
1基础
1- Python基础内容
1. 基本概念
- 解释型语言:Python 是一种解释型语言,代码运行时逐行解释执行。
- 动态类型:变量在运行时决定类型,无需声明。
2. 编码
定义:编码是将字符集转换为字节的方式。Python 3 默认使用 UTF-8 编码,能够支持多种语言的字符。
文件编码声明
:在文件顶部可以声明编码格式,尽管在Python 3中通常不需要,因为它默认是UTF-8,但为了兼容性,可以添加:
python Copy code # -*- coding: utf-8 -*-示例
:在字符串中使用中文字符。
pythonCopy codemessage = "你好,世界" print(message)
3. 标识符
定义:标识符用于命名变量、函数、类、模块等。
规则:
- 只能使用字母(A-Z、a-z)、数字(0-9)和下划线(_)。
- 不能以数字开头。
- 区分大小写(例如,
myVar和myvar是不同的)。 - 不能使用Python保留字(如
if,else,for,class等)。
示例:
pythonCopy codemy_variable = 10 # 合法 myVariable = 20 # 合法 1st_variable = 30 # 不合法,不能以数字开头
4. 变量命名
规则:遵循标识符的规则。
命名规范:
- 使用有意义的名称,以便代码可读。
- 对于变量名使用小写字母,多个单词用下划线分隔(如
total_sum)。 - 类名通常使用驼峰命名法(如
MyClass)。 - 常量(不变的值)通常使用全大写字母(如
MAX_SIZE)。
示例:
pythonCopy codeage = 25 # 合法变量 max_students = 30 # 合法变量名 class Student: # 合法类名 pass
5. 缩进
重要性:在Python中,缩进用于表示代码块,这意味着代码的结构依赖于缩进而非符号。
规则:
- 通常使用4个空格作为缩进,不建议混用空格和制表符。
- 在同一个代码块中,缩进量必须保持一致。
示例:
pythonCopy codeif condition: # 这个代码块缩进 do_something() if another_condition: do_something_else() # 进一步缩进
6. 注释
单行注释:使用
#开头。# 这是一个单行注释多行注释:使用三个引号(
'''或""")。''' 这是一个多行注释 可以用于注释多行代码 '''
7. 数据类型
基本数据类型:
- 整数(int)
- 浮点数(float)
- 字符串(str)
- 布尔值(bool)
复合数据类型:
- 列表(list)
- 元组(tuple)
- 字典(dict)
- 集合(set)
8. 变量
赋值操作:
x = 5 name = "Alice"
9. 运算符
算术运算符:
- 加(
+),减(-),乘(*),除(/),整除(//),取余(%),幂(**)
- 加(
比较运算符:
- 等于(
==),不等于(!=),大于(>),小于(<),大于等于(>=),小于等于(<=)
- 等于(
逻辑运算符:
- 与(
and),或(or),非(not)
- 与(
10. 控制结构
条件语句:
if condition: # 执行代码块 elif another_condition: # 执行其他代码块 else: # 执行备用代码块循环语句:
for 循环:
for i in range(5): print(i)while 循环:
while condition: # 执行代码块
11. 函数
定义函数:
def function_name(parameters): # 函数体 return value调用函数:
result = function_name(arguments)
12. 模块与包
导入模块:
import module_name from module_name import function_name
13. 异常处理
使用
try和except处理异常:try: # 可能会出错的代码 except SomeException: # 处理错误的代码
14. 文件操作
打开文件:
with open('filename.txt', 'r') as file: content = file.read()
15. 列表、元组、字典、集合的基本操作
列表:
my_list = [1, 2, 3] my_list.append(4) # 添加元素元组:
my_tuple = (1, 2, 3) # 不可变字典:
my_dict = {'key': 'value'} my_dict['new_key'] = 'new_value' # 添加键值对集合:
my_set = {1, 2, 3} my_set.add(4) # 添加元素
16. 列表推导式
简洁的创建列表:
squares = [x**2 for x in range(10)]
17. Lambda 函数
匿名函数:
add = lambda x, y: x + y
18. 类与对象
定义类:
class MyClass: def __init__(self, value): self.value = value def display(self): print(self.value)创建对象:
obj = MyClass(10) obj.display()
19. 常用内置函数
len():获取长度type():获取类型print():输出input():输入
2- 标识符
1. 标识符的定义
1.1 定义
标识符是用于命名变量、函数、类、模块、包等的名称。它们在程序中用于唯一标识这些元素,方便程序员进行引用和操作。
2. 标识符的规则
2.1 字符组成
- 标识符可以包含字母(A-Z、a-z)、数字(0-9)和下划线(_)。
- 标识符的第一个字符不能是数字。
2.2 长度限制
- 标识符的长度没有固定限制,但应该保持简短且有意义。
2.3 大小写敏感
- Python 区分大小写,因此
myVariable和myvariable是两个不同的标识符。
2.4 不能使用保留字
- Python 有一组保留字(关键字),这些词在语言中有特定的含义,不能用作标识符。常见的保留字包括
if,for,while,class,def,return等。
3. 标识符的命名规范
3.1 意义明确
- 选择能够反映变量用途的名称,例如
count、user_name等。
3.2 使用小写字母
- 常规变量使用小写字母,多个单词之间用下划线分隔(如
total_price)。
3.3 类名使用驼峰命名法
- 类名通常采用首字母大写的驼峰命名法(如
StudentRecord)。
3.4 常量全大写
- 常量(不变的值)通常使用全大写字母,单词之间用下划线分隔(如
MAX_SIZE)。
3.5 避免使用单字符命名
- 除非在循环或临时变量中,尽量避免使用单字符名称(如
x,y),应尽量使用更具描述性的名称。
4. 示例
好的,下面为 4.1 合法标识符 和 4.2 非法标识符 添加更多示例。
4.1 合法标识符
user_name = "Alice" # 小写字母和下划线
age = 30 # 字母和数字
MAX_SIZE = 100 # 常量,使用全大写
MyClass = "class_name" # 类名,使用驼峰命名法
total_price = 250.75 # 有意义的名称,描述了变量用途
is_valid = True # 布尔值变量,以 is 开头
student_count = 45 # 有描述性的变量名,使用下划线分隔
_user = "hidden" # 以下划线开头的变量名,常用于内部变量
PI = 3.14159 # 常量,用全大写字母表示
EmployeeID = "E12345" # 类名或特定变量的驼峰命名法
first_name = "John" # 多个单词用下划线分隔
x = 10 # 虽然单字符命名,但在某些情况下合法,例如循环变量4.2 非法标识符
1st_variable = 10 # 不合法,不能以数字开头
my-variable = 20 # 不合法,使用了非法字符(-)
class = "test" # 不合法,使用了保留字
@username = "admin" # 不合法,使用了非法字符(@)
def = "function" # 不合法,使用了保留字
first name = "Alice" # 不合法,包含空格
$salary = 5000 # 不合法,使用了非法字符($)
3d_model = "model1" # 不合法,数字不能在开头
global = "global_var" # 不合法,使用了保留字
if_ = "condition" # 不建议使用,虽然 `if_` 合法,但容易混淆5. 常见错误
5.1 使用保留字
- 确保没有使用Python的保留字作为标识符。
5.2 字符限制
- 确保标识符不以数字开头,并且不使用特殊字符(如
@,#,-,!)。
5.3 大小写问题
- 注意标识符的大小写,确保在引用时保持一致。
3- 变量命名
1. 变量命名的基本规则
在 Python 中,变量名必须遵循以下规则:
只能包含字母、数字和下划线,并且不能以数字开头。
- 示例:合法的变量名有
name,age23,school_name等。 - 不合法的变量名有
1name,school-name等。
- 示例:合法的变量名有
区分大小写。
age和Age是两个不同的变量。
不能使用 Python 的保留字,如
if,for,while,class等。- 示例:
for不能作为变量名,但可以用for_代替。
- 示例:
变量名应简洁且具有描述性,使代码更易读和维护。
2. 常用命名规范
2.1 使用下划线分隔单词(snake_case)
在 Python 中,通常采用小写字母和下划线分隔的方式(snake_case),这是一种广泛使用的变量命名方式。
示例:
user_name = "aini" # 使用小写字母和下划线分隔单词 age = 23 # 简单的变量名 university = "东华大学" # 简洁的描述性名称 city = "上海" # 描述性强的变量
2.2 使用全大写表示常量
通常在代码中,我们用全大写字母表示常量(不变的值)。常量名称中间用下划线分隔,这样的命名便于一眼看出该变量不应被修改。
示例:
MAX_AGE = 100 # 假设这是某个最大年龄限制 BIRTH_YEAR = 2000 # 假设你的出生年份
3. 一些举例
根据你的个人信息,以下是一些合理的变量命名示例:
# 基本个人信息
name = "aini" # 存储名字
age = 23 # 存储年龄
university_name = "东华大学" # 存储大学名称
city_of_residence = "上海" # 存储居住城市
# 更详细的信息(扩展为描述性变量)
birth_year = 2000 # 假设你的出生年份
hobby_list = ["阅读", "运动"] # 兴趣爱好,可以用列表形式
is_student = True # 布尔变量,表示是否为学生
graduation_year = 2025 # 假设毕业年份4. 常见变量命名的类别与规范
4.1 布尔值命名
布尔值(True 或 False)的变量通常用 is_ 或 has_ 开头,表示状态或特性。
示例:
is_student = True # 表示是否是学生 has_scholarship = False # 表示是否有奖学金 is_graduated = False # 表示是否已毕业
4.2 列表和集合的命名
如果一个变量存储多个值(如兴趣爱好、已修课程等),可以用复数形式或 _list 结尾。
示例:
hobbies = ["阅读", "运动"] # 兴趣爱好 completed_courses = ["数学", "物理"] # 已修课程 friend_names = ["李明", "王芳"] # 朋友的名字
4.3 使用描述性强的名字
变量命名时,尽量选择能够反映变量内容的名字,不要过于简短或模糊。比如,name 可以更明确为 user_name 或 student_name。
示例:
user_name = "aini" # 用户名 current_city = "上海" # 当前居住城市 enrolled_university = "东华大学" # 所在大学
5. 不推荐的命名方式
使用无意义的单字符变量名(除非在循环中,通常我们避免使用单字符变量名)。
- 如
a = 23,n = "东华大学",这种命名方式信息不明确。
- 如
混用大小写(除非明确需要区分大小写),过多的大小写会影响可读性。
- 如
MyName = "aini",AGE23 = 23,不推荐在普通变量中使用驼峰或全大写,容易误解。
- 如
模糊的缩写,除非缩写很常用,否则避免使用不直观的缩写。
- 如
usr = "aini"可能代表用户(user),但最好用user_name这样更清晰。
- 如
6. 结合示例的完整代码
综合以上命名规则,以下是一段 Python 代码示例:
# 基本信息
user_name = "aini" # 用户名
age = 23 # 年龄
university_name = "东华大学" # 大学名称
city_of_residence = "上海" # 居住城市
birth_year = 2000 # 出生年份
is_student = True # 是否为学生
graduation_year = 2025 # 预计毕业年份
# 扩展信息
hobby_list = ["阅读", "运动"] # 兴趣爱好
has_scholarship = False # 是否有奖学金
completed_courses = ["数学", "物理"] # 已修课程
friend_names = ["李明", "王芳"] # 朋友名字列表4- 缩进和注释
1. 缩进
1.1 缩进的定义和作用
在 Python 中,缩进用于标识代码块。与许多编程语言不同,Python 没有用 {} 来包裹代码块,而是依靠缩进来确定层次结构。因此,缩进在 Python 中是强制的,它不仅用于代码的可读性,还决定了代码的执行结构。
1.2 缩进的基本规则
缩进一致性:在同一个代码块中,所有缩进必须保持一致。Python 的默认缩进规范是 4 个空格,也可以用一个 Tab 键,但不能混合使用。
代码块结构:Python 通过缩进来识别不同的代码块。例如,在
if、for、while等语句后面缩进的部分被认为是属于这些语句的代码块。
1.3 缩进示例
以 if 语句为例,来看一下如何使用缩进来定义代码块:
age = 23
if age >= 18:
print("你已成年") # 这个缩进属于 if 语句的代码块
print("可以参与投票") # 这个也是 if 语句的代码块
else:
print("你未成年") # 这个属于 else 语句的代码块在上面的代码中,if 和 else 语句下面的代码都缩进了 4 个空格,这表示这些缩进的代码是属于各自条件的代码块。
1.4 缩进错误示例
如果缩进不一致或不符合 Python 规范,就会导致 IndentationError 错误。
if age >= 18:
print("你已成年")
print("可以参与投票") # 不一致的缩进,将导致 IndentationError在这个例子中,第二行和第三行的缩进不一致(一个是 4 个空格,另一个是 5 个空格),Python 会报错。
1.5 嵌套缩进
当代码块有多层嵌套时,每一层嵌套都需要再缩进一次,通常每一层使用 4 个空格。
age = 23
is_student = True
if age >= 18:
print("你已成年")
if is_student:
print("你是成年学生") # 进一步嵌套的代码块,每层缩进 4 个空格
else:
print("你不是学生")
else:
print("你未成年")在这个例子中,if 语句中的嵌套 if 和 else 语句都进一步缩进了 4 个空格。
2. 注释
注释是对代码的解释说明,用于帮助开发者理解代码的作用和逻辑。Python 支持单行注释和多行注释。
2.1 单行注释
在 Python 中,单行注释使用 # 符号。# 后的内容不会被 Python 解释器执行,通常用于解释代码行的功能。
用法:
#后面可以跟任何注释内容。通常单行注释会放在代码上方或者旁边。示例:
age = 23 # 定义年龄变量,值为23多行单行注释:如果需要多行注释,但每行只有简单的注释内容,可以在每行前面加
#。# 这是一个多行注释 # 说明这段代码的作用 # 以及每行的功能
2.2 多行注释
多行注释在 Python 中通常使用三个单引号 ''' 或三个双引号 """ 括起来的内容。这种方式的注释主要用于函数或类的文档字符串(docstring),也可以用于多行注释,但在一般代码中单行注释更为常见。
用法:在代码块前或后使用
'''注释内容'''或"""注释内容"""包裹多行注释。示例:
''' 这是一个多行注释 可以用来描述整个函数的作用 或者解释代码逻辑 '''
2.3 函数和类的文档字符串(docstring)
当编写函数、类或模块时,建议在定义的第一行使用多行注释来描述它的功能。这样可以为函数或类提供文档说明,方便其他人了解它的用途。
函数文档字符串示例:
def greet_user(name): """打印问候用户的消息""" print(f"你好, {name}")类文档字符串示例:
class Student: """这是一个学生类,用于存储学生的基本信息""" def __init__(self, name, age): """初始化学生的名字和年龄""" self.name = name self.age = age
2.4 注释的规范与最佳实践
注释要简洁明了:注释应该清楚明白地解释代码的意图,而不是重复代码本身。例如,以下注释是多余的:
count = 0 # 将计数变量设置为0可以改为:
count = 0 # 记录用户的数量注释重要逻辑或复杂代码:对于重要的代码逻辑和复杂的部分,应提供详细的解释。
避免过多注释:不要在每一行都添加注释,过多的注释会影响可读性。只在关键地方添加注释即可。
3. 结合缩进和注释的代码示例
结合缩进和注释,以下是一个示例代码,展示了如何使用合理的缩进和注释来编写清晰、易读的 Python 代码:
def check_eligibility(age, city):
"""
检查用户的资格,根据年龄和所在城市决定是否符合条件
参数:
age (int): 用户的年龄
city (str): 用户所在的城市
返回:
bool: 如果符合资格返回 True,否则返回 False
"""
# 判断年龄是否大于等于18
if age >= 18:
# 如果年龄合格,继续检查城市
if city == "上海":
return True # 满足条件,返回 True
else:
return False # 城市不符合条件,返回 False
else:
return False # 年龄不符合条件,返回 False
# 调用函数并打印结果
user_age = 23
user_city = "上海"
is_eligible = check_eligibility(user_age, user_city) # 检查用户是否符合资格
print(is_eligible) # 打印结果在这个示例中:
- 缩进:代码中使用 4 个空格来缩进每个代码块,保持一致性。
- 注释:代码中的每个逻辑步骤都配有简洁明了的注释,文档字符串则详细说明了函数的用途和参数。
5- 数据类型
1. 基本数据类型
Python 的基本数据类型包括整数(int)、浮点数(float)、布尔值(bool)、字符串(str)等。
1.1 整数(int)
定义:整数是没有小数部分的数,可以是正数、负数或零。
表示:Python 中的整数可以表示任意大小,因为 Python 会根据需要自动扩展整数的存储空间。
示例:
age = 23 # 整数 temperature = -5 # 负整数 big_number = 1000000 # 大整数常用操作:
- 加法:
a + b - 减法:
a - b - 乘法:
a * b - 整除:
a // b(返回商的整数部分) - 取余:
a % b(返回除法的余数) - 幂运算:
a ** b(a 的 b 次幂)
- 加法:
1.2 浮点数(float)
定义:浮点数是带小数部分的数字,通常用于表示小数或科学计数法形式的数。
精度问题:由于计算机内部的存储机制,浮点数的精度有限,可能出现误差。
示例:
price = 19.99 # 小数 pi = 3.14159 # 常见的浮点数 scientific_notation = 1.23e4 # 科学计数法表示,等价于 1.23 * 10^4常用操作:与整数的操作相同,不过浮点数除法结果为浮点数。
1.3 布尔值(bool)
定义:布尔值只有
True和False两个值,通常用于逻辑判断。表达式:布尔值通常通过条件表达式得到,如
a > b、a == b等。示例:
is_student = True # 表示是否为学生 has_scholarship = False # 表示是否有奖学金常用操作:
- 与(and):
True and False返回False - 或(or):
True or False返回True - 非(not):
not True返回False
- 与(and):
1.4 字符串(str)
定义:字符串是由字符组成的序列,通常用于表示文本信息。
表示:可以使用单引号(
')、双引号(")或三重引号('''或""")定义。示例:
name = "aini" # 使用双引号 greeting = 'Hello' # 使用单引号 long_text = """这是一个多行字符串 可以换行显示"""常用操作:
- 字符串拼接:
"Hello" + " World"->"Hello World" - 重复:
"Hi" * 3->"HiHiHi" - 取子串:
"Hello"[1:4]->"ell" - 常用方法:
len("Hello")、"hello".upper()、"WORLD".lower()、"Hello World".split()。
- 字符串拼接:
2. 复合数据类型
复合数据类型包括列表(list)、元组(tuple)、字典(dict)和集合(set)。它们可以用来存储多个值,方便处理复杂的数据结构。
2.1 列表(list)
定义:列表是一个有序的可变序列,可以存储多个元素,元素之间用逗号分隔。
表示:列表使用方括号
[]表示。示例:
hobbies = ["阅读", "运动", "音乐"] # 定义一个包含多个元素的列表 numbers = [1, 2, 3, 4, 5] # 定义一个数字列表 mixed_list = ["aini", 23, True] # 可以包含不同类型的元素常用操作:
- 访问元素:
hobbies[0]->"阅读" - 修改元素:
hobbies[1] = "跑步" - 添加元素:
hobbies.append("电影") - 删除元素:
hobbies.remove("运动") - 列表切片:
numbers[1:3]->[2, 3]
- 访问元素:
2.2 元组(tuple)
定义:元组是一个有序的不可变序列,一旦定义无法修改,通常用于存储不会改变的数据。
表示:元组使用小括号
()表示。示例:
coordinates = (30.0, 50.0) # 定义一个坐标元组 personal_info = ("aini", 23, "上海") # 存储不可变的个人信息 single_item_tuple = (42,) # 包含一个元素的元组,后面需加逗号常用操作:
- 访问元素:
coordinates[0]->30.0 - 元组解包:
x, y = coordinates->x = 30.0, y = 50.0
- 访问元素:
2.3 字典(dict)
定义:字典是一个无序的键值对集合,使用键(key)来访问对应的值(value),键必须是唯一的。
表示:字典使用大括号
{}表示,每个键值对用冒号:分隔。示例:
student_info = { "name": "aini", "age": 23, "city": "上海", "university": "东华大学" }常用操作:
- 访问值:
student_info["name"]->"aini" - 修改值:
student_info["age"] = 24 - 添加键值对:
student_info["major"] = "计算机科学" - 删除键值对:
del student_info["city"] - 获取键集合:
student_info.keys() - 获取值集合:
student_info.values()
- 访问值:
2.4 集合(set)
定义:集合是一个无序、唯一的元素集合,主要用于去重和集合运算。
表示:集合使用大括号
{}表示,元素之间用逗号分隔,或使用set()函数创建空集合。示例:
unique_numbers = {1, 2, 3, 4, 5, 5} # 集合会自动去重 empty_set = set() # 使用 set() 创建空集合常用操作:
- 添加元素:
unique_numbers.add(6) - 删除元素:
unique_numbers.remove(2) - 并集:
set1 | set2 - 交集:
set1 & set2 - 差集:
set1 - set2 - 对称差集:
set1 ^ set2
- 添加元素:
3. 特殊数据类型:NoneType
定义:
NoneType是一个特殊的空值类型,只有一个值None,用于表示“什么都没有”。用途:
None常用于表示缺失值、空返回值等。示例:
result = None # 初始值为 None,表示还没有结果
6- 运算符
6.1 算术运算符(掌握)
算术运算符用于进行数学计算,包括加、减、乘、除等基本操作。它们是编程中最常用的运算符。
常见的算术运算符:
运算符 描述 示例 结果 +加法 3 + 25-减法 3 - 21*乘法 3 * 26/除法 3 / 21.5//整除 3 // 21%取余 3 % 21**幂运算 3 ** 29示例代码:
a = 10 b = 3 print(a + b) # 输出 13 print(a - b) # 输出 7 print(a * b) # 输出 30 print(a / b) # 输出 3.3333333333333335 print(a // b) # 输出 3 print(a % b) # 输出 1 print(a ** b) # 输出 1000
6.2 比较运算符(掌握)
比较运算符用于比较两个值,结果返回布尔值 True 或 False,在条件判断中非常常用。
常见的比较运算符:
运算符 描述 示例 结果 ==等于 3 == 2False!=不等于 3 != 2True>大于 3 > 2True<小于 3 < 2False>=大于等于 3 >= 2True<=小于等于 3 <= 2False示例代码:
x = 5 y = 10 print(x == y) # 输出 False print(x != y) # 输出 True print(x > y) # 输出 False print(x < y) # 输出 True print(x >= y) # 输出 False print(x <= y) # 输出 True
6.3 赋值运算符(掌握)
赋值运算符用于将值赋给变量,并支持自加、自减、自乘等简便操作。是编程中非常基础且常用的运算符。
常见的赋值运算符:
运算符 描述 示例 等价于 =赋值 x = 5x = 5+=加赋值 x += 3x = x + 3-=减赋值 x -= 3x = x - 3*=乘赋值 x *= 3x = x * 3/=除赋值 x /= 3x = x / 3//=整除赋值 x //= 3x = x // 3%=取余赋值 x %= 3x = x % 3**=幂赋值 x **= 3x = x ** 3示例代码:
x = 10 x += 5 # 等价于 x = x + 5,结果为 15 x -= 3 # 等价于 x = x - 3,结果为 12 x *= 2 # 等价于 x = x * 2,结果为 24 x /= 4 # 等价于 x = x / 4,结果为 6.0
6.4 逻辑运算符(掌握)
逻辑运算符用于组合多个条件,返回布尔值 True 或 False,在条件判断和控制结构中十分常用。
常见的逻辑运算符:
运算符 描述 示例 结果 and逻辑与 True and FalseFalseor逻辑或 True or FalseTruenot逻辑非 not TrueFalse示例代码:
a = True b = False print(a and b) # 输出 False print(a or b) # 输出 True print(not a) # 输出 False
6.5 位运算符(了解)
位运算符用于直接操作二进制位,主要用于底层编程或硬件控制,对一般的应用程序开发不常用。
常见的位运算符:
运算符 描述 示例 结果 &按位与 5 & 31` ` 按位或 `5 ^按位异或 5 ^ 36~按位取反 ~5-6<<左移 5 << 110>>右移 5 >> 12示例代码:
a = 5 # 二进制为 0101 b = 3 # 二进制为 0011 print(a & b) # 输出 1(二进制为 0001) print(a | b) # 输出 7(二进制为 0111) print(a ^ b) # 输出 6(二进制为 0110) print(~a) # 输出 -6(二进制为 -0110,补码表示) print(a << 1) # 输出 10(二进制为 1010) print(a >> 1) # 输出 2(二进制为 0010)
6.6 成员运算符(掌握)
成员运算符用于检查某个值是否存在于序列(如列表、元组、字符串)中,返回布尔值 True 或 False,在数据结构操作中非常常用。
常见的成员运算符:
运算符 描述 示例 结果 in在序列中 'a' in 'apple'Truenot in不在序列中 'b' not in 'apple'True示例代码:
fruits = ["apple", "banana", "cherry"] print("apple" in fruits) # 输出 True print("grape" not in fruits) # 输出 True
6.7 身份运算符(了解)
身份运算符用于比较两个对象的内存地址,判断它们是否是同一个对象。适合在需要比较对象身份的场景中使用,常
用于对象的内存管理。
常见的身份运算符:
运算符 描述 示例 结果 is是同一个对象 a is bTrue或Falseis not不是同一个对象 a is not bTrue或False示例代码:
x = [1, 2, 3] y = x z = [1, 2, 3] print(x is y) # 输出 True,因为 y 和 x 是同一个对象 print(x is z) # 输出 False,因为 z 是另一个列表,虽然内容相同 print(x == z) # 输出 True,因为 x 和 z 的内容相同
6.8 运算符优先级(掌握)
运算符优先级决定了运算符的执行顺序,优先级高的运算符会先执行。在复合运算中,理解运算符优先级可以帮助我们正确书写表达式。
运算符优先级(从高到低):
- 指数运算符:
** - 按位取反、逻辑非:
~,not - 乘除、取余、整除:
*,/,//,% - 加减:
+,- - 移位运算符:
<<,>> - 比较运算符:
<,<=,>,>= - 等于运算符:
==,!= - 位运算符:
&,^,| - 逻辑运算符:
and,or - 赋值运算符:
=,+=,-=,*=,/=,%=等
- 指数运算符:
万能方法:实在搞不清优先级,那就用(),希望先计算的用() 括起来
7- 字符串
7.1 字符串的定义(掌握)
字符串是一种由字符组成的不可变序列,用于表示文本数据。在 Python 中,字符串可以使用单引号 '、双引号 " 或三引号 '''/""" 来定义。
单引号和双引号:用于定义单行字符串,二者功能一致。
name = 'aini' greeting = "Hello"三引号:用于定义多行字符串,适合长文本或多行注释。
long_text = """这是一个 多行字符串"""
7.2 字符串的基本操作(掌握)
7.2.1 字符串拼接
使用
+运算符将多个字符串拼接在一起。first_name = "aini" last_name = "Zhang" full_name = first_name + " " + last_name # 输出 'aini Zhang'
7.2.2 字符串重复
使用
*运算符将字符串重复多次。repeated = "Hello" * 3 # 输出 'HelloHelloHello'
7.2.3 字符串长度
使用
len()函数获取字符串的字符数。message = "Hello, World!" print(len(message)) # 输出 13
7.2.4 字符串索引与切片
索引:使用索引访问字符串中的单个字符,索引从 0 开始,支持负索引。
text = "Python" print(text[0]) # 输出 'P' print(text[-1]) # 输出 'n'切片:使用切片获取字符串中的部分内容,格式为
字符串[起始:结束:步长]。text = "Python" print(text[1:4]) # 输出 'yth' print(text[:3]) # 输出 'Pyt' print(text[::2]) # 输出 'Pto' print(text[::-1]) # 输出 'nohtyP'(字符串反转)
7.3 字符串的常用方法(掌握)
Python 提供了丰富的字符串方法,以下是常用的字符串方法,主要用于字符串的处理和格式化。
7.3.1 upper() 和 lower():转换大小写
upper():将字符串全部转换为大写。lower():将字符串全部转换为小写。text = "Hello World" print(text.upper()) # 输出 'HELLO WORLD' print(text.lower()) # 输出 'hello world'
7.3.2 strip():去除空白字符
strip():去除字符串两端的空白字符(包括空格、换行符等)。lstrip():去除左侧空白字符。rstrip():去除右侧空白字符。text = " Hello World " print(text.strip()) # 输出 'Hello World' print(text.lstrip()) # 输出 'Hello World ' print(text.rstrip()) # 输出 ' Hello World'
7.3.3 replace():替换子字符串
replace(old, new):将字符串中的old替换为new。text = "Hello World" print(text.replace("World", "Python")) # 输出 'Hello Python'
7.3.4 split() 和 join():拆分与合并字符串
split(separator):根据指定的分隔符将字符串拆分成列表。如果不指定分隔符,默认按空白字符拆分。text = "Hello World" print(text.split()) # 输出 ['Hello', 'World'] print(text.split('o')) # 输出 ['Hell', ' W', 'rld']join(iterable):将可迭代对象中的元素连接成一个字符串,以调用者作为分隔符。words = ["Hello", "Python", "World"] print(" ".join(words)) # 输出 'Hello Python World'
7.3.5 find() 和 index():查找子字符串
find(sub):查找子字符串sub的位置,找到则返回索引,否则返回 -1。index(sub):与find类似,但如果找不到会引发ValueError。text = "Hello World" print(text.find("World")) # 输出 6 print(text.index("World")) # 输出 6
7.4 字符串格式化(掌握)
Python 提供了多种格式化字符串的方法,便于拼接变量和字符串。
7.4.1 f-string 格式化(Python 3.6 及以上)
使用
f"{变量}"的方式嵌入变量,非常直观且易读。name = "aini" age = 23 message = f"Hello, my name is {name} and I am {age} years old." print(message) # 输出 'Hello, my name is aini and I am 23 years old.'
