()返回排序后元素的索引,这可以用于获取排序的顺序。
arr = np.array([3, 1, 2, 5, 4]) sorted_indices = np.argsort(arr) # 获取排序后的索引 print("排序索引:", sorted_indices) # 输出: [1 2 0 4 3] # 可以使用这些索引对原数组进行排序 sorted_by_index = arr[sorted_indices] print("通过索引排序的数组:", sorted_by_index) # 输出: [1 2 3 4 5]
12-2 条件选择与过滤
NumPy支持条件选择与过滤,通过逻辑条件从数组中选择元素。
12-2-1 使用where、nonzero等函数
使用
np.where()进行条件选择:np.where()根据给定的条件返回满足条件的元素的索引,或者可以用来根据条件生成新数组。
arr = np.array([10, 20, 30, 40, 50]) condition = arr > 30 # 创建条件 indices = np.where(condition) # 获取满足条件的索引 print("满足条件的索引:", indices) # 输出: (array([3, 4]),) # 直接返回满足条件的元素 selected_elements = arr[condition] print("满足条件的元素:", selected_elements) # 输出: [40 50]使用
np.nonzero()获取非零元素的索引:np.nonzero()返回数组中非零元素的索引。
arr = np.array([0, 1, 2, 0, 3, 0, 4]) nonzero_indices = np.nonzero(arr) # 获取非零元素的索引 print("非零元素的索引:", nonzero_indices) # 输出: (array([1, 2, 4, 6]),) # 使用这些索引选择非零元素 nonzero_elements = arr[nonzero_indices] print("非零元素:", nonzero_elements) # 输出: [1 2 3 4]
12-3 练习
以下是一个练习代码块,回顾并实践上述知识点:
import numpy as np
# 创建一个数组
arr = np.array([5, 3, 8, 1, 4])
# 12-1: 数组的排序
sorted_array = np.sort(arr)
print("排序后的数组:", sorted_array) # 输出: [1 3 4 5 8]
# 使用argsort获取排序索引
sorted_indices = np.argsort(arr)
print("排序索引:", sorted_indices) # 输出: [3 1 4 0 2]
# 12-2: 条件选择与过滤
# 使用where选择大于3的元素
condition = arr > 3
selected_elements = arr[condition]
print("大于3的元素:", selected_elements) # 输出: [5 8 4]
# 使用nonzero获取非零元素的索引
nonzero_indices = np.nonzero(arr)
print("非零元素的索引:", nonzero_indices) # 输出: (array([0, 1, 2, 3, 4]),)
13. 字符串函数
13-1 NumPy字符串函数概述
NumPy提供了一些用于处理字符串的函数,这些函数能够高效地对字符串数组进行操作。NumPy的字符串函数通常以np.char开头,支持各种字符串操作,如连接、分割、查找、替换等。
13-2 字符串处理示例
以下是一些常用的字符串处理示例,包括字符串连接、分割和查找。
13-2-1 字符串连接、分割、查找
字符串连接:
- 使用
np.char.add()可以连接两个字符串数组。
import numpy as np arr1 = np.array(['Hello', 'World']) arr2 = np.array([' NumPy', ' Tutorial']) # 使用add进行字符串连接 concatenated = np.char.add(arr1, arr2) print("字符串连接结果:", concatenated) # 输出: ['Hello NumPy' 'World Tutorial']- 使用
字符串分割:
- 使用
np.char.split()可以将字符串按指定分隔符进行分割。
arr3 = np.array(['Hello NumPy Tutorial', 'Welcome to Python']) # 使用split进行字符串分割 split_result = np.char.split(arr3) print("字符串分割结果:", split_result) # 输出: [list(['Hello', 'NumPy', 'Tutorial']) list(['Welcome', 'to', 'Python'])]- 使用
字符串查找:
- 使用
np.char.find()可以查找子字符串在主字符串中的位置。如果找不到,返回-1。
arr4 = np.array(['Hello', 'World', 'NumPy']) # 使用find查找字符 find_result = np.char.find(arr4, 'o') print("查找结果:", find_result) # 输出: [4 1 -1]- 使用
字符串替换:
- 使用
np.char.replace()可以将字符串中的某个子字符串替换为另一个字符串。
arr5 = np.array(['Hello World', 'NumPy is great']) # 使用replace进行字符串替换 replaced_result = np.char.replace(arr5, 'World', 'NumPy') print("替换结果:", replaced_result) # 输出: ['Hello NumPy' 'NumPy is great']- 使用
13-3 练习
以下是一个练习代码块,回顾并实践上述字符串函数的知识点:
import numpy as np
# 创建字符串数组
strings = np.array(['apple', 'banana', 'cherry'])
# 13-1: 字符串连接
more_fruits = np.array([' and orange', ' and grape', ' and kiwi'])
connected = np.char.add(strings, more_fruits)
print("连接结果:", connected) # 输出: ['apple and orange' 'banana and grape' 'cherry and kiwi']
# 13-2: 字符串分割
sentence = np.array(['I love Python programming.'])
split_sentence = np.char.split(sentence)
print("分割结果:", split_sentence) # 输出: [list(['I', 'love', 'Python', 'programming.'])]