7.4.2 str.format() 方法
使用
{}占位符,并在字符串末尾调用.format()方法填充变量。name = "aini" age = 23 message = "Hello, my name is {} and I am {} years old.".format(name, age) print(message) # 输出 'Hello, my name is aini and I am 23 years old.'
7.4.3 百分号 % 格式化(旧方法)
使用
%运算符来进行格式化,在旧代码中仍然常见。name = "aini" age = 23 message = "Hello, my name is %s and I am %d years old." % (name, age) print(message) # 输出 'Hello, my name is aini and I am 23 years old.'
7.5 字符串的编码与解码(了解)
编码与解码用于将字符串转换为字节或将字节转换为字符串。通常用于处理文件、网络传输和多语言文本处理。
7.5.1 encode():编码字符串
encode(encoding):将字符串转换为指定编码格式的字节对象(bytes)。text = "Hello" byte_text = text.encode("utf-8") print(byte_text) # 输出 b'Hello'
7.5.2 decode():解码字节
decode(encoding):将字节对象转换回指定编码格式的字符串。byte_text = b'Hello' text = byte_text.decode("utf-8") print(text) # 输出 'Hello'
7.6 字符串的常见检查方法(掌握)
用于判断字符串是否符合特定格式或内容。
7.6.1 isalpha():检查是否全为字母
返回
True如果字符串只包含字母且非空,否则返回False。text = "Hello" print(text.isalpha()) # 输出 True
7.6.2 isdigit():检查是否全为数字
返回
True如果字符串只包含数字且非空,否则返回False。text = "12345" print(text.isdigit()) # 输出 True
7.6.3 isalnum():检查是否全为字母和数字
返回
True如果字符串只包含字母和数字且非空,否则返回False。text = "Hello123" print(text.isalnum()) # 输出 True
7.6.4 isspace():检查是否全为空白字符
返回
True如果字符串只包含空白字符(如空格、制表符)且非空,否则返回False。text = " " print(text.isspace()) # 输出 True
8- 列表
8.1 列表的定义(掌握)
列表是一个有序的、可变的序列,可以包含任意类型的元素。列表是 Python 中最常用的数据结构之一,适合存储一系列数据。列表用方括号 [] 表示,元素之间用逗号分隔。
定义列表:
empty_list = [] # 空列表 numbers = [1, 2, 3, 4, 5] # 包含整数的列表 mixed_list = [1, "hello", 3.14, True] # 混合数据类型的列表
8.2 列表的基本操作(掌握)
列表支持多种基本操作,如访问、修改、添加和删除元素。
8.2.1 访问元素
使用索引访问列表中的元素,索引从 0 开始,支持负索引。
numbers = [1, 2, 3, 4, 5] print(numbers[0]) # 输出 1 print(numbers[-1]) # 输出 5(最后一个元素)
8.2.2 修改元素
使用索引修改列表中的元素。
numbers = [1, 2, 3, 4, 5] numbers[0] = 10 print(numbers) # 输出 [10, 2, 3, 4, 5]
8.2.3 列表切片
使用切片获取列表中的一部分,格式为
列表[起始:结束:步长]。numbers = [1, 2, 3, 4, 5] print(numbers[1:4]) # 输出 [2, 3, 4] print(numbers[:3]) # 输出 [1, 2, 3] print(numbers[::2]) # 输出 [1, 3, 5] print(numbers[::-1]) # 输出 [5, 4, 3, 2, 1](列表反转)
8.2.4 列表长度
使用
len()函数获取列表的长度。numbers = [1, 2, 3, 4, 5] print(len(numbers)) # 输出 5
8.3 列表的常用方法(掌握)
Python 提供了多种方法来操作列表,这些方法可以帮助我们对列表进行添加、删除、查找等操作。
8.3.1 append():添加元素到列表末尾
使用
append()方法将元素添加到列表的末尾。numbers = [1, 2, 3] numbers.append(4) print(numbers) # 输出 [1, 2, 3, 4]
8.3.2 insert():在指定位置插入元素
使用
insert(index, element)方法在指定位置插入元素。numbers = [1, 2, 3] numbers.insert(1, "hello") print(numbers) # 输出 [1, 'hello', 2, 3]
8.3.3 extend():扩展列表
使用
extend()方法将一个列表的所有元素添加到另一个列表末尾。numbers = [1, 2, 3] more_numbers = [4, 5, 6] numbers.extend(more_numbers) print(numbers) # 输出 [1, 2, 3, 4, 5, 6]
8.3.4 remove():删除指定元素
使用
remove(element)方法删除列表中的第一个匹配的元素。如果元素不存在,会引发ValueError。numbers = [1, 2, 3, 2, 4] numbers.remove(2) print(numbers) # 输出 [1, 3, 2, 4]
8.3.5 pop():弹出指定位置的元素
使用
pop(index)方法删除并返回指定位置的元素。如果不指定索引,默认删除并返回最后一个元素。numbers = [1, 2, 3, 4] last_element = numbers.pop() print(numbers) # 输出 [1, 2, 3] print(last_element) # 输出 4
8.3.6 clear():清空列表
使用
clear()方法删除列表中的所有元素。numbers = [1, 2, 3, 4] numbers.clear() print(numbers) # 输出 []
8.3.7 index():查找元素的索引
使用
index(element)方法返回元素在列表中的第一个匹配索引。如果元素不存在,会引发ValueError。numbers = [1, 2, 3, 4] print(numbers.index(3)) # 输出 2
8.3.8 count():统计元素出现次数
使用
count(element)方法统计指定元素在列表中出现的次数。numbers = [1, 2, 2, 3, 4] print(numbers.count(2)) # 输出 2
8.3.9 sort() 和 sorted():排序
使用
sort()方法对列表进行原地排序,改变原列表。可以传入reverse=True参数降序排序。使用
sorted()函数返回一个排序后的新列表,不改变原列表。numbers = [3, 1, 4, 2] numbers.sort() print(numbers) # 输出 [1, 2, 3, 4] numbers = [3, 1, 4, 2] sorted_numbers = sorted(numbers, reverse=True) print(sorted_numbers) # 输出 [4, 3, 2, 1]
8.3.10 reverse():反转列表
使用
reverse()方法将列表中的元素顺序反转,改变原列表。numbers = [1, 2, 3, 4] numbers.reverse() print(numbers) # 输出 [4, 3, 2, 1]
8.4 列表的生成式(掌握)
列表生成式(List Comprehension)是一种简洁的生成列表的方法,可以用一行代码创建一个新的列表,常用于数据处理和过滤。
基本语法:
[表达式 for 变量 in 可迭代对象 if 条件]示例:
squares = [x**2 for x in range(1, 6)] print(squares) # 输出 [1, 4, 9, 16, 25] even_numbers = [x for x in range(10) if x % 2 == 0] print(even_numbers) # 输出 [0, 2, 4, 6, 8]
8.5 列表的嵌套(掌握)
列表可以包含其他列表,形成嵌套结构,用于表示二维或多维数据。
示例:
matrix = [ [1, 2, 3], [4, 5, 6], [7, 8, 9] ] print(matrix[1][2]) # 输出 6,访问第2行第3列
8.6 列表的拷贝(了解)
列表的拷贝分为浅拷贝和深拷贝。
8.6.1 浅拷贝
浅拷贝只复制列表的第一层元素,嵌套的列表仍然是引用。
original = [1, [2, 3], 4] shallow_copy = original.copy() shallow_copy[1][0] = 99 print(original) # 输出 [1, [99, 3], 4]
8.6.2 深拷贝
深拷贝递归地复制所有层级的元素,使用
copy模块中的deepcopy()实现。import copy original =
[1, [2, 3], 4] deep_copy = copy.deepcopy(original) deep_copy[1][0] = 99 print(original) # 输出 [1, [2, 3], 4]
---
### 8.7 列表和其他数据类型的转换(了解)
Python 提供了多种内置函数,可以将其他数据类型转换为列表。
- **字符串转列表**:使用 `list()` 将字符串的每个字符转为列表元素。
```python
text = "hello"
text_list = list(text)
print(text_list) # 输出 ['h', 'e', 'l', 'l', 'o']元组转列表:使用
list()将元组转换为列表。tuple_data = (1, 2, 3) list_data = list(tuple_data) print(list_data) # 输出 [1, 2, 3]集合转列表:使用
list()将集合转换为列表。set_data = {1, 2, 3} list_data = list(set_data) print(list_data) # 输出 [1, 2, 3]
9- 元祖
9.1 元组的定义(掌握)
元组是一种有序的、不可变的数据结构,可以存储多个元素。与列表类似,元组可以包含任意数据类型,但元组一旦创建,不能修改。元组使用小括号 () 表示,元素之间用逗号分隔。
定义元组:
empty_tuple = () # 空元组 single_element_tuple = (42,) # 单个元素的元组,需在元素后加逗号 numbers = (1, 2, 3, 4, 5) # 包含多个元素的元组 mixed_tuple = (1, "hello", 3.14) # 包含不同数据类型的元组
9.2 元组的基本操作(掌握)
虽然元组是不可变的,但我们可以通过索引和切片访问其中的元素。
9.2.1 访问元组元素
使用索引访问元组中的单个元素,索引从 0 开始,支持负索引。
numbers = (1, 2, 3, 4, 5) print(numbers[0]) # 输出 1 print(numbers[-1]) # 输出 5(最后一个元素)
9.2.2 元组切片
使用切片获取元组中的一部分,格式为
元组[起始:结束:步长]。numbers = (1, 2, 3, 4, 5) print(numbers[1:4]) # 输出 (2, 3, 4) print(numbers[:3]) # 输出 (1, 2, 3) print(numbers[::2]) # 输出 (1, 3, 5) print(numbers[::-1]) # 输出 (5, 4, 3, 2, 1)(元组反转)
9.2.3 元组长度
使用
len()函数获取元组的长度。numbers = (1, 2, 3, 4, 5) print(len(numbers)) # 输出 5
9.3 元组的常用方法(掌握)
元组提供的内置方法不多,主要用于基本操作,如统计元素出现次数和查找元素索引。
9.3.1 count():统计元素出现次数
使用
count(element)方法统计指定元素在元组中出现的次数。numbers = (1, 2, 2, 3, 4) print(numbers.count(2)) # 输出 2
9.3.2 index():查找元素的索引
使用
index(element)方法返回指定元素在元组中的第一个匹配索引。如果元素不存在,会引发ValueError。numbers = (1, 2, 3, 4) print(numbers.index(3)) # 输出 2
9.4 元组的不可变性(掌握)
元组的不可变性是其最重要的特性。元组一旦创建,元素就不能被修改、添加或删除。这一特性使元组在需要不可变数据时特别有用,例如作为函数返回多个值或将元组作为字典的键。
示例:
numbers = (1, 2, 3) # numbers[0] = 10 # 会引发 TypeError,因为元组不可变
9.5 元组解包(掌握)
元组解包是一种将元组中的元素直接赋值给多个变量的方式,非常方便。
示例:
coordinates = (10, 20) x, y = coordinates print(x) # 输出 10 print(y) # 输出 20应用场景:当一个函数返回多个值时,可以直接解包到多个变量中。
def get_point(): return (5, 10) x, y = get_point() print(x, y) # 输出 5 10
9.6 元组的嵌套(掌握)
元组可以包含其他元组,形成嵌套结构,适合表示多维数据或层级结构的数据。
示例:
nested_tuple = ((1, 2, 3), (4, 5, 6), (7, 8, 9)) print(nested_tuple[1][2]) # 输出 6,访问第2行第3列
9.7 元组与列表的转换(掌握)
在 Python 中可以使用 tuple() 和 list() 进行元组与列表的相互转换,方便在需要可变或不可变数据时灵活切换。
列表转换为元组:
numbers_list = [1, 2, 3] numbers_tuple = tuple(numbers_list) print(numbers_tuple) # 输出 (1, 2, 3)元组转换为列表:
numbers_tuple = (1, 2, 3) numbers_list = list(numbers_tuple) print(numbers_list) # 输出 [1, 2, 3]
9.8 元组的使用场景(掌握)
由于元组不可变,且比列表更高效,因此在以下场景中更适合使用元组:
- 多值返回:函数返回多个值时,可以将它们放在一个元组中。
- 字典键:元组可以作为字典的键(因为元组是不可变类型),而列表不行。
- 不需要修改的数据:当数据不需要修改时,用元组可以避免数据被意外改变,提高代码的安全性和可读性。
示例:函数返回多个值:
def get_person_info(): name = "aini" age = 23 return name, age # 返回一个包含多个值的元组 info = get_person_info() print(info) # 输出 ('aini', 23)
9.9 元组的拷贝(了解)
元组的拷贝通常不需要特别处理,因为元组是不可变的,直接赋值就是拷贝。拷贝只是创建了新的引用,指向相同的内存地址。
示例:
original_tuple = (1, 2, 3) copy_tuple = original_tuple print(copy_tuple is original_tuple) # 输出 True,两个变量指向相同对象
9.10 元组的优点和局限性(了解)
9.10.1 优点
- 不可变性:确保数据的安全性,不会被意外修改。
- 高效:因为不可变,元组的性能比列表略高,尤其是在迭代和存储方面。
- 适合作为键:可以作为字典的键,而列表不能。
9.10.2 局限性
- 不可变:无法修改、添加或删除元素。
- 方法少:元组只提供了
count()和index()两个方法,功能相对有限。
10- 字典
10.1 字典的定义(掌握)
字典是一种无序的键值对集合,用于存储和查找数据。字典通过键(key)来访问值(value),键必须是唯一的且不可变的(通常为字符串或数字),而值可以是任意数据类型。字典使用大括号 {} 表示,键值对之间用逗号分隔,键和值之间用冒号分隔。
定义字典:
empty_dict = {} # 空字典 person = {"name": "aini", "age": 23, "city": "Shanghai"} # 包含多个键值对的字典
10.2 字典的基本操作(掌握)
字典支持多种基本操作,如添加、修改、删除和访问键值对。
10.2.1 访问字典的值
使用键来访问字典中的值。如果键不存在会引发
KeyError,可以使用get()方法避免异常。person = {"name": "aini", "age": 23} print(person["name"]) # 输出 'aini' print(person.get("age")) # 输出 23 print(person.get("gender", "N/A")) # 输出 'N/A',若键不存在返回默认值
10.2.2 添加和修改键值对
如果键已存在,则修改该键的值;如果键不存在,则添加新的键值对。
person = {"name": "aini", "age": 23} person["city"] = "Shanghai" # 添加新的键值对 person["age"] = 24 # 修改已有键的值 print(person) # 输出 {'name': 'aini', 'age': 24, 'city': 'Shanghai'}
10.2.3 删除键值对
使用
del语句或pop()方法删除指定的键值对。popitem()方法可以随机删除字典中的最后一对键值。person = {"name": "aini", "age": 23, "city": "Shanghai"} del person["city"] # 删除指定键 age = person.pop("age") # 使用 pop() 获取并删除指定键 print(person) # 输出 {'name': 'aini'} print(age) # 输出 23
10.2.4 检查键是否存在
使用
in关键字检查键是否存在于字典中。person = {"name": "aini", "age": 23} print("name" in person) # 输出 True print("city" in person) # 输出 False
10.3 字典的常用方法(掌握)
Python 提供了多种方法来操作字典,这些方法可以帮助我们进行遍历、更新和获取键值对等操作。
10.3.1 keys():获取所有键
使用
keys()方法返回字典中所有键的视图。person = {"name": "aini", "age": 23} print(person.keys()) # 输出 dict_keys(['name', 'age'])
10.3.2 values():获取所有值
使用
values()方法返回字典中所有值的视图。person = {"name": "aini", "age": 23} print(person.values()) # 输出 dict_values(['aini', 23])
10.3.3 items():获取所有键值对
使用
items()方法返回字典中所有键值对的视图,每个键值对以元组形式表示。person = {"name": "aini", "age": 23} print(person.items()) # 输出 dict_items([('name', 'aini'), ('age', 23)])
10.3.4 update():更新字典
使用
update()方法将另一个字典或键值对序列合并到当前字典中,若有重复键则更新值。person = {"name": "aini", "age": 23} additional_info = {"city": "Shanghai", "age": 24} person.update(additional_info) print(person) # 输出 {'name': 'aini', 'age': 24, 'city': 'Shanghai'}
10.3.5 pop() 和 popitem():删除键值对
pop(key):删除并返回指定键的值。popitem():随机删除并返回字典中的最后一个键值对(Python 3.7 以后为删除最后一对)。person = {"name": "aini", "age": 23, "city": "Shanghai"} age = person.pop("age") # 删除并返回 'age' 的值 last_item = person.popitem() # 随机删除并返回最后一个键值对 print(age) # 输出 23 print(last_item) # 输出 ('city', 'Shanghai')
10.3.6 clear():清空字典
使用
clear()方法删除字典中的所有键值对,将字典清空。person = {"name": "aini", "age": 23} person.clear() print(person) # 输出 {}
10.4 字典的遍历(掌握)
字典遍历是字典操作中非常常见的一部分,通常用于处理每一个键值对。
遍历键:
person = {"name": "aini", "age": 23} for key in person.keys(): print(key)遍历值:
for value in person.values(): print(value)遍历键值对:
for key, value in person.items(): print(f"{key}: {value}")
10.5 字典的嵌套(掌握)
字典可以包含其他字典,形成嵌套结构,用于表示更复杂的数据关系。
示例:
student = { "name": "aini", "age": 23, "courses": { "math": 90, "science": 85 } } print(student["courses"]["math"]) # 输出 90
10.6 字典生成式(掌握)
字典生成式(Dictionary Comprehension)是一种简洁的生成字典的方式,可以用一行代码创建一个新的字典,常用于数据处理和过滤。
基本语法:
{key_expr: value_expr for item in iterable if condition}示例:
squares = {x: x**2 for x in range(1, 6)} print(squares) # 输出 {1: 1, 2: 4, 3: 9, 4: 16, 5: 25}
10.7 字典的拷贝(了解)
字典的拷贝分为浅拷贝和深拷贝。
10.7.1 浅拷贝
浅拷贝只复制字典的第一层元素,嵌套的字典仍然是引用。
original = {"name": "aini", "courses": {"math": 90}} shallow_copy = original.copy() shallow_copy["courses"]["math"] = 100 print(original) # 输出 {'name': 'aini', 'courses': {'math': 100}}
10.7.2 深拷贝
深拷贝递归地复制所有层级的元素,使用
copy模块中的deepcopy()实现。import copy original = {"name": "aini", "courses": {"math": 90}} deep_copy = copy.deepcopy(original) deep_copy["courses"]["math"] = 100 print(original) # 输出 {'name': 'aini', 'courses': {'math': 90}}
10.8 字典的使用场景(了解)
字典适合用于存储和查找数据的场景,尤其是在以下情况中:
数据映射:存储键值对关系,如用户信息、配置数据等。
计数:可以用字典来统计元素出现的频率。
多层数据结构:当需要存储多层数据时,字典嵌套是常用方式。
示例:计数应用:
words = ["apple", "banana", "apple", "cherry"] word_count = {} for word in words: word_count[word] = word_count.get(word, 0) + 1 print(word_count) # 输出 {'apple': 2, 'banana': 1, 'cherry': 1}
11- 集合
11.1 集合的定义(掌握)
集合是一个无序且不重复的元素集合。它通常用于去重、集合运算(交集、并集、差集等)等场景。集合使用大括号 {} 表示,或者通过 set() 函数创建(适用于空集合)。
定义集合:
empty_set = set() # 空集合,不能用 {} 创建空集合 fruits = {"apple", "banana", "cherry"} # 包含多个元素的集合
11.2 集合的基本操作(掌握)
集合支持添加、删除和检查元素是否存在等基本操作。
11.2.1 添加元素
使用
add()方法将元素添加到集合中,如果元素已存在则不会重复添加。fruits = {"apple", "banana"} fruits.add("cherry") print(fruits) # 输出 {'apple', 'banana', 'cherry'}
11.2.2 删除元素
使用
remove()方法删除指定元素,如果元素不存在会引发KeyError。使用
discard()方法删除指定元素,如果元素不存在不会报错。fruits = {"apple", "banana", "cherry"} fruits.remove("banana") fruits.discard("grape") # 不会报错 print(fruits) # 输出 {'apple', 'cherry'}
11.2.3 检查元素是否存在
使用
in关键字检查元素是否存在于集合中。fruits = {"apple", "banana", "cherry"} print("apple" in fruits) # 输出 True print("grape" in fruits) # 输出 False
11.3 集合的常用方法(掌握)
集合提供了丰富的方法来进行集合运算,如交集、并集、差集等。
11.3.1 union() 和 |:并集
使用
union()方法或|运算符获取两个集合的并集,返回一个新集合。set1 = {1, 2, 3} set2 = {3, 4, 5} print(set1.union(set2)) # 输出 {1, 2, 3, 4, 5} print(set1 | set2) # 输出 {1, 2, 3, 4, 5}
11.3.2 intersection() 和 &:交集
使用
intersection()方法或&运算符获取两个集合的交集,返回一个新集合。set1 = {1, 2, 3} set2 = {3, 4, 5} print(set1.intersection(set2)) # 输出 {3} print(set1 & set2) # 输出 {3}
11.3.3 difference() 和 -:差集
使用
difference()方法或-运算符获取集合的差集,返回一个新集合。set1 = {1, 2, 3} set2 = {3, 4, 5} print(set1.difference(set2)) # 输出 {1, 2} print(set1 - set2) # 输出 {1, 2}
11.3.4 symmetric_difference() 和 ^:对称差集
使用
symmetric_difference()方法或^运算符获取集合的对称差集,即在任一集合中但不在两个集合中的元素。set1 = {1, 2, 3} set2 = {3, 4, 5} print(set1.symmetric_difference(set2)) # 输出 {1, 2, 4, 5} print(set1 ^ set2) # 输出 {1, 2, 4, 5}
11.4 集合的更新操作(掌握)
集合的更新操作会将另一个集合中的元素添加到当前集合中,通常会直接改变原集合。
11.4.1 update() 和 |=:并集更新
使用
update()方法或|=运算符将另一个集合的元素并入当前集合,直接修改原集合。set1 = {1, 2, 3} set2 = {3, 4, 5} set1.update(set2) print(set1) # 输出 {1, 2, 3, 4, 5}
11.4.2 intersection_update() 和 &=:交集更新
使用
intersection_update()方法或&=运算符保留当前集合和另一个集合的交集,直接修改原集合。set1 = {1, 2, 3} set2 = {3, 4, 5} set1.intersection_update(set2) print(set1) # 输出 {3}
11.4.3 difference_update() 和 -=:差集更新
使用
difference_update()方法或-=运算符从当前集合中删除与另一个集合的交集元素,直接修改原集合。set1 = {1, 2, 3} set2 = {3, 4, 5} set1.difference_update(set2) print(set1) # 输出 {1, 2}
11.4.4 symmetric_difference_update() 和 ^=:对称差集更新
使用
symmetric_difference_update()方法或^=运算符保留当前集合和另一个集合的对称差集,直接修改原集合。set1 = {1, 2, 3} set2 = {3, 4, 5} set1.symmetric_difference_update(set2) print(set1) # 输出 {1, 2, 4, 5}
11.5 集合的遍历(掌握)
可以使用 for 循环遍历集合中的每一个元素。
示例:
fruits = {"apple", "banana", "cherry"} for fruit in fruits: print(fruit)
11.6 集合生成式(掌握)
集合生成式(Set Comprehension)是一种简洁的生成集合的方式,可以用一行代码创建一个新的集合,常用于数据处理和过滤。
基本语法:
{表达式 for 变量 in 可迭代对象 if 条件}示例:
squares = {x**2 for x in range(1, 6)} print(squares) # 输出 {1, 4, 9, 16, 25}
11.7 集合的使用场景(了解)
集合主要用于去重和集合运算的场景,在以下情况中非常有用:
- 数据去重:可以快速删除重复元素。
- 集合运算:交集、并集、差集和对称差集等集合操作。
- 快速查找:集合中的查找操作的时间复杂度为
O(1),比列表更快。
示例:去重应用:
numbers = [1, 2, 2, 3, 4, 4, 5] unique_numbers = set(numbers) print(unique_numbers) # 输出 {1, 2, 3, 4, 5}
11.8 冻结集合(了解)
冻结集合(frozenset)是一种不可变集合,一旦创建就无法修改,类似于不可变的元组。冻结集合常用于需要不可变集合的场景,例如字典的键。
创建冻结集合:
frozen_fruits = frozenset(["apple", "banana", "cherry"]) # frozen_fruits.add("grape") # 会引发 AttributeError,因为冻结集合不可修改 print(frozen_fruits) # 输出 frozenset({'apple', 'banana', 'cherry'})
好的,下面将详细讲解 Python 中的 if 判断语句。if 语句用于根据条件执行不同的代码块,是编写控制流的重要工具。从基本语法、分支结构到嵌套和简写形式,将详细解释 if 判断的使用。知识点分为“掌握”和“了解”两类,序号从 12.1 开始。
12- if判断
12.1 if 语句的基本语法(掌握)
if 语句用于根据条件执行代码块,如果条件为 True,则执行 if 语句块中的代码;否则,跳过该代码块。if 语句的基本语法如下:
语法:
if 条件: 代码块示例:
age = 20 if age >= 18: print("成年人") # 输出 "成年人"
在上面的代码中,当 age >= 18 条件为 True 时,打印 "成年人"。
12.2 if-else 语句(掌握)
if-else 语句用于根据条件执行两个代码块之一。如果条件为 True,执行 if 代码块;否则,执行 else 代码块。
语法:
if 条件: 代码块1 else: 代码块2示例:
age = 16 if age >= 18: print("成年人") else: print("未成年人") # 输出 "未成年人"
在上面的代码中,当 age < 18 时,else 代码块中的内容会被执行。
12.3 if-elif-else 语句(掌握)
if-elif-else 语句用于处理多重条件判断。如果第一个条件为 False,则检查下一个条件,以此类推。可以包含多个 elif,但 else 语句只能有一个,并且是可选的。
语法:
if 条件1: 代码块1 elif 条件2: 代码块2 elif 条件3: 代码块3 else: 代码块4示例:
score = 85 if score >= 90: print("优秀") elif score >= 75: print("良好") # 输出 "良好" elif score >= 60: print("及格") else: print("不及格")
在上面的代码中,程序会从上到下依次判断条件,直到找到第一个满足条件的代码块。
12.4 嵌套的 if 语句(掌握)
if 语句可以嵌套在另一个 if 语句中,用于处理更复杂的逻辑。但嵌套层次不宜过深,以避免代码难以阅读。
语法:
if 条件1: if 条件2: 代码块1 else: 代码块2 else: 代码块3示例:
age = 20 has_id = True if age >= 18: if has_id: print("允许进入") # 输出 "允许进入" else: print("需要身份证") else: print("未成年人禁止进入")
在上面的代码中,当 age >= 18 且 has_id 为 True 时,执行 "允许进入"。
12.5 单行 if 表达式(掌握)
在一些简单的条件判断中,可以使用单行 if 表达式,将 if 和 else 的执行代码写在同一行。
语法:
代码块1 if 条件 else 代码块2示例:
age = 20 result = "成年人" if age >= 18 else "未成年人" print(result) # 输出 "成年人"
在上面的代码中,if 表达式用于根据 age 的值返回不同的结果。
12.6 多条件判断(掌握)
在 if 语句中,可以使用逻辑运算符 and 和 or 实现多条件判断。
12.6.1 and 运算符
and运算符:当所有条件为True时,返回True,否则返回False。age = 20 has_id = True if age >= 18 and has_id: print("允许进入") # 输出 "允许进入"
12.6.2 or 运算符
or运算符:当至少一个条件为True时,返回True,否则返回False。age = 16 has_permission = True if age >= 18 or has_permission: print("允许进入") # 输出 "允许进入"
在多条件判断中,合理使用 and 和 or 可以更精确地控制代码逻辑。
12.7 if 判断的注意事项(了解)
在编写 if 判断时,有一些常见的注意事项,以避免代码错误或逻辑漏洞。
12.7.1 比较运算符的使用
- 确保使用正确的比较运算符(如
==、!=、<、>等)进行条件判断。错误的运算符可能导致逻辑错误。
12.7.2 避免过深的嵌套
- 尽量避免过深的
if嵌套,层级过多会影响代码的可读性和维护性。可以使用elif或提前返回等方式优化嵌套结构。
12.7.3 注意缩进
- Python 使用缩进来标识代码块,因此
if判断中的代码块需要保持一致的缩进。缩进错误会导致IndentationError。
12.7.4 判断值的布尔性
在
if判断中,可以直接使用变量名或表达式来检查其布尔性。例如,if my_list:检查列表是否为空。my_list = [1, 2, 3] if my_list: print("列表不为空") else: print("列表为空")
12.8 综合示例(掌握)
通过一个综合示例来展示 if 判断在实际代码中的应用。
示例:根据用户输入的年龄,判断他们的分类:
age = int(input("请输入你的年龄: ")) if age < 12: print("儿童") elif 12 <= age < 18: print("青少年") elif 18 <= age < 65: print("成年人") else: print("老年人")
在这个示例中,用户输入年龄,程序会根据不同的条件打印相应的分类。
13- for循环
13.1 for 循环的基本语法(掌握)
for 循环用于从一个可迭代对象中逐一提取元素,并在循环体中对每个元素执行操作。基本语法如下:
语法:
for 变量 in 可迭代对象: 代码块示例:
fruits = ["apple", "banana", "cherry"] for fruit in fruits: print(fruit)在上面的示例中,
for循环依次提取fruits列表中的每一个元素,并打印出来。
13.2 使用 range() 函数进行数值循环(掌握)
range() 函数用于生成一系列数字,常用于指定循环的次数,生成的数字序列为左闭右开区间 [start, stop)。
13.2.1 基本用法
语法:
range(stop) range(start, stop) range(start, stop, step)示例:
# 从0到4的序列 for i in range(5): print(i) # 输出 0, 1, 2, 3, 4 # 从2到6的序列 for i in range(2, 7): print(i) # 输出 2, 3, 4, 5, 6 # 从1到9,每隔2步 for i in range(1, 10, 2): print(i) # 输出 1, 3, 5, 7, 9
13.3 遍历字符串(掌握)
字符串是一个字符序列,可以直接使用 for 循环逐个访问其中的字符。
示例:
text = "Python" for char in text: print(char)在上面的代码中,
for循环逐个访问字符串text中的每一个字符并打印。
13.4 遍历列表和元组(掌握)
列表和元组都是可迭代对象,可以使用 for 循环逐个访问它们的元素。
示例:
numbers = [1, 2, 3, 4, 5] for num in numbers: print(num)元组遍历示例:
items = (10, 20, 30) for item in items: print(item)
13.5 遍历字典(掌握)
字典是键值对的集合,可以使用 for 循环来遍历键、值或键值对。
13.5.1 遍历键
示例:
person = {"name": "aini", "age": 23} for key in person: print(key) # 输出 "name" 和 "age"
13.5.2 遍历值
示例:
for value in person.values(): print(value) # 输出 "aini" 和 23
13.5.3 遍历键值对
示例:
for key, value in person.items(): print(f"{key}: {value}") # 输出 "name: aini" 和 "age: 23"
13.6 嵌套的 for 循环(掌握)
在 for 循环内部可以嵌套另一个 for 循环,通常用于处理二维数据结构(如列表嵌套列表)。
示例:
matrix = [ [1, 2, 3], [4, 5, 6], [7, 8, 9] ] for row in matrix: for element in row: print(element, end=" ") # 输出 1 2 3 4 5 6 7 8 9 print() # 换行
在上面的代码中,外层循环遍历每一行,内层循环遍历每行中的每一个元素。
13.7 使用 enumerate() 函数获取索引和元素(掌握)
enumerate() 函数用于在 for 循环中同时获取元素的索引和元素本身,适合在遍历时需要索引的场景。
示例:
fruits = ["apple", "banana", "cherry"] for index, fruit in enumerate(fruits): print(f"{index}: {fruit}")输出:
0: apple 1: banana 2: cherry
13.8 使用 zip() 函数并行遍历多个列表(掌握)
zip() 函数用于将多个可迭代对象组合成一个迭代器,以便在 for 循环中并行遍历多个序列。
示例:
names = ["aini", "zhang", "li"] ages = [23, 25, 30] for name, age in zip(names, ages): print(f"{name} is {age} years old.")输出:
aini is 23 years old. zhang is 25 years old. li is 30 years old.
13.9 列表生成式中的 for 循环(掌握)
列表生成式(List Comprehension)是一种简洁的生成列表的方法,通常用来将 for 循环和条件判断结合起来生成新的列表。
基本语法:
[表达式 for 变量 in 可迭代对象 if 条件]示例:
squares = [x**2 for x in range(1, 6)] print(squares) # 输出 [1, 4, 9, 16, 25]
13.10 for-else 语句(了解)
for-else 语句中的 else 块会在 for 循环正常完成后执行,如果循环被 break 语句提前终止,则不执行 else 块。该语句结构相对少用。
示例:
numbers = [1, 2, 3, 4, 5] for num in numbers: if num == 3: print("Found 3!") break else: print("3 not found.")在上面的代码中,
for循环因break终止,else块不会执行。
13.11 for 循环的注意事项(了解)
在编写 for 循环时,有一些常见的注意事项,以避免逻辑错误或效率低下:
- 避免修改可迭代对象:在
for循环中修改正在迭代的对象(如添加或删除元素)可能导致循环行为异常。 - 合理使用
range()和enumerate():当需要索引时使用enumerate(),避免手动维护索引。 - 避免嵌套过深:多层嵌套会导致代码复杂且难以维护,尽量优化循环结构。
14- while循环
14.1 while 循环的基本语法(掌握)
while 循环在指定条件为 True 时不断重复执行代码块,直到条件为 False 时结束循环。while 循环的语法结构如下:
语法:
while 条件: 代码块示例:
count = 1 while count <= 5: print(count) count += 1输出:
1 2 3 4 5在上面的代码中,
while循环会在count <= 5为True时执行,直到count增加到 6,条件变为False时终止循环。
14.2 无限循环(掌握)
如果 while 循环的条件一直为 True,则会形成无限循环。在某些情况下,程序需要一直运行直到满足特定的退出条件。
示例:
while True: user_input = input("请输入 'exit' 退出: ") if user_input == "exit": break在上面的代码中,程序会一直运行,直到用户输入 "exit" 时,通过
break退出循环。
14.3 使用 break 和 continue 控制循环(掌握)
break 和 continue 是控制循环的两个关键字,可以用来在特定条件下中断或跳过循环的执行。
14.3.1 break:中断循环
break用于立即退出循环,不再执行循环体的剩余部分。count = 1 while count <= 5: if count == 3: break print(count) count += 1输出:
1 2在上面的代码中,当
count为 3 时,break语句会中断循环。
14.3.2 continue:跳过本次循环
continue用于跳过当前循环的剩余部分,立即开始下一次循环。count = 0 while count < 5: count += 1 if count == 3: continue print(count)输出:
1 2 4 5在上面的代码中,当
count为 3 时,continue会跳过本次循环的剩余部分。
14.4 while-else 语句(了解)
while-else 语句中的 else 块会在 while 循环正常完成后执行,如果循环被 break 语句提前终止,则不会执行 else 块。
示例:
count = 1 while count <= 3: print(count) count += 1 else: print("循环结束")输出:
1 2 3 循环结束
在上面的代码中,当 while 循环正常结束时,else 块会被执行。
14.5 使用 while 循环处理用户输入(掌握)
while 循环常用于处理用户输入,直到用户输入有效的内容为止。
示例:
while True: user_input = input("请输入一个数字 (输入 'exit' 退出): ") if user_input == "exit": print("退出程序") break elif user_input.isdigit(): print(f"您输入的数字是 {user_input}") else: print("无效输入,请输入数字")
在上面的代码中,while 循环不断询问用户输入数字,直到用户输入 "exit" 时退出程序。
14.6 while 循环中的计数器(掌握)
使用 while 循环时,经常需要设置计数器来控制循环次数,计数器通常会在每次循环结束后递增或递减。
示例:
count = 0 while count < 5: print("当前计数:", count) count += 1输出:
当前计数: 0 当前计数: 1 当前计数: 2 当前计数: 3 当前计数: 4
在上面的代码中,count 是计数器,控制 while 循环的次数。
14.7 嵌套的 while 循环(了解)
while 循环可以嵌套在另一个 while 循环中,用于处理多层循环结构。
示例:
outer = 1 while outer <= 3: inner = 1 while inner <= 2: print(f"外层: {outer}, 内层: {inner}") inner += 1 outer += 1输出:
外层: 1, 内层: 1 外层: 1, 内层: 2 外层: 2, 内层: 1 外层: 2, 内层: 2 外层: 3, 内层: 1 外层: 3, 内层: 2
在上面的代码中,外层 while 控制 outer 计数,内层 while 控制 inner 计数。
14.8 while 循环的注意事项(了解)
在编写 while 循环时,有一些常见的注意事项,以避免代码运行出错或陷入死循环。
- 避免死循环:确保循环条件最终会变为
False,否则可能导致死循环,程序无法退出。 - 计数器控制:使用计数器时,记得在每次循环中更新计数器的值,否则可能造成无限循环。
- 合理使用
break和continue:break和continue能提高循环的灵活性,但要避免滥用,以免影响代码的可读性。
15- for循环和while循环比较
15.1 基本区别(掌握)
for循环:用于遍历可迭代对象(如列表、元组、字符串、字典、集合等)中的每一个元素,通常适用于明确知道迭代次数的场景。while循环:在条件为True时不断执行代码块,适用于不确定迭代次数的场景,直到某一条件满足才结束循环。
15.2 语法结构对比(掌握)
for 循环的基本语法
for 变量 in 可迭代对象:
代码块while 循环的基本语法
while 条件:
代码块15.3 使用场景(掌握)
for 循环的适用场景
- 遍历已知长度的可迭代对象:如列表、字符串、元组等,直接遍历元素。
- 需要计数的循环:可以与
range()配合,执行固定次数的循环。 - 生成列表:列表生成式通常使用
for循环生成。
while 循环的适用场景
- 条件控制的循环:在满足条件时重复执行代码,而不是固定次数。
- 用户输入验证:不断检查输入,直到符合要求为止。
- 无限循环:在服务器或实时监控中常见,通过
while True持续执行,直到满足某个终止条件。
15.4 优缺点比较(掌握)
| 特性 | for 循环 | while 循环 |
|---|---|---|
| 适用情况 | 明确的迭代次数或固定的序列 | 不确定的迭代次数,基于条件的循环 |
| 可读性 | 代码简洁明了,适合处理序列 | 适合动态条件的循环,但逻辑略复杂 |
| 灵活性 | 依赖可迭代对象或 range 控制次数 | 可处理任意复杂的条件 |
| 效率 | 更适合于遍历对象,代码效率高 | 适合条件控制,可能会陷入死循环 |
15.5 for 和 while 循环的替换(掌握)
在某些情况下,for 和 while 循环可以相互替换:
15.5.1 使用 while 循环模拟 for 循环
示例:用
while模拟一个固定次数的循环。i = 0 while i < 5: print(i) i += 1等价于:
for i in range(5): print(i)
15.5.2 使用 for 循环模拟简单的条件控制
虽然 for 循环并不直接适用于条件控制,但可以通过遍历 itertools.cycle 实现无限循环,并在循环体中条件判断以 break 退出。
from itertools import cycle
for _ in cycle([None]):
user_input = input("请输入 'exit' 退出: ")
if user_input == "exit":
break15.6 示例对比(掌握)
示例 1:遍历列表
for循环:fruits = ["apple", "banana", "cherry"] for fruit in fruits: print(fruit)while循环:fruits = ["apple", "banana", "cherry"] i = 0 while i < len(fruits): print(fruits[i]) i += 1
示例 2:条件控制的循环
for循环(通过break终止):for _ in range(100): # 实际上是人为限定了次数 user_input = input("请输入 'exit' 退出: ") if user_input == "exit": breakwhile循环:while True: user_input = input("请输入 'exit' 退出: ") if user_input == "exit": break
15.7 循环的嵌套使用(了解)
for 和 while 循环可以嵌套使用,适合处理多层数据结构或条件复杂的情况。
示例:遍历二维列表中的元素,并根据条件判断是否打印
matrix = [ [1, 2, 3], [4, 5, 6], [7, 8, 9] ] for row in matrix: for element in row: if element % 2 == 0: print(element)
在这个示例中,for 循环用于遍历列表,而条件判断和打印操作可以在嵌套循环中控制。
15.8 优先选择哪种循环(掌握)
- 选择
for循环:当明确知道迭代次数或需要遍历可迭代对象时,优先选择for循环。它的结构清晰、代码简洁。 - 选择
while循环:当循环次数不确定或需要条件控制时,选择while循环。它在处理需要灵活控制结束条件的场景中更合适。
16- 循环综合练习题
1. 输出 1 到 10 的所有数字
思路:使用 for 循环遍历从 1 到 10 的范围,逐个输出数字。
for i in range(1, 11):
print(i) # 输出 1 到 10 的数字2. 计算 1 到 100 的和
思路:使用 for 循环遍历 1 到 100,将每个数累加到一个变量中。
total = 0
for i in range(1, 101):
total += i # 每次循环累加当前数到总和中
print("1到100的和为:", total)3. 输出列表中的所有元素
思路:使用 for 循环遍历列表,并打印每个元素。
fruits = ["apple", "banana", "cherry"]
for fruit in fruits:
print(fruit) # 输出每个水果的名字4. 打印 1 到 50 中所有的偶数
思路:使用 for 循环遍历 1 到 50,检查每个数是否为偶数,是偶数则输出。
for i in range(1, 51):
if i % 2 == 0: # 如果数是偶数
print(i) # 输出偶数5. 计算一个列表中所有数字的和
思路:遍历列表中的每个数字,并累加到一个变量中。
numbers = [10, 20, 30, 40]
total = 0
for num in numbers:
total += num # 累加每个数到总和
print("列表中所有数字的和为:", total)6. 找到列表中最大值
思路:初始化最大值为第一个元素,然后遍历列表,逐个比较并更新最大值。
numbers = [3, 5, 7, 2, 8]
max_num = numbers[0] # 假设第一个数为最大值
for num in numbers:
if num > max_num:
max_num = num # 更新最大值
print("列表中的最大值是:", max_num)7. 打印九九乘法表
思路:使用嵌套的 for 循环,外层循环控制乘数 1 到 9,内层循环控制被乘数 1 到 9。
for i in range(1, 10):
for j in range(1, i + 1):
print(f"{j} * {i} = {i * j}", end=" ") # 打印乘法表
print() # 换行8. 反转一个字符串
思路:使用 for 循环从字符串末尾开始逐个字符提取,并累加到新字符串中。
text = "hello"
reversed_text = ""
for char in text[::-1]: # 从末尾到开头遍历字符
reversed_text += char
print("反转后的字符串为:", reversed_text)9. 统计列表中正数的个数
思路:遍历列表,检查每个数字是否为正数,是则计数加一。
numbers = [-5, 3, 8, -2, 6]
count = 0
for num in numbers:
if num > 0:
count += 1 # 计数加一
print("列表中正数的个数为:", count)10. 找到两个列表的交集
思路:使用 for 循环遍历第一个列表,检查是否在第二个列表中。
list1 = [1, 2, 3, 4]
list2 = [3, 4, 5, 6]
intersection = []
for item in list1:
if item in list2:
intersection.append(item)
print("两个列表的交集为:", intersection)11. 输出一个列表中所有非零元素
思路:遍历列表,检查每个元素是否不为零,不为零则输出。
numbers = [0, 5, 3, 0, 8]
for num in numbers:
if num != 0:
print(num) # 输出非零元素12. 打印一个字符串中所有的字母
思路:遍历字符串,检查每个字符是否为字母,如果是则打印。
text = "Hello123"
for char in text:
if char.isalpha(): # 检查是否是字母
print(char)13. 计算一个数的阶乘
思路:使用 for 循环从 1 到 n,逐个相乘计算阶乘。
n = 5
factorial = 1
for i in range(1, n + 1):
factorial *= i
print(f"{n} 的阶乘是:", factorial)14. 打印一个列表中的奇数位置元素
思路:使用 for 循环结合 range(),遍历奇数位置索引的元素。
numbers = [10, 20, 30, 40, 50]
for i in range(1, len(numbers), 2):
print(numbers[i]) # 输出奇数位置的元素15. 求出 1 到 50 的所有数的平方和
思路:使用 for 循环遍历 1 到 50,将每个数的平方累加到总和中。
total = 0
for i in range(1, 51):
total += i ** 2 # 累加平方
print("1到50的平方和为:", total)16. 输出一个字符串中所有的数字
思路:使用 for 循环遍历字符串,检查每个字符是否为数字,是则输出。
text = "abc123def456"
for char in text:
if char.isdigit(): # 检查是否是数字
print(char)17. 打印出所有质数(2 到 50)
思路:使用嵌套循环,外层遍历 2 到 50,内层检查每个数是否有除 1 和自身之外的因数。
for num in range(2, 51):
is_prime = True
for i in range(2, int(num ** 0.5) + 1):
if num % i == 0:
is_prime = False
break
if is_prime:
print(num)18. 找到列表中最小值
思路:假设第一个元素为最小值,遍历比较更新。
numbers = [4, 2, 9, 1, 5]
min_num = numbers[0]
for num in numbers:
if num < min_num:
min_num = num
print("列表中的最小值为:", min_num)19. 判断一个字符串是否是回文
思路:检查字符串是否与反转后的字符串相同。
text = "level"
is_palindrome = text == text[::-1]
print(f"{text} 是回文" if is_palindrome else f"{text} 不是回文")20. 计算一个字符串中每个字符的出现次数
思路:使用字典存储字符和对应出现次数。
text = "hello world"
count_dict = {}
for char in text:
count_dict[char] = count_dict.get(char, 0) + 1
print("每个字符的出现次数为:", count_dict)17- 循环判断练习题(较难)
10.1 判断素数
题目描述
编写一个程序,判断用户输入的一个正整数是否为素数。
解题思路
- 输入一个正整数。
- 使用循环判断从2到该数的平方根是否有整除的数。
代码详解
num = int(input("请输入一个正整数: "))
is_prime = True
if num < 2:
is_prime = False
else:
for i in range(2, int(num**0.5) + 1):
if num % i == 0:
is_prime = False
break
if is_prime:
print(f"{num} 是素数")
else:
print(f"{num} 不是素数")10.2 打印斐波那契数列
题目描述
编写一个程序,输出斐波那契数列的前n项,n由用户输入。
解题思路
- 使用循环生成斐波那契数列。
代码详解
n = int(input("请输入要输出的斐波那契数列项数: "))
a, b = 0, 1
fib_seq = []
for _ in range(n):
fib_seq.append(a)
a, b = b, a + b
print(fib_seq)10.3 冒泡排序
题目描述
实现一个冒泡排序算法,要求用户输入一组整数,然后输出排序后的结果。
解题思路
- 使用嵌套循环比较相邻元素。
代码详解
arr = list(map(int, input("请输入一组整数,用空格分隔: ").split()))
n = len(arr)
for i in range(n):
for j in range(0, n - i - 1):
if arr[j] > arr[j + 1]:
arr[j], arr[j + 1] = arr[j + 1], arr[j]
print("排序后的数组:", arr)10.4 统计字符频率
题目描述
编写程序,统计输入字符串中每个字符出现的频率,并输出结果。
解题思路
- 使用字典存储字符和其频率。
代码详解
input_string = input("请输入字符串: ")
freq = {}
for char in input_string:
freq[char] = freq.get(char, 0) + 1
print("字符频率:", freq)10.5 查找最大子序列和
题目描述
给定一个整数数组,编写程序找出具有最大和的连续子序列。
解题思路
- 使用动态规划维护当前的子序列和和最大子序列和。
代码详解
array = list(map(int, input("请输入整数数组,用空格分隔: ").split()))
max_sum = float('-inf')
current_sum = 0
for num in array:
current_sum += num
if current_sum > max_sum:
max_sum = current_sum
if current_sum < 0:
current_sum = 0
print("最大子序列和:", max_sum)10.6 查找重复元素
题目描述
编写程序,找出输入列表中所有重复的元素。
解题思路
- 使用集合存储已见过的元素。
代码详解
input_list = list(map(int, input("请输入整数列表,用空格分隔: ").split()))
seen = set()
duplicates = set()
for num in input_list:
if num in seen:
duplicates.add(num)
else:
seen.add(num)
print("重复的元素:", duplicates)10.7 计算阶乘