# 13-3: 字符串查找
find_result = np.char.find(strings, 'a')
print("查找结果:", find_result) # 输出: [0 1 2],表示'a'的位置
14. 线性代数
14-1 线性代数基础
线性代数是数学的一个分支,主要研究向量、矩阵及其运算。在NumPy中,线性代数的功能主要集中在numpy.linalg模块中,提供了矩阵运算和线性方程求解等功能。
14-2 向量与矩阵操作
14-2-1 矩阵的乘法、转置、逆
矩阵的乘法:
- 使用
np.dot()或@操作符进行矩阵乘法。矩阵A的列数必须等于矩阵B的行数。
import numpy as np A = np.array([[1, 2], [3, 4]]) B = np.array([[5, 6], [7, 8]]) # 矩阵乘法 product = np.dot(A, B) # 或者使用 A @ B print("矩阵乘法结果:\n", product) # 输出: # [[19 22] # [43 50]]- 使用
矩阵的转置:
- 使用
.T属性或np.transpose()函数对矩阵进行转置。
C = np.array([[1, 2, 3], [4, 5, 6]]) # 矩阵转置 transposed_C = C.T print("矩阵转置结果:\n", transposed_C) # 输出: # [[1 4] # [2 5] # [3 6]]- 使用
矩阵的逆:
- 使用
np.linalg.inv()函数计算可逆矩阵的逆。只有方阵才能计算逆,且该矩阵必须是可逆的。
D = np.array([[1, 2], [3, 4]]) # 计算矩阵的逆 D_inv = np.linalg.inv(D) print("矩阵的逆:\n", D_inv) # 输出: # [[-2. 1. ] # [ 1.5 -0.5]]- 注意:在计算逆之前,确保矩阵是可逆的,可以通过判断行列式是否为零。
det_D = np.linalg.det(D) print("行列式:", det_D) # 输出: -2.0,表示D是可逆的- 使用
14-3 特征值与特征向量的计算
特征值和特征向量是线性代数的重要概念,主要用于对矩阵进行特征分解。在NumPy中,可以使用np.linalg.eig()函数计算。
# 创建一个方阵
E = np.array([[2, 1], [1, 2]])
# 计算特征值和特征向量
eigenvalues, eigenvectors = np.linalg.eig(E)
print("特征值:", eigenvalues) # 输出: 特征值
print("特征向量:\n", eigenvectors) # 输出: 特征向量14-4 练习
以下是一个练习代码块,回顾并实践上述线性代数相关知识点:
import numpy as np
# 创建两个矩阵
A = np.array([[2, 3], [5, 4]])
B = np.array([[1, 2], [3, 2]])
# 14-1: 矩阵乘法
product = np.dot(A, B)
print("矩阵乘法结果:\n", product)
# 14-2: 矩阵转置
transposed_A = A.T
print("矩阵A的转置:\n", transposed_A)
# 14-3: 矩阵的逆
A_inv = np.linalg.inv(A)
print("矩阵A的逆:\n", A_inv)
# 14-4: 特征值与特征向量
C = np.array([[3, 1], [1, 3]])
eigenvalues, eigenvectors = np.linalg.eig(C)
print("矩阵C的特征值:", eigenvalues)
print("矩阵C的特征向量:\n", eigenvectors)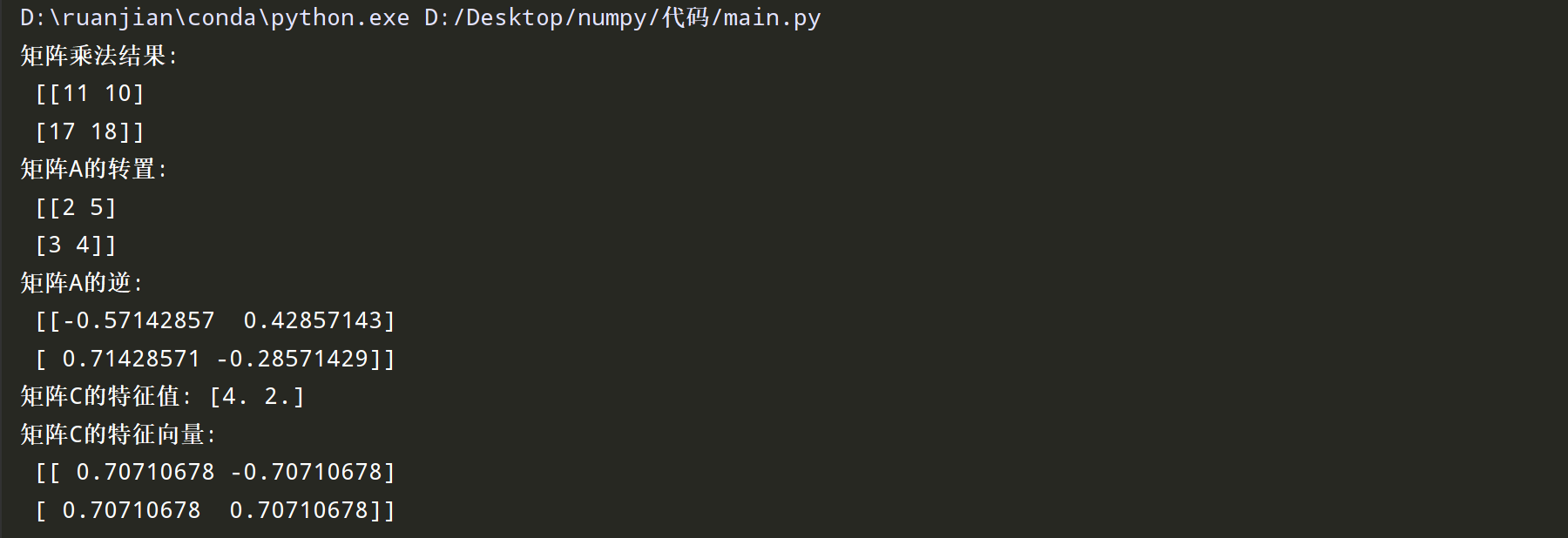
15. 文件输入与输出
NumPy提供了一些函数用于方便地读取和写入数组数据到文件中,支持多种文件格式,特别是文本文件和二进制文件。
15-1 从文件读取数组
15-1-1 使用loadtxt与genfromtxt
使用
np.loadtxt()从文本文件读取数组:np.loadtxt()用于加载文本文件的数据并返回数组。该函数适合读取格式一致的文本文件。
import numpy as np # 假设有一个文本文件 data.txt,内容如下: # 1.0 2.0 3.0 # 4.0 5.0 6.0 # 7.0 8.0 9.0 # 使用loadtxt读取文件 data_array = np.loadtxt('data.txt') print("读取的数据:\n", data_array) # 输出: # [[1. 2. 3.] # [4. 5. 6.] # [7. 8. 9.]]使用
np.genfromtxt()从文本文件读取数组:np.genfromtxt()与loadtxt()类似,但更灵活,可以处理缺失值和不同的数据类型。
# 假设有一个文本文件 data_with_nan.txt,内容如下: # 1.0 2.0 3.0 # 4.0 NaN 6.0 # 7.0 8.0 9.0 # 使用genfromtxt读取文件 data_with_nan = np.genfromtxt('data_with_nan.txt', filling_values=0) # 将NaN替换为0 print("读取的数据(处理NaN):\n", data_with_nan) # 输出: # [[1. 2. 3.] # [4. 0. 6.] # [7. 8. 9.]]