题目描述
编写程序,计算一个正整数的阶乘。
解题思路
- 使用循环从1乘到n。
代码详解
num = int(input("请输入一个正整数: "))
result = 1
for i in range(1, num + 1):
result *= i
print("阶乘是:", result)10.8 查找数组中第K大的元素
题目描述
编写程序,找出数组中第K大的元素。
解题思路
- 使用排序的方法,先对数组进行排序。
代码详解
array = list(map(int, input("请输入整数数组,用空格分隔: ").split()))
k = int(input("请输入K值: "))
unique_elements = list(set(array))
unique_elements.sort(reverse=True)
print(f"数组中第{k}大的元素是: {unique_elements[k - 1]}")10.9 验证回文数
题目描述
编写程序,判断一个字符串是否为回文。
解题思路
- 比较字符串的前后字符。
代码详解
input_string = input("请输入字符串: ")
is_palindrome = True
length = len(input_string)
for i in range(length // 2):
if input_string[i] != input_string[length - 1 - i]:
is_palindrome = False
break
if is_palindrome:
print(f"{input_string} 是回文")
else:
print(f"{input_string} 不是回文")10.10 爬楼梯问题
题目描述
假设每次可以爬1阶或2阶,编写程序计算爬到n阶的不同方式数。
解题思路
- 使用动态规划的思想。
代码详解
n = int(input("请输入楼梯的阶数: "))
if n == 1:
print("不同的爬楼梯方式数: 1")
elif n == 2:
print("不同的爬楼梯方式数: 2")
else:
dp = [0] * (n + 1)
dp[1], dp[2] = 1, 2
for i in range(3, n + 1):
dp[i] = dp[i - 1] + dp[i - 2]
print("不同的爬楼梯方式数:", dp[n])18- 函数
18.1 函数的定义(掌握)
函数是一个可重用的代码块,用于执行特定的任务。函数可以接收输入参数并返回结果,帮助我们组织代码并提高可读性和可维护性。
定义函数的基本语法:
def function_name(parameters): """可选的文档字符串""" # 函数体 return result # 可选的返回值示例:
def greet(name): """打印问候信息""" print(f"Hello, {name}!") greet("Alice") # 调用函数,输出: Hello, Alice!
18.2 函数的调用(掌握)
函数定义后可以通过调用来执行。函数调用可以传递参数,调用函数时参数的顺序要与定义时一致。
示例:
def add(a, b): """返回两个数的和""" return a + b result = add(5, 3) # 调用函数,传递参数 print(result) # 输出: 8
18.3 函数的参数(掌握)
函数可以接收参数,参数是函数外部传入的值,函数内部可以使用这些值。
18.3.1 位置参数
定义和调用:
def multiply(x, y): return x * y print(multiply(2, 3)) # 输出: 6
18.3.2 默认参数
定义默认参数:在定义函数时,可以为参数指定默认值,调用时可以选择性传入参数。
def power(base, exponent=2): return base ** exponent print(power(3)) # 输出: 9 (使用默认 exponent) print(power(3, 3)) # 输出: 27 (覆盖默认 exponent)
18.3.3 可变参数
使用
*args和**kwargs:*args用于传入任意数量的位置参数,**kwargs用于传入任意数量的关键字参数。def sum_all(*args): return sum(args) print(sum_all(1, 2, 3, 4)) # 输出: 10 def print_info(**kwargs): for key, value in kwargs.items(): print(f"{key}: {value}") print_info(name="Alice", age=30) # 输出: name: Alice, age: 30
18.4 函数的返回值(掌握)
函数可以返回结果,使用 return 语句指定返回值。如果没有 return,函数将返回 None。
示例:
def square(n): return n * n result = square(4) print(result) # 输出: 16
18.4.1 多个返回值
返回多个值:可以使用逗号分隔多个值。
def divide(a, b): return a // b, a % b # 返回商和余数 quotient, remainder = divide(10, 3) print(quotient, remainder) # 输出: 3 1
18.5 函数的文档字符串(掌握)
文档字符串(docstring)是函数定义中的字符串,用于描述函数的功能。文档字符串通常是函数的第一行,可以通过 help() 函数查看。
示例:
def subtract(a, b): """返回 a 和 b 的差值""" return a - b print(help(subtract)) # 查看文档字符串
18.6 函数的作用域(掌握)
变量的作用域决定了其可见性和生命周期。在 Python 中,变量有局部作用域和全局作用域。
18.6.1 局部变量
在函数内定义的变量:只在函数内有效,外部无法访问。
def func(): local_var = 10 # 局部变量 print(local_var) func() # print(local_var) # 会引发 NameError
18.6.2 全局变量
在函数外定义的变量:可以在整个程序中访问。
global_var = 20 # 全局变量 def func(): print(global_var) # 可以访问全局变量 func() # 输出: 20
18.6.3 使用 global 关键字
在函数内部修改全局变量:可以使用
global关键字声明。global_var = 30 def modify_global(): global global_var # 声明使用全局变量 global_var += 10 modify_global() print(global_var) # 输出: 40
18.7 高阶函数(掌握)
高阶函数是指接受函数作为参数或返回一个函数的函数。在 Python 中,函数是第一类对象,可以作为参数传递。
18.7.1 函数作为参数
示例:
def apply_function(func, value): return func(value) def square(n): return n * n result = apply_function(square, 5) print(result) # 输出: 25
18.7.2 返回函数
示例:
def outer_function(msg): def inner_function(): print(msg) return inner_function # 返回内嵌函数 my_func = outer_function("Hello, World!") my_func() # 输出: Hello, World!
18.8 匿名函数(了解)
匿名函数(lambda 函数)是一种没有名字的函数,通常用于需要小型函数的场景,如在 map()、filter() 和 sorted() 等函数中使用。
示例:
square = lambda x: x * x print(square(5)) # 输出: 25 # 使用 map() 函数 numbers = [1, 2, 3, 4] squares = list(map(lambda x: x ** 2, numbers)) print(squares) # 输出: [1, 4, 9, 16]
19- 全局变量和局部变量
19.1 变量的作用域(掌握)
在编程中,作用域指的是变量可以被访问的范围。在 Python 中,变量的作用域分为局部作用域和全局作用域。
- 局部作用域(Local Scope):在函数内部定义的变量,只能在该函数内部使用,函数外部无法访问这些变量。
- 全局作用域(Global Scope):在整个程序中定义的变量,通常位于函数外部,可以在程序的任何位置访问。
19.2 局部变量(掌握)
局部变量是在函数内部定义的变量。它的作用范围仅限于该函数,函数外部无法访问这个变量。局部变量的生命周期在函数执行期间,当函数执行完毕,局部变量也随之销毁。
19.2.1 局部变量的定义和访问
定义:在函数内部直接赋值给变量即定义了局部变量。
访问:只能在定义它的函数内部访问。
示例:
def my_function(): local_var = 10 # 局部变量 print("局部变量:", local_var) my_function() # 输出: 局部变量: 10 # print(local_var) # 会引发 NameError,因为函数外无法访问 local_var
在上面的示例中,local_var 是 my_function() 函数内部的局部变量,它只能在该函数内部使用。函数外部无法访问 local_var,否则会引发 NameError。
19.2.2 局部变量的优先级
在函数内部,如果局部变量和全局变量同名,局部变量会优先被使用。局部变量的优先级高于同名的全局变量。
示例:
x = 5 # 全局变量 def my_function(): x = 10 # 局部变量 print("函数内部的 x:", x) # 输出: 函数内部的 x: 10 my_function() print("函数外部的 x:", x) # 输出: 函数外部的 x: 5
在这个示例中,虽然 x 在函数外部被定义为全局变量,但在 my_function() 中重新定义了一个同名的局部变量 x,因此在函数内部会使用局部变量,而不会影响函数外部的全局变量。
19.3 全局变量(掌握)
全局变量是在函数外部定义的变量。全局变量可以在整个程序的任何地方访问,包括函数内部和外部。全局变量的生命周期贯穿程序的执行过程。
19.3.1 全局变量的定义和访问
定义:在函数外部直接赋值给变量。
访问:可以在函数内部和外部访问。
示例:
global_var = 20 # 全局变量 def my_function(): print("函数内部的全局变量:", global_var) my_function() # 输出: 函数内部的全局变量: 20 print("函数外部的全局变量:", global_var) # 输出: 函数外部的全局变量: 20
在这个示例中,global_var 是一个全局变量,既可以在 my_function() 函数内访问,也可以在函数外部访问。
19.3.2 使用 global 关键字修改全局变量
在函数内部,可以通过 global 关键字声明一个变量为全局变量,从而修改该全局变量的值。
示例:
count = 0 # 全局变量 def increment(): global count # 声明使用全局变量 count += 1 # 修改全局变量 increment() print("全局变量 count 的值:", count) # 输出: 全局变量 count 的值: 1
在这个示例中,通过 global count 声明 count 为全局变量,从而可以在 increment() 函数中修改 count 的值。
19.3.3 不使用 global 的情况下
如果没有使用 global 关键字直接在函数内部赋值同名变量,Python 会将该变量视为局部变量,不会影响同名的全局变量。
示例:
total = 100 # 全局变量 def reset_total(): total = 0 # 局部变量,不会影响全局的 total print("函数内部的 total:", total) # 输出: 函数内部的 total: 0 reset_total() print("全局的 total:", total) # 输出: 全局的 total: 100
在这个示例中,函数 reset_total() 中定义的 total 是一个局部变量,并不会影响函数外部的全局变量 total。
19.4 全局变量和局部变量的注意事项(掌握)
避免过度使用全局变量:全局变量在程序的任何地方都可以被修改,可能会导致意外错误。通常建议使用局部变量,除非确有必要才使用全局变量。
global的使用:如果需要在函数内部修改全局变量,必须使用global关键字,否则 Python 会默认将其视为局部变量。变量的生命周期:全局变量在程序运行期间始终存在,而局部变量只在函数执行期间有效,函数执行结束后局部变量会被销毁。
命名冲突:避免在局部作用域中定义与全局变量同名的变量,以免造成混淆。
可读性问题:过多的全局变量会降低代码的可读性和可维护性,增加调试难度。
19.5 全局变量和局部变量的综合示例(掌握)
以下是一个综合示例,展示全局变量、局部变量和 global 关键字的使用场景。
示例:
balance = 1000 # 全局变量,初始余额 def deposit(amount): """存款操作""" global balance # 声明 balance 为全局变量 balance += amount # 修改全局变量 print(f"存款 {amount} 元,当前余额:{balance}") def withdraw(amount): """取款操作""" if amount > balance: print("余额不足") else: global balance balance -= amount print(f"取款 {amount} 元,当前余额:{balance}") def check_balance(): """查询余额""" print(f"当前余额为:{balance}") # 操作示例 deposit(500) # 存款 500 元 withdraw(200) # 取款 200 元 check_balance() # 查询余额
在这个示例中,balance 是一个全局变量,用于记录账户余额。deposit()、withdraw() 和 check_balance() 是三个函数,分别用于存款、取款和查询余额。deposit() 和 withdraw() 函数通过 global 关键字来声明 balance 为全局变量,从而可以在函数内部修改全局变量 balance 的值。
20- 综合案例
1. 寻找满足条件的数字“自反数”
题目:定义自反数:一个整数 n 满足以下条件时称为自反数:
n是一个四位数。n可以被 4 整除。n的数位的平方和等于n自身。
请编写一个函数 is_autoreflective(num) 来判断一个数是否为自反数,并找出 1000 到 9999 之间的所有自反数。
思路分析:
- 使用嵌套循环提取各位数字。
- 检查是否为四位数、可被 4 整除、并且数位平方和等于数本身。
- 使用
is_autoreflective函数检查数字条件,在主程序中遍历范围并输出。
代码详解:
def is_autoreflective(num):
"""判断一个数是否为自反数"""
if num % 4 != 0:
return False
thousands = num // 1000
hundreds = (num // 100) % 10
tens = (num // 10) % 10
units = num % 10
return (thousands**2 + hundreds**2 + tens**2 + units**2) == num
# 找出所有自反数
autoreflective_numbers = []
for i in range(1000, 10000):
if is_autoreflective(i):
autoreflective_numbers.append(i)
print("所有自反数为:", autoreflective_numbers)2. 判断“亲密素数对”
题目:定义亲密素数对:如果两个素数之差等于 2,则称它们为亲密素数对。例如 (3, 5) 和 (11, 13) 是亲密素数对。编写函数 is_prime(num) 判断一个数是否为素数,找到 1 到 100 之间的所有亲密素数对。
思路分析:
- 编写
is_prime(num)函数判断一个数是否为素数。 - 遍历 1 到 100 的素数,检查每对素数之间的差是否等于 2。
- 如果差值满足条件,则将素数对存储在列表中并输出。
代码详解:
def is_prime(num):
"""判断一个数是否为素数"""
if num < 2:
return False
for i in range(2, int(num ** 0.5) + 1):
if num % i == 0:
return False
return True
# 找到 1 到 100 之间的所有亲密素数对
prime_pairs = []
previous_prime = None
for num in range(2, 101):
if is_prime(num):
if previous_prime and num - previous_prime == 2:
prime_pairs.append((previous_prime, num))
previous_prime = num
print("亲密素数对为:", prime_pairs)3. 生成和验证“循环素数”
题目:循环素数是指通过循环排列数位生成的新数字也都是素数。例如,197 是循环素数,因为 197、971 和 719 都是素数。编写函数 is_circular_prime(num) 判断一个数是否为循环素数,找出 1 到 100 之间的所有循环素数。
思路分析:
- 编写
is_prime(num)判断素数。 - 编写
generate_rotations(num)生成数的所有循环排列。 - 使用
is_circular_prime(num)判断每个循环排列是否为素数。
代码详解:
def is_prime(num):
if num < 2:
return False
for i in range(2, int(num ** 0.5) + 1):
if num % i == 0:
return False
return True
def generate_rotations(num):
"""生成所有循环排列"""
rotations = []
s = str(num)
for i in range(len(s)):
rotated = int(s[i:] + s[:i])
rotations.append(rotated)
return rotations
def is_circular_prime(num):
"""判断是否为循环素数"""
for rotation in generate_rotations(num):
if not is_prime(rotation):
return False
return True
# 找出 1 到 100 之间的循环素数
circular_primes = [num for num in range(1, 101) if is_circular_prime(num)]
print("循环素数有:", circular_primes)4. 计算“最小公倍数数列”
题目:编写函数 gcd(a, b) 计算两个数的最大公约数,编写函数 lcm(a, b) 计算两个数的最小公倍数,再编写 lcm_list(numbers) 计算一个整数列表的最小公倍数。测试 lcm_list 函数求 [4, 5, 12, 15] 的最小公倍数。
思路分析:
- 使用欧几里得算法在
gcd中计算最大公约数。 - 使用公式
lcm(a, b) = a * b / gcd(a, b)在lcm中计算最小公倍数。 - 使用
reduce和lcm计算列表的最小公倍数。
代码详解:
from functools import reduce
def gcd(a, b):
"""计算最大公约数"""
while b:
a, b = b, a % b
return a
def lcm(a, b):
"""计算最小公倍数"""
return a * b // gcd(a, b)
def lcm_list(numbers):
"""计算列表中所有数字的最小公倍数"""
return reduce(lcm, numbers)
# 测试列表的最小公倍数
numbers = [4, 5, 12, 15]
result = lcm_list(numbers)
print("列表 [4, 5, 12, 15] 的最小公倍数是:", result)5. 判断“完全平方回文数”
题目:完全平方回文数是指一个数字的平方是回文数。例如,11 是完全平方回文数,因为 (11^2 = 121),而 121 是回文数。编写函数 is_palindrome(num) 判断一个数是否为回文数,编写函数 is_square_palindrome(num) 判断一个数是否为完全平方回文数,输出 1 到 100 之间的所有完全平方回文数。
思路分析:
- 使用字符串反转在
is_palindrome(num)中判断回文数。 - 使用
is_square_palindrome(num)判断一个数的平方是否为回文数。 - 遍历 1 到 100,找出所有完全平方回文数。
代码详解:
def is_palindrome(num):
"""判断一个数是否是回文数"""
return str(num) == str(num)[::-1]
def is_square_palindrome(num):
"""判断一个数的平方是否是回文数"""
square = num ** 2
return is_palindrome(square)
# 找出 1 到 100 之间的完全平方回文数
square_palindromes = [num for num in range(1, 101) if is_square_palindrome(num)]
print("完全平方回文数有:", square_palindromes)6. 查找“素数回文三角数”
题目:素数回文三角数是指同时满足以下条件的数字:
- 该数字是素数。
- 该数字是回文数(正向和反向相同)。
- 该数字是三角数,三角数的公式为
n * (n + 1) / 2。
请编写函数 is_prime(num)、is_palindrome(num) 和 is_triangle_number(num) 来判断一个数是否满足这三个条件,并找出 1 到 10000 之间的所有素数回文三角数。
思路分析:
- 使用
is_prime(num)判断是否为素数。 - 使用
is_palindrome(num)判断是否为回文数。 - 使用
is_triangle_number(num)判断是否为三角数,检查是否符合三角数公式。 - 遍历 1 到 10000 的数,筛选出符合所有条件的数字。
代码详解:
def is_prime(num):
"""判断是否为素数"""
if num < 2:
return False
for i in range(2, int(num ** 0.5) + 1):
if num % i == 0:
return False
return True
def is_palindrome(num):
"""判断是否为回文数"""
return str(num) == str(num)[::-1]
def is_triangle_number(num):
"""判断是否为三角数"""
n = (-1 + (1 + 8 * num) ** 0.5) / 2
return n.is_integer()
# 找出 1 到 10000 之间的素数回文三角数
result = []
for i in range(1, 10001):
if is_prime(i) and is_palindrome(i) and is_triangle_number(i):
result.append(i)
print("素数回文三角数有:", result)7. 查找满足特定“数字和”的数字
题目:找出 100 到 999 之间所有的三位数,使得:
- 各个位数字之和等于 15。
- 各个位数字之积等于 36。
请编写函数 digit_sum(num) 和 digit_product(num) 来分别计算一个数字的位数之和与位数之积,并找出符合条件的三位数。
思路分析:
- 定义
digit_sum(num)和digit_product(num),分别计算一个数的位数和与位数积。 - 遍历 100 到 999,检查位数和为 15 且位数积为 36 的数。
代码详解:
def digit_sum(num):
"""返回数字的位数和"""
return sum(int(d) for d in str(num))
def digit_product(num):
"""返回数字的位数积"""
product = 1
for d in str(num):
product *= int(d)
return product
# 找出满足条件的三位数
result = []
for num in range(100, 1000):
if digit_sum(num) == 15 and digit_product(num) == 36:
result.append(num)
print("满足条件的三位数有:", result)8. 寻找满足条件的“质数方差对”
题目:找出 1 到 1000 之间所有的质数对 (p, q),使得 |p - q| 的平方等于 p + q。即满足条件 |p - q|^2 = p + q。
思路分析:
- 使用
is_prime(num)判断质数。 - 遍历 1 到 1000 中的质数对,检查是否满足
|p - q|^2 = p + q。 - 使用条件判断进行筛选,确保每对只输出一次。
代码详解:
def is_prime(num):
"""判断是否为素数"""
if num < 2:
return False
for i in range(2, int(num ** 0.5) + 1):
if num % i == 0:
return False
return True
# 找出 1 到 1000 之间的所有质数方差对
prime_pairs = []
primes = [i for i in range(1, 1001) if is_prime(i)]
for i in range(len(primes)):
for j in range(i + 1, len(primes)):
p, q = primes[i], primes[j]
if (abs(p - q) ** 2) == (p + q):
prime_pairs.append((p, q))
print("满足条件的质数方差对有:", prime_pairs)9. 查找“数位奇偶相反”的数字
题目:找出 1000 到 9999 之间所有四位数,使得:
- 数字的奇数位(从左到右的第 1 位和第 3 位)为偶数。
- 数字的偶数位(第 2 位和第 4 位)为奇数。
思路分析:
- 使用整除和取余操作提取各个数位。
- 检查奇数位是否为偶数,偶数位是否为奇数。
- 遍历四位数范围,筛选符合条件的数字。
代码详解:
# 找出满足条件的四位数
result = []
for num in range(1000, 10000):
thousands = num // 1000 # 第一位(奇数位)
hundreds = (num // 100) % 10 # 第二位(偶数位)
tens = (num // 10) % 10 # 第三位(奇数位)
units = num % 10 # 第四位(偶数位)
if thousands % 2 == 0 and tens % 2 == 0 and hundreds % 2 == 1 and units % 2 == 1:
result.append(num)
print("满足条件的四位数有:", result)10. 检查“等差质数序列”
题目:找出 1 到 100 之间所有长度为 3 的等差质数序列 (p, q, r),其中 p < q < r。即满足 q - p = r - q,且 p、q、r 均为素数。
思路分析:
- 使用
is_prime(num)函数判断质数。 - 使用嵌套循环枚举质数序列 (p, q, r)。
- 检查是否满足等差条件
q - p = r - q。
代码详解:
def is_prime(num):
"""判断是否为素数"""
if num < 2:
return False
for i in range(2, int(num ** 0.5) + 1):
if num % i == 0:
return False
return True
# 找出满足条件的等差质数序列
result = []
primes = [i for i in range(1, 101) if is_prime(i)]
for i in range(len(primes) - 2):
for j in range(i + 1, len(primes) - 1):
for k in range(j + 1, len(primes)):
p, q, r = primes[i], primes[j], primes[k]
if q - p == r - q:
result.append((p, q, r))
print("满足条件的等差质数序列有:", result)11. 检查“连续回文质数对”
题目:找出 1 到 1000 之间的所有回文质数对 (p, q),使得 p < q 且 q 是 p 的下一个回文质数。
思路分析:
- 使用
is_prime(num)和is_palindrome(num)判断质数和回文数。 - 找到 1 到 1000 的所有回文质数,并检查是否连续。
- 将符合条件的回文质数对存储在列表中。
代码详解:
def is_prime(num):
"""判断是否为素数"""
if num < 2:
return False
for i in range(2, int(num ** 0.5) + 1):
if num % i == 0:
return False
return True
def is_palindrome(num):
"""判断是否为回文数"""
return str(num) == str(num)[::-1]
# 找出 1 到 1000 之间所有连续回文质数对
result
= []
palindromic_primes = [num for num in range(1, 1001) if is_prime(num) and is_palindrome(num)]
for i in range(len(palindromic_primes) - 1):
p, q = palindromic_primes[i], palindromic_primes[i + 1]
result.append((p, q))
print("连续回文质数对有:", result)21- 生成式
21.1 列表生成式(List Comprehension) - 掌握
列表生成式是一种简洁的语法,用于基于已有的可迭代对象(如列表、元组、字符串等)快速生成新的列表。它可以替代传统的 for 循环来创建列表,使代码更简洁易读。
基本语法
[表达式 for 变量 in 可迭代对象 if 条件]- 表达式:指定每个元素在列表中的值,通常是一个运算、函数或变量。
- 变量:用于接收每次迭代的元素。
- 条件(可选):为列表生成式添加一个过滤条件,只有满足条件的元素才会包含在新列表中。
示例 1:生成平方数列表
生成 1 到 10 的平方数列表。
squares = [x ** 2 for x in range(1, 11)]
print(squares) # 输出: [1, 4, 9, 16, 25, 36, 49, 64, 81, 100]示例 2:带条件的列表生成式
生成 1 到 20 中的偶数列表。
evens = [x for x in range(1, 21) if x % 2 == 0]
print(evens) # 输出: [2, 4, 6, 8, 10, 12, 14, 16, 18, 20]示例 3:嵌套循环的列表生成式
生成一个乘法表的列表。
multiplication_table = [i * j for i in range(1, 4) for j in range(1, 4)]
print(multiplication_table) # 输出: [1, 2, 3, 2, 4, 6, 3, 6, 9]21.2 字典生成式(Dictionary Comprehension) - 掌握
字典生成式用于基于可迭代对象生成一个新的字典。它的语法与列表生成式类似,但生成的是键值对的字典,而不是列表。
基本语法
{键表达式: 值表达式 for 变量 in 可迭代对象 if 条件}- 键表达式:生成字典中每个键的值。
- 值表达式:生成字典中每个键对应的值。
- 条件(可选):用于过滤键值对,只有满足条件的元素才会包含在字典中。
示例 1:生成数字平方的字典
生成一个字典,键为 1 到 5 的数字,值为它们的平方。
squares_dict = {x: x ** 2 for x in range(1, 6)}
print(squares_dict) # 输出: {1: 1, 2: 4, 3: 9, 4: 16, 5: 25}示例 2:使用条件的字典生成式
生成一个字典,键为 1 到 10 的数字,值为 "偶数" 或 "奇数"。
parity_dict = {x: "偶数" if x % 2 == 0 else "奇数" for x in range(1, 11)}
print(parity_dict)
# 输出: {1: '奇数', 2: '偶数', 3: '奇数', 4: '偶数', 5: '奇数', 6: '偶数', 7: '奇数', 8: '偶数', 9: '奇数', 10: '偶数'}示例 3:字典生成式处理两个列表
使用两个列表生成字典,其中一个列表提供键,另一个提供值。
keys = ["a", "b", "c"]
values = [1, 2, 3]
combined_dict = {k: v for k, v in zip(keys, values)}
print(combined_dict) # 输出: {'a': 1, 'b': 2, 'c': 3}21.3 元组生成式(Tuple Comprehension) - 掌握
严格来说,Python 并没有元组生成式,因为括号 () 被优先解释为生成器表达式。但我们可以通过将生成器表达式转换为 tuple() 来实现类似元组生成式的效果。生成器表达式用于生成一个惰性求值的生成器对象,可以减少内存占用。
基本语法
(表达式 for 变量 in 可迭代对象 if 条件)- 表达式:指定每个元素在生成器中的值。
- 变量:用于接收每次迭代的元素。
- 条件(可选):用于过滤元素,只有满足条件的元素才会包含在生成器中。
示例 1:生成平方数的元组
生成 1 到 10 的平方数元组。
squares_tuple = tuple(x ** 2 for x in range(1, 11))
print(squares_tuple) # 输出: (1, 4, 9, 16, 25, 36, 49, 64, 81, 100)示例 2:带条件的生成器表达式转换为元组
生成 1 到 20 的偶数元组。
evens_tuple = tuple(x for x in range(1, 21) if x % 2 == 0)
print(evens_tuple) # 输出: (2, 4, 6, 8, 10, 12, 14, 16, 18, 20)示例 3:生成嵌套元组
生成乘法表的嵌套元组。
multiplication_table = tuple((i, j, i * j) for i in range(1, 4) for j in range(1, 4))
print(multiplication_table)
# 输出: ((1, 1, 1), (1, 2, 2), (1, 3, 3), (2, 1, 2), (2, 2, 4), (2, 3, 6), (3, 1, 3), (3, 2, 6), (3, 3, 9))21.4 生成式的优缺点(了解)
优点
- 简洁高效:生成式使用一行代码创建数据结构,比传统的循环和条件判断更简洁。
- 可读性高:生成式语法直观清晰,减少代码行数,提升代码的可读性。
- 节省内存:生成器表达式使用惰性求值,不会立即生成所有元素,适合处理大数据量。
缺点
- 复杂性限制:生成式适合简单的逻辑,过于复杂的表达式会降低可读性。
- 调试难度:生成式中嵌套条件判断或多重循环时,调试较为困难。
- 生成器的单次迭代:生成器表达式只能被迭代一次,需注意使用场景。
22- 文件读写
22.1 文件的打开(掌握)
在 Python 中,文件可以通过内置的 open() 函数来打开。open() 函数接受两个主要参数:文件路径和文件模式。
基本语法
file = open("文件路径", "模式")文件模式
常用的文件模式如下:
| 模式 | 含义 |
|---|---|
'r' | 读取模式(默认值),文件必须存在,读取内容。 |
'w' | 写入模式,若文件已存在则清空文件,若不存在则创建新文件。 |
'a' | 追加模式,在文件末尾添加内容。若文件不存在则创建新文件。 |
'b' | 以二进制模式读写文件,用 'rb'、'wb' 等组合形式。 |
'r+' | 读写模式,可以同时读取和写入。 |
'w+' | 读写模式,文件存在则清空,不存在则创建。 |
'a+' | 读写模式,在文件末尾追加内容,不存在则创建。 |
示例:打开文件进行读取
file = open("example.txt", "r")
# 执行文件读取或其他操作
file.close() # 关闭文件22.2 文件的读取(掌握)
Python 提供多种方法来读取文件内容。常用的读取方法有 read()、readline() 和 readlines()。
22.2.1 read() 读取整个文件内容
示例:
file = open("example.txt", "r") content = file.read() print(content) # 输出整个文件内容 file.close()
22.2.2 readline() 逐行读取
示例:
file = open("example.txt", "r") line = file.readline() # 读取文件的第一行 while line: print(line, end="") # 打印每行内容 line = file.readline() # 继续读取下一行 file.close()
22.2.3 readlines() 读取所有行,返回列表
示例:
file = open("example.txt", "r") lines = file.readlines() # 读取所有行,返回列表 for line in lines: print(line, end="") # 打印每行内容 file.close()
22.3 文件的写入(掌握)
使用 'w' 模式或 'w+' 模式可以将内容写入文件,注意 'w' 模式会清空文件内容。写入可以通过 write() 或 writelines() 方法实现。
21.3.1 write() 写入字符串
示例:
file = open("example.txt", "w") file.write("Hello, world!\n") # 写入字符串 file.write("Python 文件写入示例。\n") file.close()
22.3.2 writelines() 写入多行
示例:
file = open("example.txt", "w") lines = ["第一行\n", "第二行\n", "第三行\n"] file.writelines(lines) # 写入多行内容 file.close()
22.4 文件的追加(掌握)
使用 'a' 模式可以在文件末尾追加内容。追加写入不会清空文件内容,而是在已有内容的末尾追加。
示例:
file = open("example.txt", "a") file.write("这是追加的一行。\n") # 在文件末尾追加 file.close()
22.5 使用 with 语句自动管理文件(掌握)
在文件操作中,手动关闭文件是必须的,但有时可能会忘记使用 close()。使用 with 语句可以确保文件操作完成后自动关闭文件,即使在执行过程中发生错误。
示例:使用 with 语句读取文件
with open("example.txt", "r") as file:
content = file.read()
print(content)
# 此时文件已自动关闭示例:使用 with 语句写入文件
with open("example.txt", "w") as file:
file.write("使用 with 语句写入内容。\n")
# 文件已自动关闭22.6 文件指针的移动(了解)
文件指针用于指示当前读写的位置。使用 seek() 和 tell() 可以控制和获取指针的位置。
22.6.1 seek(offset, whence) 移动指针
参数:
offset:指针移动的偏移量。whence:移动的起始位置(0表示文件开头,1表示当前位置,2表示文件末尾)。
示例:
with open("example.txt", "r") as file: file.seek(5) # 将指针移动到文件的第 5 个字节 print(file.read()) # 从第 5 个字节开始读取
22.6.2 tell() 获取当前指针位置
示例:
with open("example.txt", "r") as file: print(file.tell()) # 输出指针当前位置 file.read(5) # 读取 5 个字节 print(file.tell()) # 输出新的指针位置
22.7 文件的其他操作(了解)
Python 提供了一些内置的文件操作方法,如 os 模块中的 remove()、rename()、exists() 等,用于对文件进行删除、重命名、检查是否存在等操作。
删除文件
使用 os.remove() 删除指定文件。
import os
os.remove("example.txt") # 删除文件 example.txt重命名文件
使用 os.rename() 重命名文件。
os.rename("old_name.txt", "new_name.txt") # 重命名文件检查文件是否存在
使用 os.path.exists() 检查文件是否存在。
if os.path.exists("example.txt"):
print("文件存在")
else:
print("文件不存在")22.8 二进制文件的读写(了解)
对于非文本文件(如图片、视频、音频等),需要使用二进制模式读写,以避免编码问题。使用模式 'rb' 读取二进制文件,使用 'wb' 写入二进制文件。
示例:读取二进制文件
with open("example.jpg", "rb") as file:
content = file.read()
print(content) # 输出二进制内容示例:写入二进制文件
with open("example_copy.jpg", "wb") as file:
file.write(content) # 将读取的二进制内容写入新文件22.9 文件读写的常见问题(掌握)
- 忘记关闭文件:在文件操作结束后要记得关闭文件,或使用
with语句自动管理文件。 - 文件路径错误:检查文件路径是否正确,可以使用绝对路径或相对路径。
- 文件编码问题:如果文件包含非 ASCII 字符,建议在打开文件时指定编码,如
open("example.txt", "r", encoding="utf-8")。 - 文件不存在:在打开文件之前检查文件是否存在,避免
FileNotFoundError错误。 - 文件权限错误:确保对文件具有相应的读写权限,否则可能会遇到
PermissionError错误。
23- 面向对象
23.1 面向对象编程的基本概念(掌握)
面向对象编程(OOP)是一种编程范式,它将数据和操作数据的方法封装在一起,称之为对象。Python 是一门面向对象语言,OOP 中的关键概念有以下几个:
- 类(Class):类是创建对象的模板或蓝图,它定义了对象的属性和方法。
- 对象(Object):对象是类的实例,通过类来创建。
- 属性(Attribute):属性是对象的特征或数据,通常是类中定义的变量。
- 方法(Method):方法是对象的行为或操作,通常是类中定义的函数。
示例:定义一个简单的类
class Dog:
# 类属性
species = "Canis lupus"
# 初始化方法(构造函数)
def __init__(self, name, age):
self.name = name # 实例属性
self.age = age # 实例属性
# 实例方法
def bark(self):
print(f"{self.name} says Woof!")
# 创建对象
my_dog = Dog("Buddy", 3)
print(my_dog.name) # 输出: Buddy
my_dog.bark() # 输出: Buddy says Woof!23.2 类的定义和实例化(掌握)
在 Python 中,使用 class 关键字定义类,类名通常遵循首字母大写的命名约定。定义完类后,通过调用类名并传入必要的参数来创建类的实例(即对象)。
定义类:
class ClassName: # 类的内容(属性和方法)实例化对象:
object_name = ClassName(parameters)
示例
class Car:
def __init__(self, make, model):
self.make = make # 实例属性
self.model = model
my_car = Car("Toyota", "Corolla")
print(my_car.make) # 输出: Toyota
print(my_car.model) # 输出: Corolla23.3 __init__ 方法(构造函数)(掌握)
__init__ 方法是类的构造函数,在创建对象时自动调用,用于初始化对象的属性。它通常接收参数来为属性赋初始值。
定义
__init__方法:def __init__(self, 参数1, 参数2): self.属性1 = 参数1 self.属性2 = 参数2
示例
class Book:
def __init__(self, title, author):
self.title = title
self.author = author
my_book = Book("1984", "George Orwell")
print(my_book.title) # 输出: 1984
print(my_book.author) # 输出: George Orwell23.4 实例属性和类属性(掌握)
- 实例属性:每个对象独立拥有的属性,由
self关键字定义。实例属性在不同的对象中可以拥有不同的值。 - 类属性:类本身的属性,不属于任何一个特定的对象,由类名直接访问。类属性在所有对象中共享。
示例
class Animal:
species = "Mammal" # 类属性
def __init__(self, name):
self.name = name # 实例属性
a1 = Animal("Lion")
a2 = Animal("Tiger")
print(a1.species) # 输出: Mammal
print(a2.species) # 输出: Mammal
print(a1.name) # 输出: Lion
print(a2.name) # 输出: Tiger23.5 实例方法和类方法(掌握)
- 实例方法:实例方法是作用于对象的方法,第一个参数为
self,表示该方法属于对象,可以访问对象的属性。 - 类方法:类方法由
@classmethod装饰器定义,第一个参数为cls,表示该方法属于类,可以访问类属性。类方法通常用于创建或操作类级别的数据。
示例
class Circle:
pi = 3.14 # 类属性
def __init__(self, radius):
self.radius = radius # 实例属性
def area(self): # 实例方法
return Circle.pi * (self.radius ** 2)
@classmethod
def set_pi(cls, new_pi): # 类方法
cls.pi = new_pi
c1 = Circle(5)
print(c1.area()) # 输出: 78.5
Circle.set_pi(3.1416)
print(c1.area()) # 输出: 78.54(使用新值 3.1416)23.6 静态方法(掌握)
静态方法不需要传入 self 或 cls 参数,通常不与类或对象的属性进行交互,常用于工具方法。使用 @staticmethod 装饰器定义静态方法。
示例
class Math:
@staticmethod
def add(x, y):
return x + y
result = Math.add(5, 3)
print(result) # 输出: 823.7 封装与私有属性(掌握)
封装是 OOP 的核心思想之一,通过将对象的内部数据隐藏起来,只允许通过特定方法访问。Python 使用双下划线前缀 __ 将属性定义为私有属性,限制外部直接访问。
示例
class Account:
def __init__(self, owner, balance):
self.owner = owner
self.__balance = balance # 私有属性
def deposit(self, amount):
if amount > 0:
self.__balance += amount
def get_balance(self):
return self.__balance
account = Account("Alice", 1000)
account.deposit(500)
print(account.get_balance()) # 输出: 1500
# print(account.__balance) # 访问报错,私有属性23.8 继承(掌握)
继承允许我们创建一个新的类,并从现有类中继承属性和方法。继承使代码重用更高效,新类称为子类,继承的类称为父类或超类。
示例
class Animal:
def speak(self):
print("Animal speaks")
class Dog(Animal): # Dog 类继承 Animal 类
def bark(self):
print("Dog barks")
dog = Dog()
dog.speak() # 调用父类方法,输出: Animal speaks
dog.bark() # 调用子类方法,输出: Dog barks23.9 方法重写(掌握)
方法重写(Override)允许子类重写父类的方法。子类重写的方法可以覆盖父类的方法,实现不同的功能。
示例
class Animal:
def speak(self):
print("Animal speaks")
class Dog(Animal):
def speak(self): # 重写父类方法
print("Dog barks")
dog = Dog()
dog.speak() # 输出: Dog barks23.10 多态(掌握)
多态是指对象在不同的场景中表现出不同的行为。Python 的多态性允许使用相同的方法名调用不同类的实例,而不关心实例的具体类型。
示例
class Animal:
def speak(self):
print("Animal speaks")
class Dog(Animal):
def speak(self):
print("Dog barks")
class Cat(Animal):
def speak(self):
print("Cat meows")
animals = [Dog(), Cat()]
for animal in animals:
animal.speak() # 输出 Dog barks 和 Cat meows23.11 面向对象的优势(了解)
- 封装:将数据和行为封装在一起,提高代码安全性。
- 继承:实现代码重用,减少重复代码。
- 多态:同一方法在不同对象中表现出不同的行为,提高代码的灵活性。
- 抽象:隐藏复杂实现,暴露简单接口,提高代码的可维护性。
24- 面向对象综合案例
案例 1:银行账户系统
需求:
- 创建一个
BankAccount类,用于管理银行账户。 - 该类需要包含以下功能:
- 开户:初始化账户名、账户余额和账户类型(如储蓄、支票)。
- 存款:向账户中添加指定金额。
- 取款:从账户中取出指定金额,余额不足时给出警告。
- 查询余额:显示当前余额。
思路分析:
BankAccount类包含初始化方法__init__来设置账户名称、余额和账户类型。- 定义
deposit和withdraw方法分别用于存款和取款,确保取款时余额足够。 - 定义
get_balance方法用于查询余额。
代码实现:
class BankAccount:
def __init__(self, account_name, initial_balance=0, account_type="Savings"):
self.account_name = account_name
self.balance = initial_balance
self.account_type = account_type
def deposit(self, amount):
if amount > 0:
self.balance += amount
print(f"存入 {amount} 元。当前余额:{self.balance} 元")
else:
print("存款金额必须为正数。")
def withdraw(self, amount):
if amount > self.balance:
print("余额不足,无法取款。")
elif amount > 0:
self.balance -= amount
print(f"取出 {amount} 元。当前余额:{self.balance} 元")
else:
print("取款金额必须为正数。")
def get_balance(self):
print(f"{self.account_name} 的当前余额:{self.balance} 元")
# 测试
account = BankAccount("Alice", 1000)
account.deposit(500)
account.withdraw(300)
account.get_balance()
account.withdraw(1500) # 余额不足案例 2:图书馆系统
需求:
- 创建一个
Book类,包含书籍的基本信息(如标题、作者、ISBN 编号)。 - 创建一个
Library类,用于管理图书馆的藏书和借阅记录。 Library类需要包含以下功能:- 添加书籍:将书籍添加到藏书列表。
- 借书:用户可以借阅指定书籍,若该书已被借出则提示不可用。
- 归还书籍:将书籍归还到图书馆。
思路分析:
Book类包含书籍的基本信息,如标题、作者和 ISBN 编号。Library类包含一个books字典,用于记录图书馆的藏书信息,书籍的可用状态(True表示可用,False表示已借出)。- 在
Library类中定义add_book、borrow_book和return_book方法来管理书籍的借阅和归还。
代码实现:
class Book:
def __init__(self, title, author, isbn):
self.title = title
self.author = author
self.isbn = isbn
class Library:
def __init__(self):
self.books = {}
def add_book(self, book):
if book.isbn not in self.books:
self.books[book.isbn] = {"book": book, "available": True}
print(f"添加书籍:《{book.title}》")
else:
print(f"书籍《{book.title}》已存在于图书馆。")
def borrow_book(self, isbn):
if isbn in self.books:
if self.books[isbn]["available"]:
self.books[isbn]["available"] = False
print(f"成功借出书籍:《{self.books[isbn]['book'].title}》")
else:
print("该书籍已被借出。")
else:
print("该书籍不存在于图书馆。")
def return_book(self, isbn):
if isbn in self.books:
if not self.books[isbn]["available"]:
self.books[isbn]["available"] = True
print(f"成功归还书籍:《{self.books[isbn]['book'].title}》")
else:
print("该书籍已经在馆。")
else:
print("该书籍不存在于图书馆。")
# 测试
library = Library()
book1 = Book("Python Basics", "Author A", "ISBN001")
book2 = Book("Data Science", "Author B", "ISBN002")
library.add_book(book1)
library.add_book(book2)
library.borrow_book("ISBN001")
library.borrow_book("ISBN001") # 已被借出
library.return_book("ISBN001")
library.borrow_book("ISBN003") # 不存在的书籍案例 3:员工管理系统
需求:
- 创建一个基类
Employee,包含员工的基本信息(如姓名和薪资)。 - 创建两个子类
Manager和Developer,继承Employee,并在子类中实现特定的方法和属性。 - 需要提供以下功能:
Manager类可以管理一个员工列表。Developer类可以记录其特定的编程语言。- 打印每个员工的信息,区分不同员工类型。
思路分析:
Employee类作为基类,包含基本信息属性和显示信息的方法。Manager类继承自Employee,包含一个员工列表,并可添加管理的员工。Developer类继承自Employee,包含一个记录编程语言的属性。
代码实现:
class Employee:
def __init__(self, name, salary):
self.name = name
self.salary = salary
def display_info(self):
print(f"员工姓名: {self.name}, 薪资: {self.salary}")
class Manager(Employee):
def __init__(self, name, salary):
super().__init__(name, salary)
self.employees = []
def add_employee(self, employee):
if isinstance(employee, Employee) and employee not in self.employees:
self.employees.append(employee)
print(f"{self.name} 现在管理员工 {employee.name}")
def display_info(self):
super().display_info()
print("管理的员工:")
for emp in self.employees:
print(f"- {emp.name}")
class Developer(Employee):
def __init__(self, name, salary, language):
super().__init__(name, salary)
self.language = language
def display_info(self):
super().display_info()
print(f"编程语言: {self.language}")
# 测试
manager = Manager("Alice", 100000)
dev1 = Developer("Bob", 80000, "Python")
dev2 = Developer("Charlie", 85000, "JavaScript")
manager.add_employee(dev1)
manager.add_employee(dev2)
manager.display_info()
dev1.display_info()
dev2.display_info()25- 数据类型转换
25.1 数据类型转换概述(掌握)
数据类型转换指的是将一个数据类型转换为另一个数据类型。例如,将整数转换为浮点数,将字符串转换为列表等。Python 提供了多种内置函数来实现不同的数据类型转换。
25.2 常见的数据类型转换方法(掌握)
Python 提供的基本数据类型转换函数如下:
| 函数 | 描述 |
|---|---|
int(x) | 将 x 转换为整数 |
float(x) | 将 x 转换为浮点数 |
str(x) | 将 x 转换为字符串 |
list(x) | 将 x 转换为列表 |
tuple(x) | 将 x 转换为元组 |
set(x) | 将 x 转换为集合 |
dict(x) | 将 x 转换为字典(需满足特定结构) |
25.3 数字类型转换(掌握)
Python 中支持整数和浮点数的转换,可以通过 int() 和 float() 函数实现。
25.3.1 整数和浮点数转换
示例:
# 将浮点数转换为整数 num1 = 3.14 int_num1 = int(num1) # 输出: 3 # 将整数转换为浮点数 num2 = 5 float_num2 = float(num2) # 输出: 5.0
25.3.2 字符串和数字的转换
字符串转整数:
str_num = "123" int_num = int(str_num) # 输出: 123字符串转浮点数:
str_float = "3.14" float_num = float(str_float) # 输出: 3.14数字转字符串:
num = 456 str_num = str(num) # 输出: "456"
25.4 字符串与列表/元组的转换(掌握)
字符串、列表和元组之间的转换方法主要依靠 list()、tuple() 和 join() 函数。
25.4.1 字符串转列表和元组
字符串转列表:每个字符将成为列表的一个元素。
text = "hello" text_list = list(text) # 输出: ['h', 'e', 'l', 'l', 'o']字符串转元组:使用
tuple()将字符串转换为元组。text_tuple = tuple(text) # 输出: ('h', 'e', 'l', 'l', 'o')
25.4.2 列表/元组转字符串
列表转字符串:使用