15-2 保存数组到文件
15-2-1 使用savetxt与save
使用
np.savetxt()将数组保存为文本文件:np.savetxt()用于将数组保存为文本文件,支持自定义分隔符和格式。
# 创建一个数组 array_to_save = np.array([[1, 2, 3], [4, 5, 6], [7, 8, 9]]) # 保存数组到文本文件 np.savetxt('saved_data.txt', array_to_save, delimiter=',', fmt='%d') # 使用逗号作为分隔符 print("数组已保存为文本文件: saved_data.txt")使用
np.save()将数组保存为二进制文件:np.save()用于将数组以二进制格式保存为.npy文件。这种格式是NumPy的专用格式,读取速度更快,支持保存更多数据类型。
# 保存数组到二进制文件 np.save('saved_array.npy', array_to_save) print("数组已保存为二进制文件: saved_array.npy")- 使用
np.load()可以加载保存的二进制文件。
loaded_array = np.load('saved_array.npy') # 加载保存的数组 print("加载的数组:\n", loaded_array) # 输出: # [[1 2 3] # [4 5 6] # [7 8 9]]
15-3 练习
以下是一个练习代码块,回顾并实践上述文件输入与输出相关知识点:
import numpy as np
# 15-1: 从文件读取数组
# 假设文件 data.txt 已经存在且格式正确
data_array = np.loadtxt('data.txt')
print("从文件读取的数据:\n", data_array)
# 15-2: 保存数组到文件
array_to_save = np.array([[10, 20, 30], [40, 50, 60], [70, 80, 90]])
# 保存为文本文件
np.savetxt('saved_data.txt', array_to_save, delimiter=',', fmt='%d')
print("数组已保存为文本文件: saved_data.txt")
# 保存为二进制文件
np.save('saved_array.npy', array_to_save)
print("数组已保存为二进制文件: saved_array.npy")
# 加载保存的二进制文件
loaded_array = np.load('saved_array.npy')
print("加载的数组:\n", loaded_array)
16. 与其他库的结合
16-1 NumPy与Pandas结合使用
Pandas是基于NumPy构建的,用于数据分析和数据操作的强大工具。Pandas中的DataFrame和Series对象都基于NumPy数组,因此可以非常方便地与NumPy结合使用。
创建Pandas对象:
- 可以使用NumPy数组创建Pandas的
DataFrame和Series。
import numpy as np import pandas as pd # 创建NumPy数组 data = np.array([[1, 2, 3], [4, 5, 6]]) # 使用NumPy数组创建DataFrame df = pd.DataFrame(data, columns=['A', 'B', 'C']) print("DataFrame:\n", df) # 输出: # A B C # 0 1 2 3 # 1 4 5 6- 可以使用NumPy数组创建Pandas的
从Pandas对象中获取NumPy数组:
- 可以使用
.values属性或.to_numpy()方法将DataFrame或Series转换为NumPy数组。
# 从DataFrame获取NumPy数组 array_from_df = df.values print("从DataFrame获取的NumPy数组:\n", array_from_df)- 可以使用
利用NumPy进行数据处理:
- 在Pandas中,可以利用NumPy的函数进行数据处理,例如计算均值、标准差等。
mean_values = np.mean(df, axis=0) # 计算每列的均值 print("每列的均值:", mean_values)
16-2 NumPy与Matplotlib结合使用
Matplotlib是一个用于绘图的强大库,常与NumPy结合使用,以便将数据可视化。
使用NumPy生成数据并绘图:
- NumPy可以生成数据,然后利用Matplotlib进行绘制。
import numpy as np import matplotlib matplotlib.use('TkAgg') # 确保使用合适的后端 import matplotlib.pyplot as plt # 生成x数据 x = np.linspace(0, 10, 100) # 从0到10生成100个点 y_sin = np.sin(x) # 计算y值 y_cos = np.cos(x) # 计算y值 # 绘制正弦和余弦函数图 plt.figure(figsize=(12, 6)) plt.subplot(1, 2, 1) plt.plot(x, y_sin, label='sin(x)', color='blue') plt.title('正弦函数') plt.xlabel('x (弧度)') plt.ylabel('sin(x)') plt.grid() plt.legend() plt.subplot(1, 2, 2) plt.plot(x, y_cos, label='cos(x)', color='orange') plt.title('余弦函数') plt.xlabel('x (弧度)') plt.ylabel('cos(x)') plt.grid() plt.legend() plt.tight_layout() plt.show() # 显示图形利用NumPy进行数据分析后绘图:
- 可以在对数据进行分析(如求平均值)后,利用Matplotlib进行结果可视化。
# 生成随机数据 data = np.random.randn(1000) # 生成1000个正态分布随机数 plt.hist(data, bins=30, alpha=0.7, color='blue', edgecolor='black') plt.title('Histogram of Random Data') plt.xlabel('Value') plt.ylabel('Frequency') plt.grid() plt.show()
16-3 NumPy与SciPy结合使用