join()方法将列表中的元素合并为字符串。words = ['Python', 'is', 'fun'] sentence = ' '.join(words) # 输出: "Python is fun"元组转字符串:同样使用
join()方法。chars = ('P', 'y', 't', 'h', 'o', 'n') word = ''.join(chars) # 输出: "Python"
25.5 列表、元组、集合的互相转换(掌握)
可以使用 list()、tuple() 和 set() 函数在列表、元组和集合之间进行转换。
24.5.1 列表、元组、集合的转换
列表转元组:
fruits = ['apple', 'banana', 'cherry'] fruits_tuple = tuple(fruits) # 输出: ('apple', 'banana', 'cherry')列表转集合:
fruits_set = set(fruits) # 输出: {'apple', 'banana', 'cherry'}元组转列表:
fruits_list = list(fruits_tuple) # 输出: ['apple', 'banana', 'cherry']集合转列表:
set_to_list = list(fruits_set) # 输出: ['apple', 'banana', 'cherry']
25.6 字典的转换(掌握)
字典的键和值可以分别转换为列表、元组或集合,字典本身可以通过满足一定结构的列表或元组进行转换。
25.6.1 字典转列表/元组/集合
字典键转换为列表:
person = {'name': 'Alice', 'age': 25} keys_list = list(person.keys()) # 输出: ['name', 'age']字典值转换为列表:
values_list = list(person.values()) # 输出: ['Alice', 25]字典键值对转换为元组列表:
items_list = list(person.items()) # 输出: [('name', 'Alice'), ('age', 25)]
25.6.2 列表/元组转字典
列表转字典:列表中的元素需为二元组。
items = [('name', 'Bob'), ('age', 30)] person_dict = dict(items) # 输出: {'name': 'Bob', 'age': 30}元组转字典:与列表转字典相同,要求元组内元素为二元组。
items_tuple = (('name', 'Charlie'), ('age', 35)) person_dict = dict(items_tuple) # 输出: {'name': 'Charlie', 'age': 35}
25.7 常见数据类型转换示例(掌握)
示例 1:混合数据类型列表转字符串
将包含多个不同数据类型的列表元素合并成字符串。
data = [1, 'apple', 3.14]
string_data = ' | '.join(map(str, data))
print(string_data) # 输出: "1 | apple | 3.14"示例 2:字符串列表转整数列表
将一个包含数字字符串的列表转换为整数列表。
str_nums = ["10", "20", "30"]
int_nums = list(map(int, str_nums))
print(int_nums) # 输出: [10, 20, 30]示例 3:将嵌套列表转换为字典
将嵌套列表(每个子列表包含键值对)转换为字典。
data = [["name", "Alice"], ["age", 28], ["city", "New York"]]
data_dict = dict(data)
print(data_dict) # 输出: {'name': 'Alice', 'age': 28, 'city': 'New York'}25.8 数据类型转换的注意事项(掌握)
转换条件:并非所有数据类型都可以互相转换,如将非数值字符串转换为数字会报错。
int("hello") # ValueError: invalid literal for int()精度损失:浮点数转换为整数时会丢失小数部分。
int(3.9) # 输出: 3可变与不可变:列表、字典和集合是可变类型,元组和字符串是不可变类型。数据转换时要注意特性变化。
数据丢失:集合的元素是唯一的,将包含重复元素的列表转换为集合会自动去重。
list_to_set = set([1, 2, 2, 3]) # 输出: {1, 2, 3}
二,常用库(共15个)
1,os模块
import os
# 判断文件是否存在
os.path.exists() # 判断文件或者文件夹是否存在,返回布尔值
os.path.join() # 路径拼接
os.path.join(path1,path2,path3)
os.makedirs() # 创建文件夹
os.getcwd() # 获取当前工作目录,即当前python脚本工作的目录路径
os.chdir("dirname") # 改变当前脚本工作目录;相当于shell下cd
os.curdir # 返回当前目录: ('.')
os.pardir # 获取当前目录的父目录字符串名:('..')
os.makedirs('dirname1/dirname2') # 可生成多层递归目录
os.removedirs('dirname1') # 若目录为空,则删除,并递归到上一级目录,如若也为空,则删除,依此类推
os.mkdir('dirname') # 生成单级目录;相当于shell中mkdir dirname
os.rmdir('dirname') # 删除单级空目录,若目录不为空则无法删除,报错;相当于shell中rmdir dirname
os.listdir('dirname') # 列出指定目录下的所有文件和子目录,包括隐藏文件,并以列表方式打印
os.remove() # 删除一个文件
os.rename("oldname","newname") # 重命名文件/目录
os.stat('path/filename') # 获取文件/目录信息
os.sep # 输出操作系统特定的路径分隔符,win下为"\\",Linux下为"/"
os.linesep # 输出当前平台使用的行终止符,win下为"\t\n",Linux下为"\n"
os.pathsep # 输出用于分割文件路径的字符串 win下为;,Linux下为:
os.name # 输出字符串指示当前使用平台。win->'nt'; Linux->'posix'
os.system("bash command") # 运行shell命令,直接显示
os.environ # 获取系统环境变量
os.path.abspath(path) # 返回path规范化的绝对路径
os.path.split(path) # 将path分割成目录和文件名二元组返回
os.path.dirname(path) # 返回path的目录。其实就是os.path.split(path)的第一个元素
os.path.basename(path) # 返回path最后的文件名。如何path以/或\结尾,那么就会返回空值。即os.path.split(path)的第二个元素
os.path.exists(path) # 如果path存在,返回True;如果path不存在,返回False
os.path.isabs(path) # 如果path是绝对路径,返回True
os.path.isfile(path) # 如果path是一个存在的文件,返回True。否则返回False
os.path.isdir(path) #如果path是一个存在的目录,则返回True。否则返回False
os.path.join(path1[, path2[, ...]]) # 将多个路径组合后返回,第一个绝对路径之前的参数将被忽略
os.path.getatime(path) # 返回path所指向的文件或者目录的最后存取时间
os.path.getmtime(path) # 返回path所指向的文件或者目录的最后修改时间
os.path.getsize(path) # 返回path的大小2,json模块
## JSON格式兼容的是所有语言通用的数据类型,不能支持单一数据类型
# JSON ---------字典
dic = json.loads(s)
# 字典-----------JSON
s = json.dumps(dic)
import json
## 有时保存下来的中文数据打开后发现变成ASCII码,这是需要将ensure_ascii参数设置成False
data = {
'name' : 'name',
'age' : 20,
}
json_str = json.dumps(data,ensure_ascii=False)
# josn.dump
data = {
'name':'name',
'age':20,
}
#讲python编码成json放在那个文件里
filename = 'a.txt'
with open (filename,'w') as f:
json.dump(data ,f)
## json.load
data = {
'name':'name',
'age':20
}
filename = 'a.txt'
with open (filename,'w') as f:
json.dump(data,f)
with open (filename) as f_:
print(json.load(f_))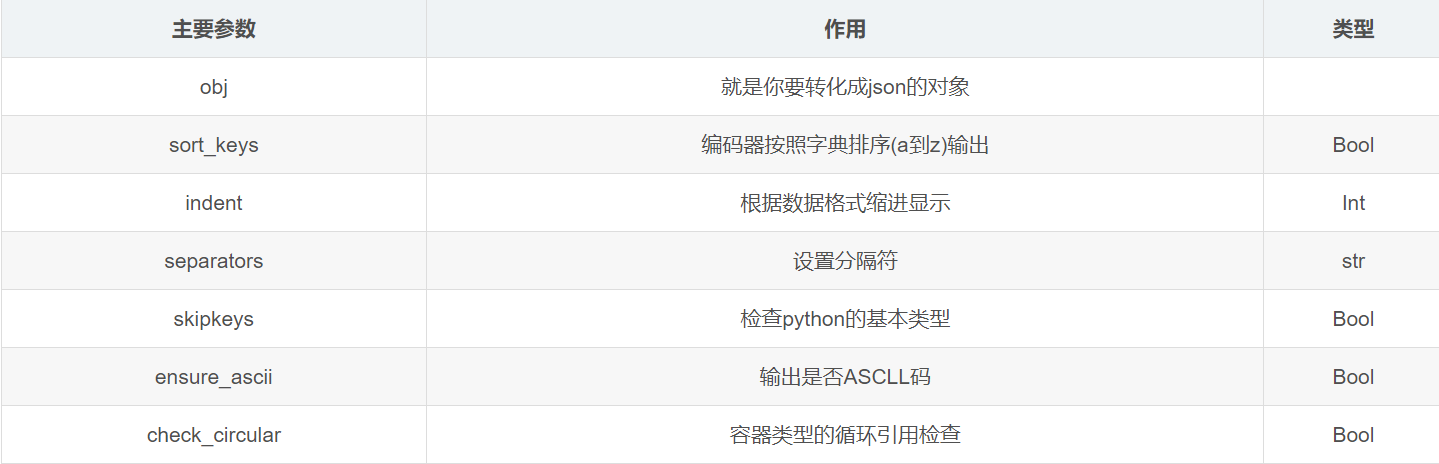
2.1 猴子补丁S
### 在入扣文件处进行猴子补丁
import json
import ujson
def monkey_patch_json():
json.__name__ = 'ujson'
json.dumps = ujson.dumps
json.loads = ujson.loads
monkey_patch_json()3,random模块
a = random.choice('abcdefghijklmn') # 参数也可以是个列表
a = "abcdefghijklmnop1234567890"
b = random.sample(a,3) # 随机取三个值,返回一个列表
num = random.randint(1,100)
1,random.random() # 得到的是 0----1 之间的小数 -------------- 0.6400374661599008
2,random.randint(1,3) # 范围是 [1,3] 包头包尾
3,random.randrange(1,2) # 范围是 [1,3) 顾头不顾尾
4,random.chioce('abcdefghijklmn') # 参数也可以是个列表
5,random.sample(['a','b','c','d'],3) # 随机取三个值,返回一个列表
6,random.uniform(1,3) # 得到 1-------3 之间的浮点数
item = [1,2,3,4,5,6,7,8,9]
7,random.shuffle(item) # 洗牌,打乱顺序 [4, 1, 2, 9, 7, 5, 6, 3, 8]4,string模块
string.ascii_letters # 返回小写字母大写字母字符串
# 'abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ'
string.ascii_uppercase # 返回大写字母的字符串
# 'ABCDEFGHIJKLMNOPQRSTUVWXYZ'
string.ascii_lowercase # 返回小写字母的字符串
# 'abcdefghijklmnopqrstuvwxyz'
string.punctuation # 打印特殊字符
# '!"#$%&'()*+,-./:;<=>?@[\]^_`{|}~'
string.digits # 打印数字
# '0123456789'5,异常处理
5.1 错误类型
## 语法错误 SyntaxError
## 逻辑错误 NameError IndexError ZeroDivisionError ValueError
## 一种是语法上的错误SyntaxError,这种错误应该在程序运行前就修改正确
if
File "<stdin>", line 1
if
^
SyntaxError: invalid syntax
# -------------------------------------------------------------------------------------------
# TypeError:数字类型无法与字符串类型相加
1+’2’
# ValueError:当字符串包含有非数字的值时,无法转成int类型
num=input(">>: ") #输入hello
int(num)
# NameError:引用了一个不存在的名字x
x
# IndexError:索引超出列表的限制
l=['egon','aa']
l[3]
# KeyError:引用了一个不存在的key
dic={'name':'egon'}
dic['age']
# AttributeError:引用的属性不存在
class Foo:
pass
Foo.x
# ZeroDivisionError:除数不能为0
1/05.1 逻辑错误两种处理方式
5.1.1 错误时可以预知的
age = input(">>:").strip()
if age.isdigit(): ## 可以用if 判断避免错误出现
age = int(age) ## age必须是数字,才能转换为int类型
if age > 18:
print("猜大了")
else:
print('猜小了')5.1.2 错误时不可预知的
## 只要抛出异常同级别的代码不会往下运行
try:
##有可能抛出异常的子代码块
except 异常类型1 as e:
pass
except 异常类型2 as e:
pass
....
else:
## 如果被检测的子代码块没有异常发生则运行else
finally:
## 无论有没有异常发生都会运行此代码
## --------------------------------------------------------------------------------------------
## 用法一
try:
print('11111111111')
l = ['aaa','bbbb']
l[3] ## 抛出异常IndexError,该码块同级别的后续代码不会运行
print('222222222222222')
xxx
print('3333333333333333333')
dic = {'a':1}
dic['a']
print('end')
except IndexError as e:
print('异常处理了')
print(e)
except NameError as e:
print('异常处理了')
print(e)
## --------------------------------------------------------------------------------------
# 用法二
print('start')
try:
print('11111111111')
l = ['aaa','bbbb']
l[3] ## 抛出异常IndexError,该码块同级别的后续代码不会运行
print('222222222222222')
# xxx
print('3333333333333333333')
dic = {'a':1}
dic['a']
print('end')
except (IndexError,NameError) as e:
print('异常处理了')
except KeyError as e:
print('字典的key不存在',e)
## ------------------------------------------------------------------------------------------
## 用法三
## 万能异常
print('start')
try:
print('11111111111')
l = ['aaa','bbbb']
l[3] ## 抛出异常IndexError,该码块同级别的后续代码不会运行
print('222222222222222')
# xxx
print('3333333333333333333')
dic = {'a':1}
dic['a']
print('end')
except Exception as e: ## 万能异常,都能匹配上
print('万能异常')
## ----------------------------------------------------------------------------------------
## 方法四
##tyr 不能跟 else 连用
try:
print('11111111111111')
print('33333333333')
print('2222222222222222222')
except Exception as e:
print('所有异常都能匹配到')
else:
print('==============>')
print('end...........')
## ------------------------------------------------------------------------------------------
## 方法五
## finally 可以单独与try配合使用
print('start')
try:
print('11111111111')
l = ['aaa','bbbb']
l[3] ## 抛出异常IndexError,该码块同级别的后续代码不会运行
print('222222222222222')
xxx
print('3333333333333333333')
dic = {'a':1}
dic['a']
print('end')
finally:
## 应该把被检测代码中,回收系统化资源的代码放这里
print('我不处理异常,无论是否发生异常我都会运行')6,打码平台使用
import base64
import json
import requests
def base64_api(uname, pwd, img, typeid):
with open(img, 'rb') as f:
base64_data = base64.b64encode(f.read())
b64 = base64_data.decode()
data = {"username": uname, "password": pwd, "typeid": typeid, "image": b64}
result = json.loads(requests.post("http://api.ttshitu.com/predict", json=data).text)
if result['success']:
return result["data"]["result"]
else:
#!!!!!!!注意:返回 人工不足等 错误情况 请加逻辑处理防止脚本卡死 继续重新 识别
return result["message"]
return ''
if __name__ == "__main__":
img_path = "./code.png"
result = base64_api(uname='xxxxx', pwd='xxxxx', img=img_path, typeid=3)
print(result)
import base64
import json
import requests
# 一、图片文字类型(默认 3 数英混合):
# 1 : 纯数字
# 1001:纯数字2
# 2 : 纯英文
# 1002:纯英文2
# 3 : 数英混合
# 1003:数英混合2
# 4 : 闪动GIF
# 7 : 无感学习(独家)
# 11 : 计算题
# 1005: 快速计算题
# 16 : 汉字
# 32 : 通用文字识别(证件、单据)
# 66: 问答题
# 49 :recaptcha图片识别
# 二、图片旋转角度类型:
# 29 : 旋转类型
#
# 三、图片坐标点选类型:
# 19 : 1个坐标
# 20 : 3个坐标
# 21 : 3 ~ 5个坐标
# 22 : 5 ~ 8个坐标
# 27 : 1 ~ 4个坐标
# 48 : 轨迹类型
#
# 四、缺口识别
# 18 : 缺口识别(需要2张图 一张目标图一张缺口图)
# 33 : 单缺口识别(返回X轴坐标 只需要1张图)
# 五、拼图识别
# 53:拼图识别
def base64_api(uname, pwd, img, typeid):
with open(img, 'rb') as f:
base64_data = base64.b64encode(f.read())
b64 = base64_data.decode()
data = {"username": uname, "password": pwd, "typeid": typeid, "image": b64}
result = json.loads(requests.post("http://api.ttshitu.com/predict", json=data).text)
if result['success']:
return result["data"]["result"]
else:
#!!!!!!!注意:返回 人工不足等 错误情况 请加逻辑处理防止脚本卡死 继续重新 识别
return result["message"]
return ""
if __name__ == "__main__":
img_path = "C:/Users/Administrator/Desktop/file.jpg"
result = base64_api(uname='你的账号', pwd='你的密码', img=img_path, typeid=3)
print(result)7,时间模块
7.1 time 模块
import time
# 时间戳 : 从1970年到现在经过的秒数
time.time() # 时间戳---------用于计算
# 按照某种格式显示时间: 2020-03-30 11:11:11 AM || PM
time.strftime('%Y-%m-%d %H:%M:%S %p') # 2023-06-27 14:24:38 PM
time.strftime('%Y-%m-%d %X') # 2023-06-27 14:24:38
#结构化时间
res = time.localtime() ## --------------获取年月日
print(res) ## time.struct_time(tm_year=2023, tm_mon=6, tm_mday=27, tm_hour=14, tm_min=26, tm_sec=17, tm_wday=1, tm_yday=178, tm_isdst=0)
print(res.tm_year) ## 年
print(res.tm_mon) ## 月
print(res.tm_mday) ## 日
print(res.tm_hour) ## 小时
print(res.tm_min) ## 分钟
print(res.tm_sec) ## 秒
print(res.tm_wday)
print(res.tm_yday)
print(res.tm_isdst)7.2 datetime 模块
import datetime
datetime.datetime.now() ## 2023-06-27 14:38:31.929938
datetime.datetime.now() + datetime.timedelta(days = 3) ## 三天后的时间 2023-06-30 14:40:55.794329
# 参数有 days || secondes || weeks || hours || minutes
# days = 3 || -3 参数可以 为负数7.3 时间格式的转换
import time
1,时间戳 <-----------------> 结构化时间
# 结构化时间 -------------------------> 时间戳
s_time = time.localtime() # 结构化时间
res = time.mktime(s_time)
print(res) # 1687848357.0
# 时间戳 ---------------------------------> 结构化时间
tp_time = time.time()
res = time.localtime(tp_time)
print(res) # time.struct_time(tm_year=2023, tm_mon=6, tm_mday=27, tm_hour=14, tm_min=48, tm_sec=36, tm_wday=1,tm_yday=178, tm_isdst=0)
# 时间戳 --------------------------------> 世界标准时间 --------- 跟本地时间差8小时
tp_time = time.time()
res = time.gmtime(tp_time)
print(res) # time.struct_time(tm_year=2023, tm_mon=6, tm_mday=27, tm_hour=6, tm_min=50, tm_sec=35, tm_wday=1,tm_yday=178, tm_isdst=0)
2, 结构化 <-------------------------> 格式化时间
## time.strptime('%Y-%m-%d %H:%M:%S %p',time.localtime())
res = time.strptime('1988-03-03 11:11:11','%Y-%m-%d %H:%M:%S')
print(res)
## time.struct_time(tm_year=1988, tm_mon=3, tm_mday=3, tm_hour=11, tm_min=11, tm_sec=11, tm_wday=3, tm_yday=63, tm_isdst=-1)
'1988-03-03 11:11:11' + 7 -----------------------> 结构化时间
s_time = time.strptime('1988-03-03 11:11:11','%Y-%m-%d %H:%M:%S') # 结构化时间
miao = time.mktime(s_time) + 7 * 86400 ## 得到时间戳
struct_time = time.localtime(miao) ## 得到结构化时间
res = time.strftime('%Y-%m-%d %X',time.localtime(miao)) # 格式化时间
print(res) # 1988-03-10 11:11:117.4 ,了解
import time
## linix 操作系统上常见
print(time.asctime()) # Tue Jun 27 15:26:23 20238, sys模块
1 sys.argv # 命令行参数List,第一个元素是程序本身路径,用于获取终端里的参数
2 sys.exit(n) # 退出程序,正常退出时exit(0)
3 sys.version # 获取Python解释程序的版本信息
4 sys.maxint # 最大的Int值
5 sys.path # 返回模块的搜索路径,初始化时使用PYTHONPATH环境变量的值
6 sys.platform # 返回操作系统平台名称8.1 打印进度条
import time
def process():
recv_size = 0
total_size = 333333
while recv_size < total_size:
# 下载了1024个字节数据
time.sleep(0.05)
recv_size += 1024
if recv_size > total_size:
recv_size = total_size
percent = recv_size / total_size
res = int(50 * percent) * "#"
# 打印进度条
print('\r[%-50s] %d%%' % (res,100 * percent) ,end='')
process()
## [##################################################] 100%9,shutii 模块
import shutill
# 将文件内容拷贝到另一个文件中
shutil.copyfileobj(open('old.xml','r'), open('new.xml', 'w'))
# 仅拷贝权限。内容、组、用户均不变
shutil.copymode('f1.log', 'f2.log') #目标文件必须存在
# 拷贝文件
shutil.copyfile('f1.log', 'f2.log') #目标文件无需存在
# 仅拷贝状态的信息,包括:mode bits, atime, mtime, flags
shutil.copystat('f1.log', 'f2.log') #目标文件必须存在
# 拷贝文件和权限
shutil.copy('f1.log', 'f2.log')
# 拷贝文件和状态信息
shutil.copy2('f1.log', 'f2.log')
# 递归的去拷贝文件夹
shutil.copytree('folder1', 'folder2', ignore=shutil.ignore_patterns('*.pyc', 'tmp*'))
# 目标目录不能存在,注意对folder2目录父级目录要有可写权限,ignore的意思是排除
shutil.copytree('f1', 'f2', symlinks=True, ignore=shutil.ignore_patterns('*.pyc', 'tmp*'))
'''
通常的拷贝都把软连接拷贝成硬链接,即对待软连接来说,创建新的文件
'''
#递归的去删除文件
shutil.rmtree('folder1')
#递归的去移动文件,它类似mv命令,其实就是重命名。
shutil.move('folder1', 'folder3')
# 创建压缩包并返回文件路径,例如:zip、tar
# 创建压缩包并返回文件路径,例如:zip、tar
base_name: 压缩包的文件名,也可以是压缩包的路径。只是文件名时,则保存至当前目录,否则保存至指定路径,
# 如 data_bak =>保存至当前路径
# 如:/tmp/data_bak =>保存至/tmp/
format: 压缩包种类,“zip”, “tar”, “bztar”,“gztar”
root_dir: 要压缩的文件夹路径(默认当前目录)
owner: 用户,默认当前用户
group: 组,默认当前组
logger: 用于记录日志,通常是logging.Logger对象
#将 /data 下的文件打包放置当前程序目录
ret = shutil.make_archive("data_bak", 'gztar', root_dir='/data')
#将 /data下的文件打包放置 /tmp/目录
ret = shutil.make_archive("/tmp/data_bak", 'gztar', root_dir='/data')
#shutil 对压缩包的处理是调用 ZipFile 和 TarFile 两个模块来进行的,详细:
import zipfile
# 压缩
z = zipfile.ZipFile('laxi.zip', 'w')
z.write('a.log')
z.write('data.data')
z.close()
# 解压
z = zipfile.ZipFile('laxi.zip', 'r')
z.extractall(path='.')