SciPy是一个基于NumPy的科学计算库,提供了许多用于优化、插值、积分等高级数学函数。
线性代数操作:
- SciPy提供了更高效的线性代数功能,通常用于处理NumPy数组。
from scipy.linalg import inv A = np.array([[1, 2], [3, 4]]) A_inv = inv(A) # 计算矩阵的逆 print("矩阵的逆:\n", A_inv)优化与最小化:
- SciPy可以用于求解最优化问题,例如最小化函数。
from scipy.optimize import minimize # 定义一个简单的二次函数 def objective(x): return x**2 + 3*x + 2 result = minimize(objective, 0) # 从0开始寻找最小值 print("优化结果:", result)插值:
- SciPy支持多种插值方法,可以用于数据平滑和数据填充。
from scipy.interpolate import interp1d x = np.array([1, 2, 3, 4]) y = np.array([1, 4, 9, 16]) # 创建插值函数 f = interp1d(x, y, kind='linear') x_new = np.linspace(1, 4, 10) y_new = f(x_new) plt.plot(x, y, 'o', label='data points') plt.plot(x_new, y_new, '-', label='linear interpolation') plt.legend() plt.show()
16-4 练习
以下是一个练习代码块,回顾并实践上述NumPy与其他库结合使用的相关知识点:
import numpy as np
import pandas as pd
import matplotlib
matplotlib.use('TkAgg') # 确保使用合适的后端
import matplotlib.pyplot as plt
from scipy import stats
# 16-1: NumPy与Pandas结合使用
data = np.array([[1, 2, 3], [4, 5, 6]])
df = pd.DataFrame(data, columns=['A', 'B', 'C'])
print("DataFrame:\n", df)
# 16-2: NumPy与Matplotlib结合使用
x = np.linspace(0, 10, 100)
y = np.cos(x)
plt.plot(x, y, label='cos(x)')
plt.title('Cosine Function')
plt.xlabel('x')
plt.ylabel('cos(x)')
plt.grid()
plt.legend()
plt.show()
# 16-3: NumPy与SciPy结合使用
# 使用SciPy进行正态分布的概率密度函数计算
mu, sigma = 0, 1 # 均值和标准差
s = np.random.normal(mu, sigma, 1000) # 生成1000个样本
count, bins, ignored = plt.hist(s, 30, density=True)
plt.show()
# 计算并绘制正态分布的概率密度函数
pdf = stats.norm.pdf(bins, mu, sigma)
plt.plot(bins, pdf, 'r-', label='Normal Distribution')
plt.legend()
plt.show()
17. NumPy的性能优化
17-1 使用NumPy优化性能的技巧
NumPy通过以下方式优化性能,使得数值计算更加高效:
使用矢量化操作:
- 矢量化操作是指对整个数组进行操作,而不是使用循环。这样可以显著提高性能,因为NumPy底层实现使用了C语言进行优化。
import numpy as np # 创建两个大数组 a = np.random.rand(1000000) b = np.random.rand(1000000) # 矢量化操作 c = a + b # 数组加法避免使用Python循环:
- 尽量避免在处理大数组时使用Python循环,而是使用NumPy提供的函数和方法,这样可以减少开销。
# 不推荐的做法 result = [] for i in range(len(a)): result.append(a[i] + b[i]) # 使用循环使用广播机制:
- 广播允许不同形状的数组之间进行运算,而无需显式地重复数组的内容。这可以节省内存并提高计算效率。
# 示例:将一个标量加到数组上 a = np.array([1, 2, 3]) b = 5 result = a + b # 广播合理选择数据类型:
- 根据需要选择适当的数据类型可以减少内存消耗,提高计算效率。例如,使用
float32而不是float64,如果不需要高精度。
# 使用float32减少内存 a = np.array([1.0, 2.0, 3.0], dtype=np.float32)- 根据需要选择适当的数据类型可以减少内存消耗,提高计算效率。例如,使用
利用NumPy内置函数:
- NumPy提供了许多经过优化的内置函数,可以避免手动实现相同的功能。使用这些函数通常会比自定义实现更快。
# 使用NumPy的内置函数 sum_value = np.sum(a) # 计算数组的总和
17-2 使用NumPy进行大数据分析的优势
NumPy在进行大数据分析时具有多种优势:
高效的数组存储:
- NumPy数组在内存中是连续存储的,这使得其比Python列表更紧凑,能够更有效地利用内存。
快速的数组操作:
- NumPy使用C和Fortran编写的底层实现,能够执行快速的数组运算,大大提高了数据处理速度。
强大的数学运算能力:
- NumPy提供了丰富的数学和统计函数,可以对大型数据集进行复杂的计算和分析。
与其他科学计算库的兼容性:
- NumPy是许多其他科学计算库(如Pandas、SciPy、Matplotlib)的基础,便于在数据分析中使用多个库。
并行处理能力:
- NumPy可以通过多线程和并行计算来加速数据处理过程,特别是在处理大规模数据时。
17-3 练习
以下是一个练习代码块,回顾并实践上述NumPy性能优化的相关知识点:
import numpy as np
# 17-1: 使用矢量化操作
# 创建大数组
a = np.random.rand(1000000)
b = np.random.rand(1000000)
# 矢量化加法
c = a + b
# 17-2: 使用广播机制
x = np.array([1, 2, 3])
y = 5
result = x + y # 广播操作
print("广播结果:", result) # 输出: [6 7 8]
# 17-3: 使用NumPy内置函数
mean_value = np.mean(a) # 计算均值
print("数组的均值:", mean_value)
18. 实际案例分析
18-1 数据预处理与清洗
我们将创建一个包含销售数据的Pandas DataFrame,并执行数据预处理和清洗操作。
import numpy as np
import pandas as pd
import matplotlib
# 在导入pyplot之前设置后端
matplotlib.use('TkAgg') # 或者 'Qt5Agg'
import seaborn as sns
import matplotlib.pyplot as plt
# 创建示例数据集
data = {
'Product': ['A', 'B', 'C', 'A', 'B', 'C', 'A', None, 'B'],
'Sales': [250, 150, np.nan, 300, 200, np.nan, 350, 400, 450],
'Profit': [50, 30, 10, 70, 20, 5, np.nan, 80, 90],
'Quantity': [10, 5, 2, 15, 7, np.nan, 20, 25, 30]
}
df = pd.DataFrame(data)
print("原始数据:\n", df)
# 1. 检查缺失值
print("\n缺失值统计:\n", df.isnull().sum())
# 2. 填充缺失值
df['Sales'] = df['Sales'].fillna(df['Sales'].mean()) # 用平均值填充销售额
df['Profit'] = df['Profit'].fillna(df['Profit'].mean()) # 用平均值填充利润
df['Quantity'] = df['Quantity'].fillna(df['Quantity'].median()) # 用中位数填充数量
df['Product'] = df['Product'].fillna('Unknown') # 用'Unknown'填充缺失的产品名
print("\n处理缺失值后的数据:\n", df)18-2 数据可视化示例
在数据清洗完成后,我们可以使用Matplotlib进行数据可视化,以帮助更好地理解数据的特征和趋势。
plt.figure(figsize=(12, 6))
sns.scatterplot(x='Sales', y='Profit', hue='Product', data=df)
plt.title('Sales vs Profit by Product')
plt.xlabel('Sales')
plt.ylabel('Profit')
plt.grid()
plt.show()
# 2. 各产品的销售额条形图
plt.figure(figsize=(12, 6))
sns.barplot(x='Product', y='Sales', data=df, estimator=np.sum, palette='viridis')
plt.title('Total Sales by Product')
plt.xlabel('Product')
plt.ylabel('Total Sales')
plt.grid()
plt.show()
# 3. 销售数量的箱型图
plt.figure(figsize=(12, 6))
sns.boxplot(x='Product', y='Quantity', data=df)
plt.title('Quantity Distribution by Product')
plt.xlabel('Product')
plt.ylabel('Quantity')
plt.grid()
plt.show()18-3 使用NumPy进行统计分析的实际案例
在这一部分,我们将使用NumPy进行更深入的统计分析,计算相关系数,标准差和利润率等。
### 18-3 使用NumPy进行统计分析的实际案例
# 将数据转换为NumPy数组进行分析
sales = df['Sales'].to_numpy()
profit = df['Profit'].to_numpy()
quantity = df['Quantity'].to_numpy()
# 1. 计算均值和标准差
mean_sales = np.mean(sales)
std_sales = np.std(sales)
print("\n销售额的均值:", mean_sales)
print("销售额的标准差:", std_sales)
# 2. 计算利润率
profit_margin = profit / sales
print("\n利润率:\n", profit_margin)
# 3. 计算相关系数
correlation = np.corrcoef(sales, profit)[0, 1]
print("\n销售额与利润的相关系数:", correlation)
# 4. 计算总销售额和总利润
total_sales = np.sum(sales)
total_profit = np.sum(profit)
print("\n总销售额:", total_sales)
print("总利润:", total_profit)
# 5. 绘制利润率的直方图
plt.figure(figsize=(10, 5))
plt.hist(profit_margin, bins=20, alpha=0.7, color='blue', edgecolor='black')
plt.title('Profit Margin Distribution')
plt.xlabel('Profit Margin')
plt.ylabel('Frequency')
plt.grid()
plt.show()18-4 完整的代码
import numpy as np
import pandas as pd
import matplotlib