z.close()
import tarfile
# 压缩
t=tarfile.open('/tmp/egon.tar','w')
t.add('/test1/a.py',arcname='a.bak')
t.add('/test1/b.py',arcname='b.bak')
t.close()
# 解压
t=tarfile.open('/tmp/egon.tar','r')
t.extractall('/egon')
t.close()10,pickle模块(有兼容性问题,了解就行)
import pickle
res = pickle.dumps({1,2,3,4,5})
print(res)
# b'\x80\x04\x95\x0f\x00\x00\x00\x00\x00\x00\x00\x8f\x94(K\x01K\x02K\x03K\x04K\x05\x90.'
res = pickle.loads(res)
print(res)
# {1, 2, 3, 4, 5}
# coding:utf-8
import pickle
with open('a.pkl',mode='wb') as f:
# 一:在python3中执行的序列化操作如何兼容python2
# python2不支持protocol>2,默认python3中protocol=4
# 所以在python3中dump操作应该指定protocol=2
pickle.dump('你好啊',f,protocol=2)
with open('a.pkl', mode='rb') as f:
# 二:python2中反序列化才能正常使用
res=pickle.load(f)
print(res)11,xml模块
<?xml version="1.0"?>
<data>
<country name="Liechtenstein">
<rank updated="yes">2</rank>
<year>2008</year>
<gdppc>141100</gdppc>
<neighbor name="Austria" direction="E"/>
<neighbor name="Switzerland" direction="W"/>
</country>
<country name="Singapore">
<rank updated="yes">5</rank>
<year>2011</year>
<gdppc>59900</gdppc>
<neighbor name="Malaysia" direction="N"/>
</country>
<country name="Panama">
<rank updated="yes">69</rank>
<year>2011</year>
<gdppc>13600</gdppc>
<neighbor name="Costa Rica" direction="W"/>
<neighbor name="Colombia" direction="E"/>
</country>
</data>
xml协议在各个语言里的都 是支持的,在python中可以用以下模块操作xml:
# print(root.iter('year')) #全文搜索
# print(root.find('country')) #在root的子节点找,只找一个
# print(root.findall('country')) #在root的子节点找,找所有
import xml.etree.ElementTree as ET
tree = ET.parse("xmltest.xml")
root = tree.getroot()
print(root.tag)
#遍历xml文档
for child in root:
print('========>',child.tag,child.attrib,child.attrib['name'])
for i in child:
print(i.tag,i.attrib,i.text)
#只遍历year 节点
for node in root.iter('year'):
print(node.tag,node.text)
#---------------------------------------
import xml.etree.ElementTree as ET
tree = ET.parse("xmltest.xml")
root = tree.getroot()
#修改
for node in root.iter('year'):
new_year=int(node.text)+1
node.text=str(new_year)
node.set('updated','yes')
node.set('version','1.0')
tree.write('test.xml')
#删除node
for country in root.findall('country'):
rank = int(country.find('rank').text)
if rank > 50:
root.remove(country)
tree.write('output.xml')
#在country内添加(append)节点year2
import xml.etree.ElementTree as ET
tree = ET.parse("a.xml")
root=tree.getroot()
for country in root.findall('country'):
for year in country.findall('year'):
if int(year.text) > 2000:
year2=ET.Element('year2')
year2.text='新年'
year2.attrib={'update':'yes'}
country.append(year2) #往country节点下添加子节点
tree.write('a.xml.swap')
自己创建xml文档:
import xml.etree.ElementTree as ET
new_xml = ET.Element("namelist")
name = ET.SubElement(new_xml,"name",attrib={"enrolled":"yes"})
age = ET.SubElement(name,"age",attrib={"checked":"no"})
sex = ET.SubElement(name,"sex")
sex.text = '33'
name2 = ET.SubElement(new_xml,"name",attrib={"enrolled":"no"})
age = ET.SubElement(name2,"age")
age.text = '19'
et = ET.ElementTree(new_xml) #生成文档对象
et.write("test.xml", encoding="utf-8",xml_declaration=True)
ET.dump(new_xml) #打印生成的格式12,configparser模块(导入某种格式的配置文件)
## 配置文件内容
[section1]
k1 = v1
k2:v2
user=egon
age=18
is_admin=true
salary=31
[section2]
k1 = v112.1 读取
import configparser
config=configparser.ConfigParser()
config.read('a.cfg') # 读取配置文件
#查看所有的标题
res=config.sections() #['section1', 'section2']
print(res)
#查看标题section1下所有key=value的key
options=config.options('section1')
print(options) #['k1', 'k2', 'user', 'age', 'is_admin', 'salary']
#查看标题section1下所有key=value的(key,value)格式
item_list=config.items('section1')
print(item_list)
#[('k1', 'v1'), ('k2', 'v2'), ('user', 'egon'), ('age', '18'), ('is_admin', 'true'), ('salary', '31')]
#查看标题section1下user的值=>字符串格式
val=config.get('section1','user')
print(val) #egon
#查看标题section1下age的值=>整数格式
val1=config.getint('section1','age')
print(val1) #18
#查看标题section1下is_admin的值=>布尔值格式
val2=config.getboolean('section1','is_admin')
print(val2) #True
#查看标题section1下salary的值=>浮点型格式
val3=config.getfloat('section1','salary')
print(val3) #31.012.2 改写
import configparser
config=configparser.ConfigParser()
config.read('a.cfg',encoding='utf-8')
#删除整个标题section2
config.remove_section('section2')
#删除标题section1下的某个k1和k2
config.remove_option('section1','k1')
config.remove_option('section1','k2')
#判断是否存在某个标题
print(config.has_section('section1'))
#判断标题section1下是否有user
print(config.has_option('section1',''))
#添加一个标题
config.add_section('egon')
#在标题egon下添加name=egon,age=18的配置
config.set('egon','name','egon')
config.set('egon','age',18) #报错,必须是字符串
#最后将修改的内容写入文件,完成最终的修改
config.write(open('a.cfg','w'))13 hashlib 模块
# hash是一类算法,该算法根据传入的内容,经过运算得到一串哈希值
# hash值的特单
1,传入的内容一样,则得到的结果一样
2,无论传多大内容,得到的hash值长度一样
3,不能反向破解14 subprocess模块
import subprocess
'''
sh-3.2# ls /Users/egon/Desktop |grep txt$
mysql.txt
tt.txt
事物.txt
'''
## 查看 /Users/jieli/Desktop 下的文件列表
res1=subprocess.Popen('ls /Users/jieli/Desktop',shell=True,stdout=subprocess.PIPE,stderr=subprocess.PIPE)
# shell = True 意思是调一个终端 stdout 是正确结果的输出管道 stderr 是接受错误结果的输出管道
# res1 是对象
print(res2.stdout.read()) # 打印正确的结果,得到的格式是字节,解码用的是系统的编码格式,mac为utf-8
print(res1.stderr.read()) # 打印错误的结果,得到的是字节格式,解码用的是系统的编码格式,windows为gbk
res=subprocess.Popen('grep txt$',shell=True,stdin=res1.stdout,stdout=subprocess.PIPE)
print(res.stdout.read().decode('utf-8'))
#等同于上面,但是上面的优势在于,一个数据流可以和另外一个数据流交互,可以通过爬虫得到结果然后交给grep
res1=subprocess.Popen('ls /Users/jieli/Desktop |grep txt$',shell=True,stdout=subprocess.PIPE)
print(res1.stdout.read().decode('utf-8'))
#windows下:
# dir | findstr 'test*'
# dir | findstr 'txt$'
import subprocess
res1=subprocess.Popen(r'dir C:\Users\Administrator\PycharmProjects\test\函数备课',shell=True,stdout=subprocess.PIPE)
res=subprocess.Popen('findstr test*',shell=True,stdin=res1.stdout,
stdout=subprocess.PIPE)
print(res.stdout.read().decode('gbk')) #subprocess使用当前系统默认编码,得到结果为bytes类型,在windows下需要用gbk解码15,日志模块(logging)
14.1 日志级别
import logging
CRITICAL = 50 #FATAL = CRITICAL
ERROR = 40
WARNING = 30 #WARN = WARNING
INFO = 20
DEBUG = 10
NOTSET = 0 #不设置14.2 默认级别为warning,默认打印到终端
import logging
logging.debug('调试debug')
logging.info('消息info')
logging.warning('警告warn') ## WARNING:root:警告warn
logging.error('错误error') ## ERROR:root:错误error
logging.critical('严重critical') ## CRITICAL:root:严重critical
'''
WARNING:root:警告warn
ERROR:root:错误error
CRITICAL:root:严重critical
'''14.3 为logging模块指定全局配置,针对所有logger有效,控制打印到文件中
'''
可在logging.basicConfig()函数中可通过具体参数来更改logging模块默认行为,可用参数有
filename:用指定的文件名创建FiledHandler(后边会具体讲解handler的概念),这样日志会被存储在指定的文件中。
filemode:文件打开方式,在指定了filename时使用这个参数,默认值为“a”还可指定为“w”。
format:指定handler使用的日志显示格式。
datefmt:指定日期时间格式。
level:设置rootlogger(后边会讲解具体概念)的日志级别
stream:用指定的stream创建StreamHandler。可以指定输出到sys.stderr,sys.stdout或者文件,默认为sys.stderr。若同时列出了 filename和stream两个参数,则stream参数会被忽略。
'''
## 例如:
logging.basicConfig(
format = '%(asctime)s - %(name)s - %(levelname)s - %(module)s' # 就这样自定义格式
)
format参数中可能用到的格式化串:
%(name)s # Logger的名字
%(levelno)s # 数字形式的日志级别
%(levelname)s # 文本形式的日志级别
%(pathname)s # 调用日志输出函数的模块的完整路径名,可能没有
%(filename)s # 调用日志输出函数的模块的文件名
%(module)s # 调用日志输出函数的模块名
%(funcName)s # 调用日志输出函数的函数名
%(lineno)d # 调用日志输出函数的语句所在的代码行
%(created)f # 当前时间,用UNIX标准的表示时间的浮 点数表示
%(relativeCreated)d # 输出日志信息时的,自Logger创建以 来的毫秒数
%(asctime)s # 字符串形式的当前时间。默认格式是 “2003-07-08 16:49:45,896”。逗号后面的是毫秒
%(thread)d # 线程ID。可能没有
%(threadName)s # 线程名。可能没有
%(process)d # 进程ID。可能没有
%(message)s # 用户输出的消息14.4 使用例子
#========使用
import logging
logging.basicConfig(
## 写到文件里的编码格式以系统编码格式为准,Windows为gbk
filename='access.log', ## 日志输出的位置
format='%(asctime)s - %(name)s - %(levelname)s -%(module)s: %(message)s', ## 一个日志输出的格式
datefmt='%Y-%m-%d %H:%M:%S %p', ## 输出里的时间格式
level=10 ## 日志错误级别
)
logging.debug('调试debug')
logging.info('消息info')
logging.warning('警告warn')
logging.error('错误error')
logging.critical('严重critical')
#========结果
access.log内容:
2017-07-28 20:32:17 PM - root - DEBUG -test: 调试debug
2017-07-28 20:32:17 PM - root - INFO -test: 消息info
2017-07-28 20:32:17 PM - root - WARNING -test: 警告warn
2017-07-28 20:32:17 PM - root - ERROR -test: 错误error
2017-07-28 20:32:17 PM - root - CRITICAL -test: 严重critical14.5 logging模块的Formatter,Handler,Logger,Filter对象
#logger:产生日志的对象
#Filter:过滤日志的对象
#Handler:接收日志然后控制打印到不同的地方,FileHandler用来打印到文件中,StreamHandler用来打印到终端
#Formatter对象:可以定制不同的日志格式对象,然后绑定给不同的Handler对象使用,以此来控制不同的Handler的日志格式
'''
critical=50
error =40
warning =30
info = 20
debug =10
'''
import logging
#1、logger对象:负责产生日志,然后交给Filter过滤,然后交给不同的Handler输出
logger=logging.getLogger(__file__)
#2、Filter对象:不常用,略
#3、Handler对象:接收logger传来的日志,然后控制输出
h1=logging.FileHandler('t1.log') #打印到文件
h2=logging.FileHandler('t2.log') #打印到文件
h3=logging.StreamHandler() #打印到终端
#4、Formatter对象:日志格式
formmater1=logging.Formatter(
'%(asctime)s - %(name)s - %(levelname)s -%(module)s: %(message)s',
datefmt='%Y-%m-%d %H:%M:%S %p',
)
formmater2=logging.Formatter(
'%(asctime)s : %(message)s',
datefmt='%Y-%m-%d %H:%M:%S %p',
)
formmater3=logging.Formatter('%(name)s %(message)s',)
#5、为Handler对象绑定格式
h1.setFormatter(formmater1)
h2.setFormatter(formmater2)
h3.setFormatter(formmater3)
#6、将Handler添加给logger并设置日志级别
logger.addHandler(h1)
logger.addHandler(h2)
logger.addHandler(h3)
logger.setLevel(10)
#7、测试
logger.debug('debug')
logger.info('info')
logger.warning('warning')
logger.error('error')
logger.critical('critical')14.6 Logger与Handler的级别
### logger是第一级过滤,然后才能到handler,我们可以给logger和handler同时设置level
#验证
import logging
form=logging.Formatter(
'%(asctime)s - %(name)s - %(levelname)s -%(module)s: %(message)s',
datefmt='%Y-%m-%d %H:%M:%S %p',
)
ch=logging.StreamHandler()
ch.setFormatter(form)
# ch.setLevel(10)
ch.setLevel(20)
l1=logging.getLogger('root')
# l1.setLevel(20)
l1.setLevel(10)
l1.addHandler(ch)
l1.debug('l1 debug')14.7 Logger的继承(了解)
import logging
formatter=logging.Formatter('%(asctime)s - %(name)s - %(levelname)s -%(module)s: %(message)s',
datefmt='%Y-%m-%d %H:%M:%S %p',)
ch=logging.StreamHandler()
ch.setFormatter(formatter)
logger1=logging.getLogger('root')
logger2=logging.getLogger('root.child1')
logger3=logging.getLogger('root.child1.child2')
logger1.addHandler(ch)
logger2.addHandler(ch)
logger3.addHandler(ch)
logger1.setLevel(10)
logger2.setLevel(10)
logger3.setLevel(10)
logger1.debug('log1 debug')
logger2.debug('log2 debug')
logger3.debug('log3 debug')
'''
2017-07-28 22:22:05 PM - root - DEBUG -test: log1 debug
2017-07-28 22:22:05 PM - root.child1 - DEBUG -test: log2 debug
2017-07-28 22:22:05 PM - root.child1 - DEBUG -test: log2 debug
2017-07-28 22:22:05 PM - root.child1.child2 - DEBUG -test: log3 debug
2017-07-28 22:22:05 PM - root.child1.child2 - DEBUG -test: log3 debug
2017-07-28 22:22:05 PM - root.child1.child2 - DEBUG -test: log3 debug
'''14.8 应用
14.8.1 logging配置
"""
logging配置
"""
import os
import logging.config
# 定义三种日志输出格式 开始
standard_format = '[%(asctime)s][%(threadName)s:%(thread)d][task_id:%(name)s][%(filename)s:%(lineno)d]' \
'[%(levelname)s][%(message)s]' #其中name为getlogger指定的名字
simple_format = '[%(levelname)s][%(asctime)s][%(filename)s:%(lineno)d]%(message)s'
id_simple_format = '[%(levelname)s][%(asctime)s] %(message)s'
# 定义日志输出格式 结束
logfile_dir = os.path.dirname(os.path.abspath(__file__)) # log文件的目录
logfile_name = 'all2.log' # log文件名
# 如果不存在定义的日志目录就创建一个
if not os.path.isdir(logfile_dir):
os.mkdir(logfile_dir)
# log文件的全路径
logfile_path = os.path.join(logfile_dir, logfile_name)
# log配置字典
LOGGING_DIC = {
'version': 1,
'disable_existing_loggers': False,
'formatters': {
'standard': {
'format': standard_format
},
'simple': {
'format': simple_format
},
},
'filters': {},
'handlers': {
#打印到终端的日志
'console': {
'level': 'DEBUG',
'class': 'logging.StreamHandler', # 打印到屏幕
'formatter': 'simple'
},
#打印到文件的日志,收集info及以上的日志
'default': {
'level': 'DEBUG',
'class': 'logging.handlers.RotatingFileHandler', # 保存到文件
'formatter': 'standard',
'filename': logfile_path, # 日志文件
'maxBytes': 1024*1024*5, # 日志大小 5M
'backupCount': 5,
'encoding': 'utf-8', # 日志文件的编码,再也不用担心中文log乱码了
},
},
'loggers': {
#logging.getLogger(__name__)拿到的logger配置
'': {
'handlers': ['default', 'console'], # 这里把上面定义的两个handler都加上,即log数据既写入文件又打印到屏幕
'level': 'DEBUG',
'propagate': True, # 向上(更高level的logger)传递
},
},
}
def load_my_logging_cfg():
logging.config.dictConfig(LOGGING_DIC) # 导入上面定义的logging配置
logger = logging.getLogger(__name__) # 生成一个log实例
logger.info('It works!') # 记录该文件的运行状态
if __name__ == '__main__':
load_my_logging_cfg()14.8.2 使用
"""
MyLogging Test
"""
import time
import logging
import my_logging # 导入自定义的logging配置
logger = logging.getLogger(__name__) # 生成logger实例
def demo():
logger.debug("start range... time:{}".format(time.time()))
logger.info("中文测试开始。。。")
for i in range(10):
logger.debug("i:{}".format(i))
time.sleep(0.2)
else:
logger.debug("over range... time:{}".format(time.time()))
logger.info("中文测试结束。。。")
if __name__ == "__main__":
my_logging.load_my_logging_cfg() # 在你程序文件的入口加载自定义logging配置
demo()14.8.3 注意注意注意
"""
MyLogging Test
"""
import time
import logging
import my_logging # 导入自定义的logging配置
logger = logging.getLogger(__name__) # 生成logger实例
def demo():
logger.debug("start range... time:{}".format(time.time()))
logger.info("中文测试开始。。。")
for i in range(10):
logger.debug("i:{}".format(i))
time.sleep(0.2)
else:
logger.debug("over range... time:{}".format(time.time()))
logger.info("中文测试结束。。。")
if __name__ == "__main__":
my_logging.load_my_logging_cfg() # 在你程序文件的入口加载自定义logging配置
demo()14.8.4 另外一个django的配置,瞄一眼就可以,跟上面的一样
#logging_config.py
LOGGING = {
'version': 1,
'disable_existing_loggers': False,
'formatters': {
'standard': {
'format': '[%(asctime)s][%(threadName)s:%(thread)d][task_id:%(name)s][%(filename)s:%(lineno)d]'
'[%(levelname)s][%(message)s]'
},
'simple': {
'format': '[%(levelname)s][%(asctime)s][%(filename)s:%(lineno)d]%(message)s'
},
'collect': {
'format': '%(message)s'
}
},
'filters': {
'require_debug_true': {
'()': 'django.utils.log.RequireDebugTrue',
},
},
'handlers': {
#打印到终端的日志
'console': {
'level': 'DEBUG',
'filters': ['require_debug_true'],
'class': 'logging.StreamHandler',
'formatter': 'simple'
},
#打印到文件的日志,收集info及以上的日志
'default': {
'level': 'INFO',
'class': 'logging.handlers.RotatingFileHandler', # 保存到文件,自动切
'filename': os.path.join(BASE_LOG_DIR, "xxx_info.log"), # 日志文件
'maxBytes': 1024 * 1024 * 5, # 日志大小 5M
'backupCount': 3,
'formatter': 'standard',
'encoding': 'utf-8',
},
#打印到文件的日志:收集错误及以上的日志
'error': {
'level': 'ERROR',
'class': 'logging.handlers.RotatingFileHandler', # 保存到文件,自动切
'filename': os.path.join(BASE_LOG_DIR, "xxx_err.log"), # 日志文件
'maxBytes': 1024 * 1024 * 5, # 日志大小 5M
'backupCount': 5,
'formatter': 'standard',
'encoding': 'utf-8',
},
#打印到文件的日志
'collect': {
'level': 'INFO',
'class': 'logging.handlers.RotatingFileHandler', # 保存到文件,自动切
'filename': os.path.join(BASE_LOG_DIR, "xxx_collect.log"),
'maxBytes': 1024 * 1024 * 5, # 日志大小 5M
'backupCount': 5,
'formatter': 'collect',
'encoding': "utf-8"
}
},
'loggers': {
#logging.getLogger(__name__)拿到的logger配置
'': {
'handlers': ['default', 'console', 'error'],
'level': 'DEBUG',
'propagate': True,
},
#logging.getLogger('collect')拿到的logger配置
'collect': {
'handlers': ['console', 'collect'],
'level': 'INFO',
}
},
}
# -----------
# 用法:拿到俩个logger
logger = logging.getLogger(__name__) #线上正常的日志
collect_logger = logging.getLogger("collect") #领导说,需要为领导们单独定制领导们看的日志14.9 直奔主题,常规使用
14.9.1 日志级别与配置
import logging
# 在
# 一:日志配置
logging.basicConfig(
# 1、日志输出位置:1、终端 2、文件
# filename='access.log', # 不指定,默认打印到终端
# 2、日志格式
format='%(asctime)s - %(name)s - %(levelname)s -%(module)s: %(message)s',
# 3、时间格式
datefmt='%Y-%m-%d %H:%M:%S %p',
# 4、日志级别
# critical => 50
# error => 40
# warning => 30
# info => 20
# debug => 10
level=30,
)
# 二:输出日志
logging.debug('调试debug')
logging.info('消息info')
logging.warning('警告warn')
logging.error('错误error')
logging.critical('严重critical')
'''
# 注意下面的root是默认的日志名字
WARNING:root:警告warn
ERROR:root:错误error
CRITICAL:root:严重critical
'''14.9.2 日志配置字典(setting.py)
"""
logging配置
在 setting.py中定义
"""
import os
# 1、定义三种日志输出格式,日志中可能用到的格式化串如下
# %(name)s Logger的名字
# %(levelno)s 数字形式的日志级别
# %(levelname)s 文本形式的日志级别
# %(pathname)s 调用日志输出函数的模块的完整路径名,可能没有
# %(filename)s 调用日志输出函数的模块的文件名
# %(module)s 调用日志输出函数的模块名
# %(funcName)s 调用日志输出函数的函数名
# %(lineno)d 调用日志输出函数的语句所在的代码行
# %(created)f 当前时间,用UNIX标准的表示时间的浮 点数表示
# %(relativeCreated)d 输出日志信息时的,自Logger创建以 来的毫秒数
# %(asctime)s 字符串形式的当前时间。默认格式是 “2003-07-08 16:49:45,896”。逗号后面的是毫秒
# %(thread)d 线程ID。可能没有
# %(threadName)s 线程名。可能没有
# %(process)d 进程ID。可能没有
# %(message)s用户输出的消息
# 2、强调:其中的%(name)s为getlogger时指定的名字
## 这些是预先定义好的自定义格式
standard_format = '[%(asctime)s][%(threadName)s:%(thread)d][task_id:%(name)s][%(filename)s:%(lineno)d]' \
'[%(levelname)s][%(message)s]'
simple_format = '[%(levelname)s][%(asctime)s][%(filename)s:%(lineno)d]%(message)s'
test_format = '%(asctime)s] %(message)s'
# 3、日志配置字典
LOGGING_DIC = {
'version': 1,
'disable_existing_loggers': False,
'formatters': {
# 自己自定义的日志格式,可以自己改
'standard': {
# 自己定义的自定义格式
'format': standard_format
},
'simple': {
'format': simple_format
},
'test': {
'format': test_format
},
},
'filters': {},
## 日志的接受者,不同的handle可以使日志输出到不同位置
'handlers': {
#打印到终端的日志
'console': {
'level': 'DEBUG',
'class': 'logging.StreamHandler', # 打印到屏幕
## 指定输出格式
'formatter': 'simple'
},
#打印到文件的日志,收集info及以上的日志
'default': {
'level': 'DEBUG',
'class': 'logging.handlers.RotatingFileHandler', # 保存到文件,日志轮转
'formatter': 'standard',
# 可以定制日志文件路径
# BASE_DIR = os.path.dirname(os.path.abspath(__file__)) # log文件的目录
# LOG_PATH = os.path.join(BASE_DIR,'a1.log')
'filename': 'a1.log', # 日志文件
'maxBytes': 1024*1024*5, # 日志大小 5M
'backupCount': 5,
'encoding': 'utf-8', # 日志文件的编码,再也不用担心中文log乱码了
},
## 测试用的日志格式
'other': {
'level': 'DEBUG',
'class': 'logging.FileHandler', # 保存到文件
'formatter': 'test',
'filename': 'a2.log',##拿到项目的跟文件夹 os.path.dirname(os.path.dirname(__file__))
'encoding': 'utf-8',
},
},
# 负责产生日志,产生的日志传递给handler负责处理
'loggers': {
#logging.getLogger(__name__)拿到的logger配置
'kkk': {
# kkk 产生的日志传给谁
'handlers': ['default', 'console'], # 这里把上面定义的两个handler都加上,即log数据既写入文件又打印到屏幕
'level': 'DEBUG', # loggers(第一层日志级别关限制)--->handlers(第二层日志级别关卡限制)
'propagate': False, # 默认为True,向上(更高level的logger)传递,通常设置为False即可,否则会一份日志向上层层# 传递
},
'bbb': {
# kkk 产生的日志传给谁
'handlers': ['console'], # 这里把上面定义的两个handler都加上,即log数据既写入文件又打印到屏幕
'level': 'DEBUG', # loggers(第一层日志级别关限制)--->handlers(第二层日志级别关卡限制)