# 在导入pyplot之前设置后端
matplotlib.use('TkAgg') # 或者 'Qt5Agg'
import seaborn as sns
import matplotlib.pyplot as plt
# 创建示例数据集
data = {
'Product': ['A', 'B', 'C', 'A', 'B', 'C', 'A', None, 'B'],
'Sales': [250, 150, np.nan, 300, 200, np.nan, 350, 400, 450],
'Profit': [50, 30, 10, 70, 20, 5, np.nan, 80, 90],
'Quantity': [10, 5, 2, 15, 7, np.nan, 20, 25, 30]
}
df = pd.DataFrame(data)
print("原始数据:\n", df)
# 1. 检查缺失值
print("\n缺失值统计:\n", df.isnull().sum())
# 2. 填充缺失值
df['Sales'] = df['Sales'].fillna(df['Sales'].mean()) # 用平均值填充销售额
df['Profit'] = df['Profit'].fillna(df['Profit'].mean()) # 用平均值填充利润
df['Quantity'] = df['Quantity'].fillna(df['Quantity'].median()) # 用中位数填充数量
df['Product'] = df['Product'].fillna('Unknown') # 用'Unknown'填充缺失的产品名
print("\n处理缺失值后的数据:\n", df)
# 3. 删除重复值
df = df.drop_duplicates()
print("\n删除重复值后的数据:\n", df)
# 4. 确保数据类型一致
df['Sales'] = df['Sales'].astype(float)
df['Profit'] = df['Profit'].astype(float)
df['Quantity'] = df['Quantity'].astype(int)
print("\n数据类型处理后的数据:\n", df.dtypes)
### 18-2 数据可视化示例
# 1. 销售额和利润的散点图
plt.figure(figsize=(12, 6))
sns.scatterplot(x='Sales', y='Profit', hue='Product', data=df)
plt.title('Sales vs Profit by Product')
plt.xlabel('Sales')
plt.ylabel('Profit')
plt.grid()
plt.show()
# 2. 各产品的销售额条形图
plt.figure(figsize=(12, 6))
sns.barplot(x='Product', y='Sales', data=df, estimator=np.sum, palette='viridis')
plt.title('Total Sales by Product')
plt.xlabel('Product')
plt.ylabel('Total Sales')
plt.grid()
plt.show()
# 3. 销售数量的箱型图
plt.figure(figsize=(12, 6))
sns.boxplot(x='Product', y='Quantity', data=df)
plt.title('Quantity Distribution by Product')
plt.xlabel('Product')
plt.ylabel('Quantity')
plt.grid()
plt.show()
### 18-3 使用NumPy进行统计分析的实际案例
# 将数据转换为NumPy数组进行分析
sales = df['Sales'].to_numpy()
profit = df['Profit'].to_numpy()
quantity = df['Quantity'].to_numpy()
# 1. 计算均值和标准差
mean_sales = np.mean(sales)
std_sales = np.std(sales)
print("\n销售额的均值:", mean_sales)
print("销售额的标准差:", std_sales)
# 2. 计算利润率
profit_margin = profit / sales
print("\n利润率:\n", profit_margin)
# 3. 计算相关系数
correlation = np.corrcoef(sales, profit)[0, 1]
print("\n销售额与利润的相关系数:", correlation)
# 4. 计算总销售额和总利润
total_sales = np.sum(sales)
total_profit = np.sum(profit)
print("\n总销售额:", total_sales)
print("总利润:", total_profit)
# 5. 绘制利润率的直方图
plt.figure(figsize=(10, 5))
plt.hist(profit_margin, bins=20, alpha=0.7, color='blue', edgecolor='black')
plt.title('Profit Margin Distribution')
plt.xlabel('Profit Margin')
plt.ylabel('Frequency')
plt.grid()
plt.show()19-练习题
1. 实现K-Means聚类算法
题目: 实现K-Means聚类算法,对一组随机生成的二维数据进行聚类,并可视化结果。
思路:
- 随机生成数据点。
- 随机初始化聚类中心。
- 迭代分配数据点到最近的聚类中心,并更新聚类中心,直到收敛。
import numpy as np
import matplotlib
matplotlib.use('TkAgg') # 或者 'Qt5Agg'
import matplotlib.pyplot as plt
# 生成随机数据
np.random.seed(0)
X = np.random.rand(300, 2)
# K-Means算法
def kmeans(X, k, max_iters=100):
# 随机初始化聚类中心
centroids = X[np.random.choice(X.shape[0], k, replace=False)]
for _ in range(max_iters):
# 计算距离
distances = np.linalg.norm(X[:, np.newaxis] - centroids, axis=2)
# 分配每个点到最近的聚类中心
labels = np.argmin(distances, axis=1)
# 更新聚类中心
new_centroids = np.array([X[labels == i].mean(axis=0) for i in range(k)])
# 如果中心不再变化,退出循环
if np.all(centroids == new_centroids):
break
centroids = new_centroids
return labels, centroids
# 运行K-Means
k = 3
labels, centroids = kmeans(X, k)
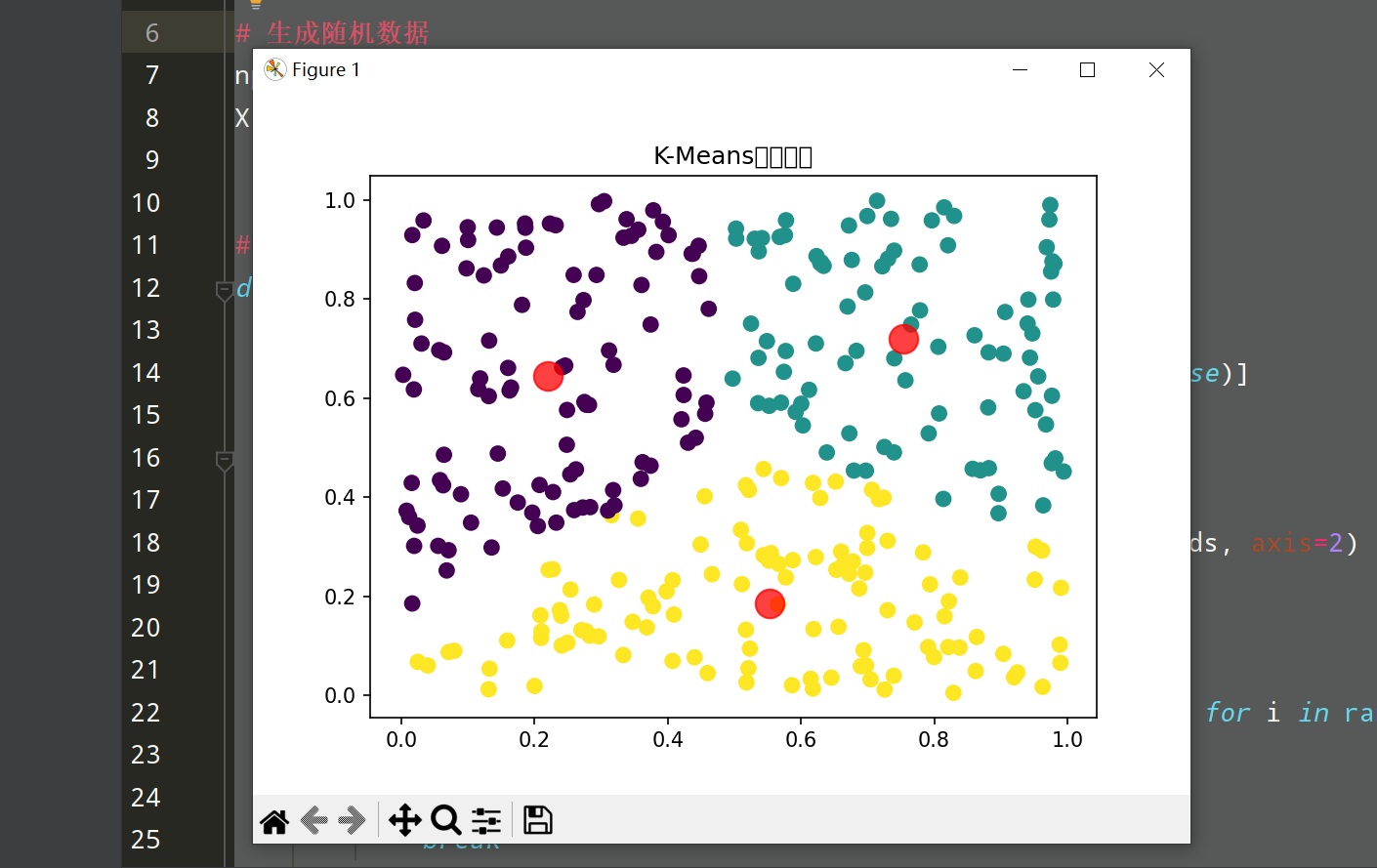
# 可视化结果
plt.scatter(X[:, 0], X[:, 1], c=labels, cmap='viridis', s=50)
plt.scatter(centroids[:, 0], centroids[:, 1], c='red', s=200, alpha=0.75)
plt.title('K-Means聚类结果')
plt.show()代码解释:
- 使用随机数生成300个二维数据点。
kmeans函数实现K-Means聚类,分配点到最近的聚类中心并更新中心位置。- 最后可视化聚类结果。
2. 主成分分析(PCA)
题目: 使用NumPy实现主成分分析(PCA)来降维。
思路:
- 生成随机数据。
- 标准化数据,计算协方差矩阵。
- 计算特征值和特征向量,选择主成分。
import numpy as np
import matplotlib
matplotlib.use('TkAgg') # 或者 'Qt5Agg'
import matplotlib.pyplot as plt
# 生成随机数据
np.random.seed(0)
data = np.random.rand(100, 5)
# 标准化数据
data_mean = np.mean(data, axis=0)
data_centered = data - data_mean
# 计算协方差矩阵
cov_matrix = np.cov(data_centered, rowvar=False)
# 计算特征值和特征向量
eigenvalues, eigenvectors = np.linalg.eig(cov_matrix)
# 选择前两个主成分
top_indices = np.argsort(eigenvalues)[-2:] # 选择最大的两个特征值的索引
top_eigenvectors = eigenvectors[:, top_indices]
# 降维
reduced_data = data_centered.dot(top_eigenvectors)
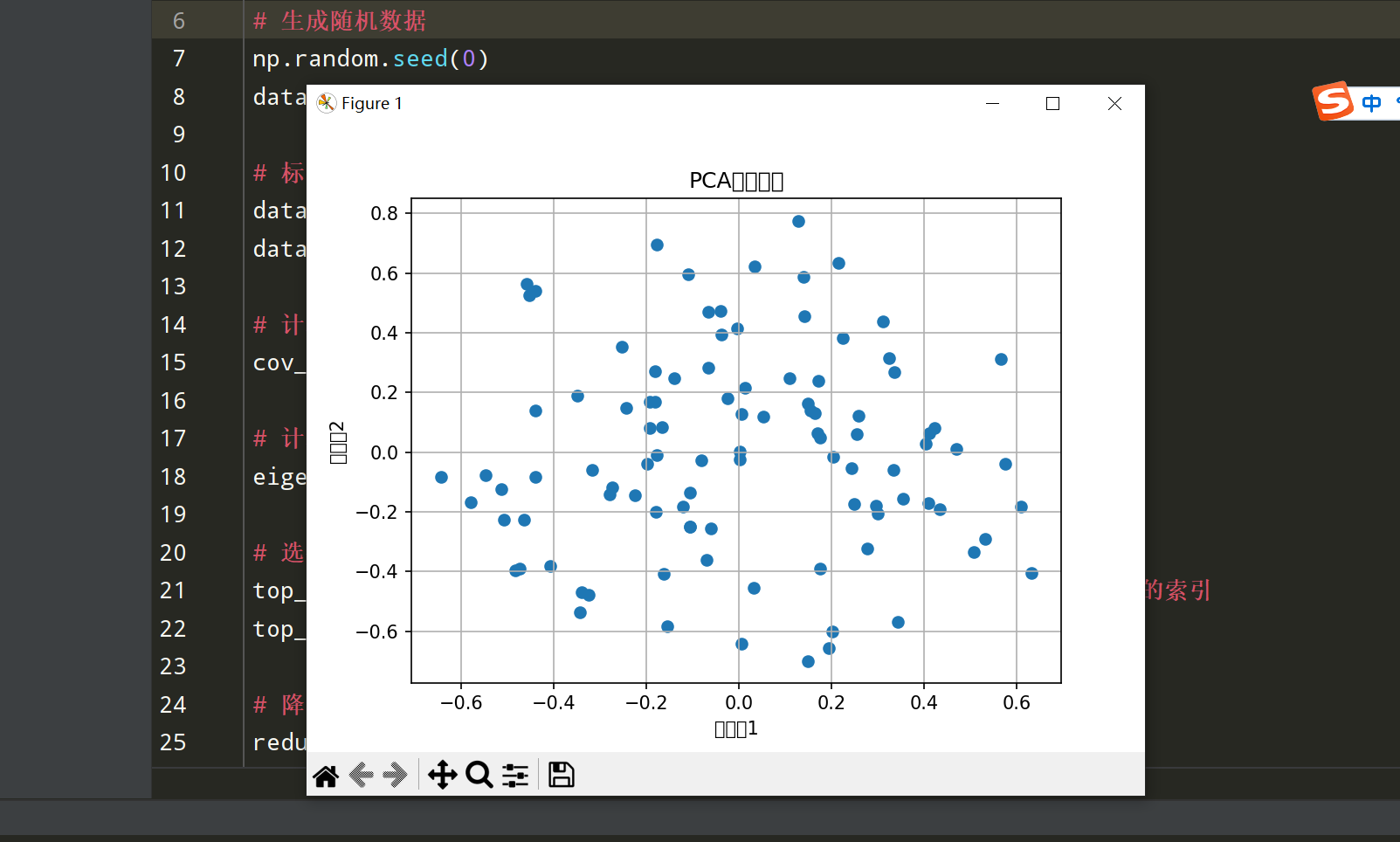
# 可视化
plt.scatter(reduced_data[:, 0], reduced_data[:, 1])
plt.title('PCA降维结果')
plt.xlabel('主成分1')
plt.ylabel('主成分2')
plt.grid()
plt.show()代码解释:
- 生成100个5维随机数据,计算标准化后的协方差矩阵。
- 计算特征值和特征向量,选择最大的两个特征值对应的特征向量进行降维。
3. 时间序列数据分析
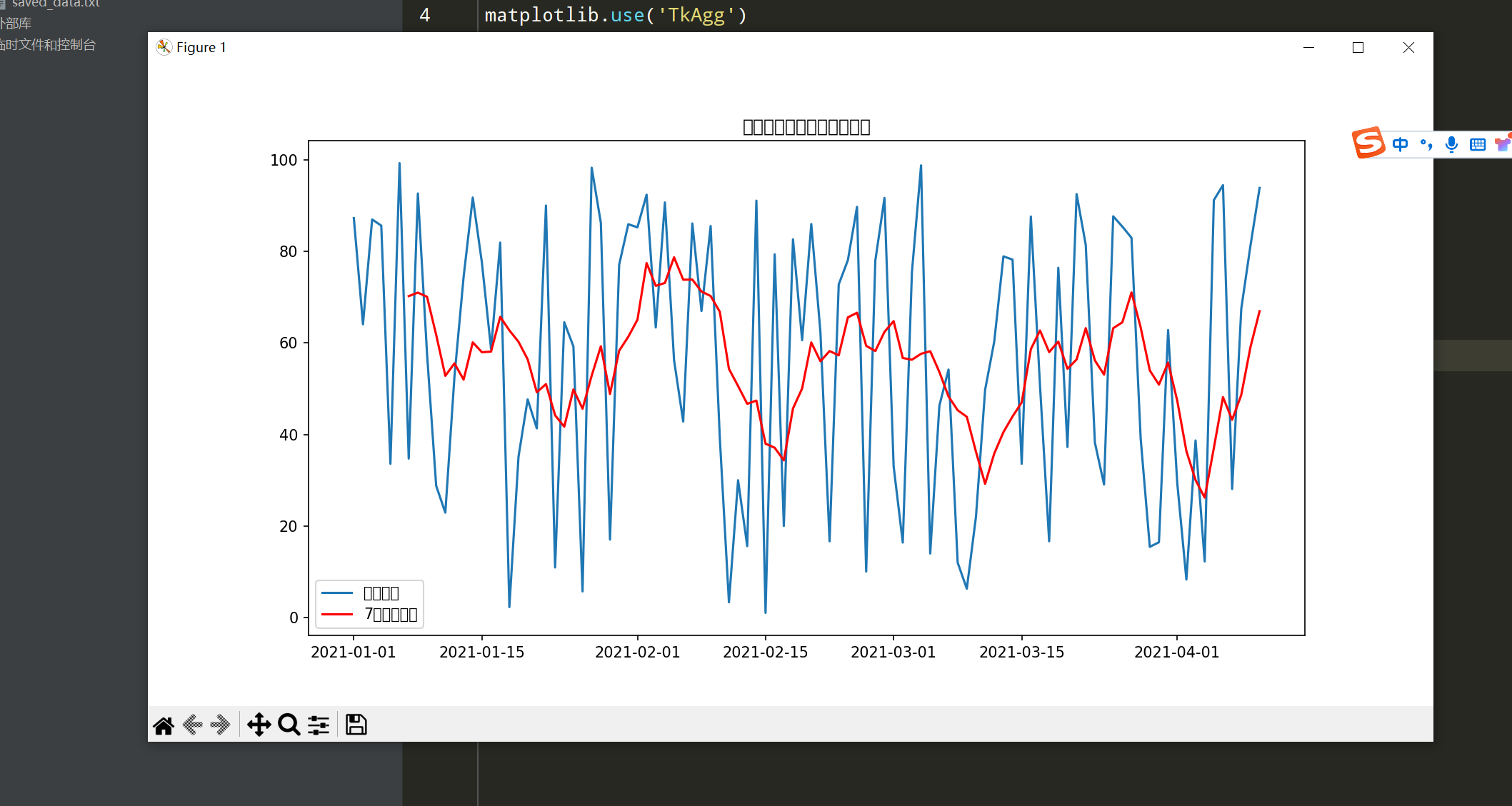
题目: 创建一个时间序列数据集,计算7天的移动平均,并绘制结果。
思路:
- 生成日期范围和随机数作为数据。
- 使用
rolling()函数计算移动平均。
import pandas as pd
import numpy as np
import matplotlib
matplotlib.use('TkAgg')
import matplotlib.pyplot as plt
# 生成日期范围
dates = pd.date_range(start='2021-01-01', periods=100)
data = np.random.rand(100) * 100 # 随机数据
# 创建时间序列
time_series = pd.Series(data, index=dates)
# 计算7天移动平均
moving_average = time_series.rolling(window=7).mean()
# 绘制结果
plt.figure(figsize=(12, 6))
plt.plot(time_series, label='原始数据')
plt.plot(moving_average, label='7天移动平均', color='red')
plt.title('时间序列数据及其移动平均')
plt.legend()
plt.show()代码解释:
- 生成随机数据作为时间序列,通过
rolling(window=7).mean()计算7天的移动平均。 - 使用Matplotlib绘制原始数据和移动平均结果。
4. 数据的标准化和归一化
题目: 对给定数据进行标准化和归一化处理,并比较结果。
思路:
- 使用
StandardScaler和MinMaxScaler进行标准化和归一化。
from sklearn.preprocessing import StandardScaler, MinMaxScaler
import pandas as pd
import numpy as np
# 生成随机数据
data = np.random.rand(10, 2) * 100
# 标准化
scaler_standard = StandardScaler()
data_standardized = scaler_standard.fit_transform(data)
# 归一化
scaler_minmax = MinMaxScaler()
data_normalized = scaler_minmax.fit_transform(data)
# 打印结果
print("原始数据:\n", data)
print("标准化结果:\n", data_standardized)
print("归一化结果:\n", data_normalized)代码解释:
- 使用
StandardScaler进行标准化处理,使数据均值为0,方差为1。 - 使用
MinMaxScaler进行归一化处理,将数据缩放到[0, 1]区间。
5. 统计分析—t检验
题目: 使用NumPy实现两个独立样本之间的t检验。
思路:
- 使用
scipy.stats.ttest_ind()进行t检验。
import numpy as np
from scipy import stats
# 生成两个独立样本
sample1 = np.random.normal(loc=50, scale=10, size=100)
sample2 = np.random.normal(loc=55, scale=10, size=100)
# 进行t检验
t_statistic, p_value = stats.ttest_ind(sample1, sample2)
print("t统计量:", t_statistic, "p值:", p_value)
代码解释:
- 生成两个正态分布的样本,通过
t检验比较两者均值的显著性。
6. 自定义函数应用于数组
题目: 创建一个自定义函数,对数组进行操作,并应用到数组上。
思路:
- 定义一个函数,计算数组每个元素的自定义操作。
# 自定义函数
def custom_operation(x):
return np.sin(x) + np.log(x + 1)
arr = np.linspace(0, 10, 100) # 生成0到10的线性空间
result = custom_operation(arr) # 应用自定义函数
# 绘制结果
plt.plot(arr, result)
plt.title('自定义操作结果')
plt.xlabel('x')
plt.ylabel('f(x)')
plt.grid()
plt.show()代码解释:
- 定义
custom_operation函数,计算sin与log的组合,生成结果并绘制。
7. 多维数组的归一化
题目: 对一个多维数组的每一列进行归一化处理。
思路:
- 自定义归一化函数并应用于每一列。
def normalize(arr):
return (arr - np.min(arr)) / (np.max(arr) - np.min(arr))
data = np.random.rand(5, 3) * 100 # 生成随机数据
normalized_data = np.apply_along_axis(normalize, axis=0, arr=data)
print("原始数据:\n", data)
print("归一化后的数据:\n", normalized_data)代码解释:
- 自定义
normalize函数,对数组进行列归一化,使用np.apply_along_axis应用于每一列。
8. 计算多项式拟合
题目: 使用NumPy对一组数据进行多项式拟合,并绘制结果。
思路:
- 使用
np.polyfit()拟合多项式,使用np.polyval()计算拟合值。
# 生成随机数据
np.random.seed(0)
x = np.linspace(0, 10, 30)
y = 2 * x + np.random.randn(30) * 2 # 添加噪声
# 多
项式拟合
coefficients = np.polyfit(x, y, 1) # 线性拟合
polynomial = np.poly1d(coefficients)
# 计算拟合值
y_fit = polynomial(x)
# 绘制结果
plt.scatter(x, y, label='数据点')
plt.plot(x, y_fit, color='red', label='拟合线')
plt.title('多项式拟合')
plt.legend()
plt.show()代码解释:
- 使用
np.polyfit()进行多项式拟合,生成拟合线并绘制原始数据和拟合结果。
9. 自定义聚类算法
题目: 实现简单的DBSCAN聚类算法。
思路:
- 编写DBSCAN聚类算法,处理距离和密度。
from sklearn.datasets import make_moons
from sklearn.cluster import DBSCAN
# 生成数据
X, y = make_moons(n_samples=300, noise=0.1)
# 应用DBSCAN聚类
dbscan = DBSCAN(eps=0.2, min_samples=5)
labels = dbscan.fit_predict(X)
# 可视化结果
plt.scatter(X[:, 0], X[:, 1], c=labels, cmap='rainbow')
plt.title('DBSCAN聚类结果')
plt.show()代码解释:
- 使用
sklearn中的make_moons生成非线性分布的数据,使用DBSCAN进行聚类并可视化结果。
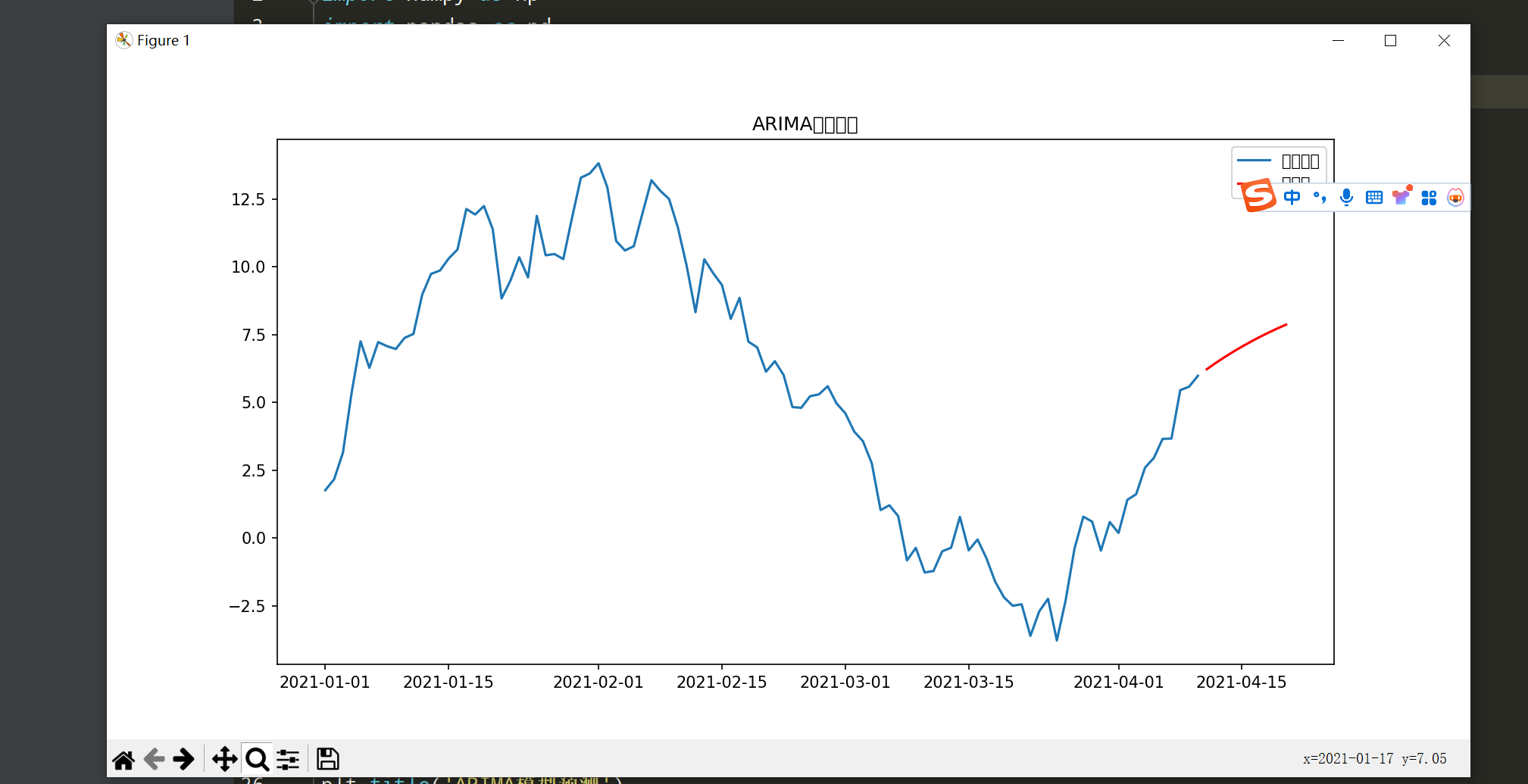
10. 时间序列分析与ARIMA模型
题目: 使用NumPy和StatsModels对时间序列数据进行ARIMA建模。
思路:
- 生成时间序列数据,使用ARIMA进行建模与预测。
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from statsmodels.tsa.arima.model import ARIMA
# 生成时间序列数据
np.random.seed(0)
time_series = np.random.randn(100).cumsum() # 随机游走生成序列
dates = pd.date_range(start='2021-01-01', periods=100)
ts = pd.Series(time_series, index=dates)
# 拟合ARIMA模型
model = ARIMA(ts, order=(1, 1, 1))
model_fit = model.fit()
# 进行预测
forecast = model_fit.forecast(steps=10)
# 绘制结果
plt.figure(figsize=(12, 6))
plt.plot(ts, label='原始数据')
plt.plot(forecast.index, forecast, label='预测值', color='red')
plt.title('ARIMA模型预测')
plt.legend()
plt.show()