'propagate': False, # 默认为True,向上(更高level的logger)传递,通常设置为False即可,否则会一份日志向上层层# 传递
},
'专门的采集': {
'handlers': ['other',],
'level': 'DEBUG',
'propagate': False,
},
},
}14.9.3 使用
import settings
# !!!强调!!!
# 1、logging是一个包,需要使用其下的config、getLogger,可以如下导入
# 可能不能正常使用
# import logging.config
# import logging.getLogger
# 2、也可以使用如下导入
# from logging import config,getLogger
from logging import config # 这样连同logging.getLogger都一起导入了,然后使用前缀logging.config.
from logging import getLogger # 用于获取配置文件里的日志生产者
# 3、加载配置
# 把配置好的配置字典扔进去
logging.config.dictConfig(settings.LOGGING_DIC)
logger1 = getLogger("kkk") ## kkk 是可以同时向终端和文件里输出日志的
logger2 = getLogger('bbb') ### bbb 只向终端里输出日志
# 4、输出日志
logger1=logging.getLogger('用户交易')
logger1.info('egon儿子alex转账3亿冥币')
# logger2=logging.getLogger('专门的采集') # 名字传入的必须是'专门的采集',与LOGGING_DIC中的配置唯一对应
# logger2.debug('专门采集的日志')14.9.4 日志轮换
## 'class': 'logging.handlers.RotatingFileHandler', # 保存到文件,日志轮转
## 'maxBytes': 1024*1024*5, # 日志大小 5M
## 'backupCount': 5, 最多保运几份
#打印到文件的日志,收集info及以上的日志
'default': {
'level': 'DEBUG',
'class': 'logging.handlers.RotatingFileHandler', # 保存到文件,日志轮转
'formatter': 'standard',
# 可以定制日志文件路径
# BASE_DIR = os.path.dirname(os.path.abspath(__file__)) # log文件的目录
# LOG_PATH = os.path.join(BASE_DIR,'a1.log')
'filename': 'a1.log', # 日志文件
'maxBytes': 1024*1024*5, # 日志大小 5M
'backupCount': 5,
'encoding': 'utf-8', # 日志文件的编码,再也不用担心中文log乱码了
},15,struct模块
## 该模块可以把一个类型,如数字,转成固定长度的bytes
import struct
bytes = struct.pack('i',1000) ## 拿到长度固定的四个字节
num = struct.unpack('i',bytes)[0] ## 结果是元祖,元祖里拿到数字拿到数字
三,常用API速查
1,字符串
1.1 字符串查找方法
startswith() #以指定字符串开头;
Endswith() # 以指定字符串结尾;
find() # 返回字符串第一次出现的位置;
Rfind() # 返回最后一次出现的位置;
Count() # 返回某个字符总共出现的次数;
Isallnum() # 判断所有字符是不是全是数字或者字母;2.2 去除首位信息
Strip() # 去除字符串首位指定信息; 默认去除首位空格
Lstrip() # 去除左边的指定信息;
Rtrip() # 去除右边的指定信息;3.3 大小写转换
Capitalize() # 产生新的字符串,首字母大写;
Title() # 每个单词首字母大写;
Upper() # 所有字母转换成大写;
Lower() # 所有字母转换成小写;
Swapcase() # 所有字母大小写转换;4.4 格式排版:
# 1. Center() ljust() rjust() 用于实现排版;
# 默认用空格填充
# 2. 接受两个参数,第一个参数是要实现的长度,第二个字符是要填充的字符
s = "aini"
s.center(10,"*") # 用*左右填充让s达到10的长度
# 格式化
"我是{0},我喜欢数字{1:*^8}".format("艾尼","666")
# :后面是依次是 填充的字符 对齐方式(<^> 左中右) 格式化长度
# 如:1:*^20 用*号居中对齐,长度为 20 个字符
# 数字格式化5.5 数字格式化
| 数字 | 格式 | 输出 | 描述 |
|---|---|---|---|
| 3.1415926 | { :.2f } | 3.14 | 保留小数点后两位 |
| 3.1415926 | { :+.2f } | 3.14 | 带符号的保留小数点后两位 |
| 2.71828 | { :.0f } | 3 | 不带小数 |
| 5 | { :0>2d } | 5 | 数字补零(填充左边,宽度为2) |
| 5 | { :x<4d } | 5xxx | 数字补x(填充右边,宽度为4) |
| 10 | { :x<4d } | 10xx | 数字补x(填充右边,宽度为4) |
| 1000000 | { :, } | 1,000,000 | 以逗号分割的数字形式 |
| 0.25 | { :.2% } | 25.00% | 百分比格式 |
6.6 其他方法:
Isalnum() # 是否全为数字或字母;
Isalpha() # 是不是都是字母或汉字组成;
Isdigit() # 是不是都是由数字组成;
Isspace() # 检测是否为空白字符;
Isupper() # 检测是否为大写字母;
Islower() # 检测是否为小写字母;2,列表
| 方法 | 要点 | 描述 |
|---|---|---|
| list.append(x) | 增加元素 | 将元素x增加到列表list尾部 |
| list.extend(aList) | 增加元素 | 将列表aList素有元素加到列表list尾部 |
| list.insert(index,x) | 增加元素 | 将列表list指定index处插入元素x |
| list.remove(x) | 删除元素 | 删除列表中首次出现的指定元素x |
| list.pop(index) | 删除元素 | 删除index处的元素并返回,默认删除最后一个元素并返回 |
| list.clear() | 删除所有元素 | 删除原数,不会删除列表对象 |
| list.index(x) | 访问元素 | 返回第一个x的索引,若不存在则抛出异常 |
| list.count(x) | 计数 | 返回元素x在列表中出现的次数 |
| len(list) | 返回列表长度 | 返回类表中总元素的个数 |
| 方法 | 要点 | 描述 |
|---|---|---|
| list.reverse() | 翻转列表 | 所有元素原地翻转 |
| list.sort() | 排序 | 所有元素原地排序 |
| list.copy() | 浅拷贝 | 返回列表对象的浅拷贝 |
3,字典
# update(),把第二个字典加到第一个字典里面
a.update(b) # 把字典b加到a里面
# 可以用 del 删除键值对
# Del a[‘name’] del a[‘sex’]
# 可以用 clear()方法删除所有键值对;
# Pop()方法可以删除键值对,并将值返回
a.pop("name")
# Popitem()方法:随机删除键值对,并将其返回
# 序列解包
a.values()
a.items()4,Python常用内置函数
4.1 round() 函数
round()是一个处理数值的内置函数,它返回浮点数x的四舍五入值
4.2 all() 和 any()
all()和any(),用于判断可迭代对象中的元素是否为True。它们返回布尔值True或False
numbers = [1, 2, 3, 4, 5]
if all(num > 0 for num in numbers):
print("All numbers are positive")
else:
print("There are some non-positive numbers")
if any(num > 4 for num in numbers):
print("At least one number is greater than 4")
else:
print("No number is greater than 4")4.3 lambda函数
lambda x: x + 5
这个Lambda函数可以像下面这样使用:
add_five = lambda x: x + 5
result = add_five(10)
print(result) # 输出 154.4 sorted()函数
sorted()是一个内置函数,它用于对可迭代对象进行排序。 sorted()函数接受一个可迭代对象作为参数,并返回一个新的已排序的列表。
sorted(iterable, key=None, reverse=False)
# iterable: 需要排序的可迭代对象,例如列表、元组、集合、字典等。
#key(可选参数): 用于指定排序的关键字。key是一个函数,它将作用于iterable中的每个元素,并返回一个用于排序的关键字。默认为None,表示按照元素的大小进行排序。
# reverse(可选参数): 用于指定排序的顺序。如果设置为True,则按照逆序排序。默认为False,表示按照正序排序。numbers = [3, 1, 4, 1, 5, 9, 2, 6, 5, 3, 5]
sorted_numbers = sorted(numbers)
print(sorted_numbers) # 输出结果为 [1, 1, 2, 3, 3, 4, 5, 5, 5, 6, 9]
words = ["apple", "banana", "cherry", "date"]
sorted_words = sorted(words, key=len)
print(sorted_words) # 输出结果为 ["date", "apple", "banana", "cherry"]
numbers = [(1, 2), (3, 4), (2, 1), (4, 3)]
sorted_numbers = sorted(numbers, key=lambda x: x[1])
print(sorted_numbers) # 输出结果为 [(2, 1), (1, 2), (4, 3), (3, 4)]
# 在上面的示例中,第一个示例对一个整数列表进行排序,第二个示例对一个字符串列表按照字符串长度进行排序,第三个示例对一个元组列表按照元组中第二个元素进行排序,其中使用了lambda表达式作为key参数来指定排序方式。4.5 map()函数
map(函数名,可迭代对象)
map函数是一种高阶函数,它接受一个函数和一个可迭代对象作为参数,返回一个新的可迭代对象,
map得到的是一个迭代器
# 其中每个元素都是将原可迭代对象中的元素应用给定函数后的结果。
# 可以简单理解为对可迭代对象中的每个元素都执行同一个操作,返回一个新的结果集合。
# 需要注意的是,map函数返回的是一个迭代器对象,因此如果要使用它的结果,需要将它转换为一个列表list()、元组tuple()或集合set()和其他可迭代对象。
map函数的一些应用
1.用来批量接收变量
n,m = map(int,input().split())
2.对可迭代对象进行批量处理返回列表map
m = map("".join,[["a","b","c"],["d","e","f"]])
print(m) -> ["abc","def"]
3.配合lambda函数达到自己想要的效果
numbers = [1, 2, 3, 4, 5]
doubled_numbers = map(lambda x: x * 2, numbers)
print(list(doubled_numbers)) -> [2, 4, 6, 8, 10]4.5 filter()函数
filter() 函数是 Python 内置函数之一,它用于过滤序列中的元素,返回一个满足条件的新序列。
filter() 函数的语法如下:
my_list = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
result = filter(lambda x: x % 2 == 0, my_list)
print(list(result)) # 输出 [2, 4, 6, 8, 10]
在这个例子中,lambda x: x % 2 == 0 是一个 lambda 函数,用于判断一个数是否为偶数。filter() 函数将这个 lambda 函数作为参数,对列表 my_list 进行过滤,最后返回一个新列表,其中包含 my_list 中所有的偶数。4.6 ASCII码的函数
ord() # 接收字符转换ASCII码
chr() # 接收ASCII码转换字符4.7 转进制函数
# 其它进制通用转10进制
int("x",y) # x是你要转的数,而y是这个数是由什么进制表示的,
# 当y为0时就按x的前缀来看如 0bx 二进制,0b 0o 0x,分别是二,八,十六
# 10进制转其他进制
hex() # 转16
oct() # 转8
# 有一个函数很适合10进制转其他各种进制
divmod(x,y)
#其作用是同时返回两个数的商和余数。
# 所以要这样接收它的值 a,b = divmod(x,y)4.8 列表
Python中的list是一个非常重要的数据类型,可以用来存储多个值,包括数字、字符串、对象等等。
以下是一些常见的list函数及其示例:
append() - 将一个元素添加到list的末尾
fruits = ['apple', 'banana', 'cherry']
fruits.append('orange')
print(fruits) # ['apple', 'banana', 'cherry', 'orange']
extend() - 将一个list的所有元素添加到另一个list的末尾
fruits = ['apple', 'banana', 'cherry']
more_fruits = ['orange', 'mango', 'grape']
fruits.extend(more_fruits)
print(fruits) # ['apple', 'banana', 'cherry', 'orange', 'mango', 'grape']
insert() - 在指定的位置插入一个元素
fruits = ['apple', 'banana', 'cherry']
fruits.insert(1, 'orange')
print(fruits) # ['apple', 'orange', 'banana', 'cherry']
remove() - 删除指定的元素
fruits = ['apple', 'banana', 'cherry']
fruits.remove('banana')
print(fruits) # ['apple', 'cherry']
pop() - 删除指定位置的元素(默认为最后一个元素),并返回该元素的值
fruits = ['apple', 'banana', 'cherry']
last_fruit = fruits.pop()
print(last_fruit) # 'cherry'
print(fruits) # ['apple', 'banana']
index() - 返回指定元素在list中的索引位置
fruits = ['apple', 'banana', 'cherry']
banana_index = fruits.index('banana')
print(banana_index) # 1
count() - 返回指定元素在list中出现的次数
fruits = ['apple', 'banana', 'cherry', 'banana', 'banana']
banana_count = fruits.count('banana')
print(banana_count) # 3
sort() - 将list中的元素进行排序
fruits = ['apple', 'banana', 'cherry']
fruits.sort()
print(fruits) # ['apple', 'banana', 'cherry']
reverse() - 将list中的元素翻转
fruits = ['apple', 'banana', 'cherry']
fruits.reverse()
print(fruits) # ['cherry', 'banana', 'apple']
len() - 返回list中元素的数量
fruits = ['apple', 'banana', 'cherry']
num_fruits = len(fruits)
print(num_fruits) # 3
copy() - 返回一个list的副本
fruits = ['apple', 'banana', 'cherry']
fruits_copy = fruits.copy()
print(fruits_copy) # ['apple', 'banana', 'cherry']
clear() - 删除list中的所有元素
fruits = ['apple', 'banana', 'cherry']
fruits.clear()
print(fruits) # []
max() - 返回list中最大的元素
numbers = [5, 10, 3, 8, 15]
max_num = max(numbers)
print(max_num) # 15
min() - 返回list中最小的元素
numbers = [5, 10, 3, 8, 15]
min_num = min(numbers)
print(min_num) # 3
sum() - 返回list中所有元素的和(仅适用于数字类型的list)
numbers = [5, 10, 3, 8, 15]
sum_nums = sum(numbers)
print(sum_nums) # 41
any() - 如果list中至少有一个元素为True,则返回True
bool_list = [False, True, False]
has_true = any(bool_list)
print(has_true) # True
all() - 如果list中的所有元素都为True,则返回True
bool_list = [True, True, True]
all_true = all(bool_list)
print(all_true) # True
enumerate() - 返回一个枚举对象,其中包含list中每个元素的索引和值
fruits = ['apple', 'banana', 'cherry']
for index, fruit in enumerate(fruits):
print(index, fruit)
# 0 apple
# 1 banana
# 2 cherry
map() - 对list中的每个元素应用函数,并返回结果的list
numbers = [1, 2, 3, 4]
squares = list(map(lambda x: x ** 2, numbers))
print(squares) # [1, 4, 9, 16]
filter() - 返回list中符合条件的元素的子集
numbers = [1, 2, 3, 4, 5, 6]
even_nums = list(filter(lambda x: x % 2 == 0, numbers))
print(even_nums) # [2, 4, 6]
reduce() - 对list中的元素应用函数,将其归约为单个值
from functools import reduce
numbers = [1, 2, 3, 4]
sum_nums = reduce(lambda x, y: x + y, numbers)
print(sum_nums) # 10
zip() - 将多个list的元素配对,返回一个元组的list
fruits = ['apple', 'banana', 'cherry']
colors = ['red', 'yellow', 'red']
fruit_colors = list(zip(fruits, colors))
print(fruit_colors) # [('apple', 'red'), ('banana', 'yellow'), ('cherry', 'red')]
sorted() - 返回一个新的已排序的list
numbers = [3, 2, 1, 5, 4]
sorted_nums = sorted(numbers)
print(sorted_nums) # [1, 2, 3, 4, 5]
join() - 将list中的字符串连接成一个字符串
fruits = ['apple', 'banana', 'cherry']
fruit_string = ', '.join(fruits)
print(fruit_string) # 'apple, banana, cherry'
slice() - 返回一个list的子集,根据索引的起始和结束位置
fruits = ['apple', 'banana', 'cherry', 'orange', 'grape']
subset = fruits[1:4]
print(subset) # ['banana', 'cherry', 'orange']
希望这些函数能够帮助你更好地使用Python的list类型。4.9 元祖
Python元组是不可变序列,它不支持在原地修改元素。因此,Python元组的函数相对较少。
以下是Python元组的所有函数:
count
count方法返回元组中指定元素的数量。
my_tuple = ('apple', 'banana', 'apple', 'orange', 'banana', 'apple')
count = my_tuple.count('apple')
print(count) # 输出:3
index
index方法返回元组中指定元素第一次出现的索引。
my_tuple = ('apple', 'banana', 'apple', 'orange', 'banana', 'apple')
index = my_tuple.index('orange')
print(index) # 输出:3
len
len方法返回元组中元素的数量。
my_tuple = ('apple', 'banana', 'orange')
length = len(my_tuple)
print(length) # 输出:3
tuple
tuple函数用于将一个可迭代对象转换为元组。
my_list = [1, 2, 3]
my_tuple = tuple(my_list)
print(my_tuple) # 输出:(1, 2, 3)
zip
zip函数将多个可迭代对象的对应元素打包成元组,返回一个包含这些元组的迭代器。
fruits = ('apple', 'banana', 'orange')
quantities = (5, 2, 3)
prices = (1.2, 1.5, 0.8)
# 将三个元组打包成一个迭代器
inventory = zip(fruits, quantities, prices)
# 遍历迭代器中的元素
for item in inventory:
print(item)
# 输出:
# ('apple', 5, 1.2)
# ('banana', 2, 1.5)
# ('orange', 3, 0.8)
sorted
sorted函数返回一个按指定顺序排序后的可迭代对象,可以接收一个关键字参数key来指定排序的关键字。
my_tuple = (3, 2, 1)
sorted_tuple = sorted(my_tuple)
print(sorted_tuple) # 输出:[1, 2, 3]
# 按绝对值大小排序
my_tuple = (-3, 2, -1)
sorted_tuple = sorted(my_tuple, key=abs)
print(sorted_tuple) # 输出:[-1, 2, -3]
reversed
reversed函数返回一个迭代器,包含按相反顺序排列的可迭代对象中的元素。
my_tuple = ('apple', 'banana', 'orange')
reversed_tuple = reversed(my_tuple)
for item in reversed_tuple:
print(item)
# 输出:
# orange
# banana
# apple
继续
max
max函数返回可迭代对象中最大的元素,可以接收一个关键字参数key来指定比较的关键字。
my_tuple = (3, 2, 1)
max_element = max(my_tuple)
print(max_element) # 输出:3
# 按绝对值大小比较
my_tuple = (-3, 2, -1)
max_element = max(my_tuple, key=abs)
print(max_element) # 输出:-3
min
min函数返回可迭代对象中最小的元素,可以接收一个关键字参数key来指定比较的关键字。
my_tuple = (3, 2, 1)
min_element = min(my_tuple)
print(min_element) # 输出:1
# 按绝对值大小比较
my_tuple = (-3, 2, -1)
min_element = min(my_tuple, key=abs)
print(min_element) # 输出:-1
sum
sum函数返回可迭代对象中所有元素的和,可以接收一个可选参数start指定求和的起始值。
my_tuple = (3, 2, 1)
sum_value = sum(my_tuple)
print(sum_value) # 输出:6
# 指定求和的起始值为5
my_tuple = (3, 2, 1)
sum_value = sum(my_tuple, 5)
print(sum_value) # 输出:11
all
all函数返回可迭代对象中所有元素都为真值(即不为False、0、None等)时返回True,否则返回False。
my_tuple = (1, 2, 3)
result = all(my_tuple)
print(result) # 输出:True
my_tuple = (1, 2, 0)
result = all(my_tuple)
print(result) # 输出:False
any
any函数返回可迭代对象中至少有一个元素为真值(即不为False、0、None等)时返回True,否则返回False。
my_tuple = (0, False, None)
result = any(my_tuple)
print(result) # 输出:False
my_tuple = (0, False, 1)
result = any(my_tuple)
print(result) # 输出:True4.10 字典
Python字典(dictionary)是一个无序的键值对集合。Python中有许多内置函数可以操作字典。
以下是一些常用的函数及其示例:
创建字典
# 创建一个空字典
my_dict = {}
# 创建一个非空字典
my_dict = {'apple': 1, 'banana': 2, 'orange': 3}
访问字典
# 获取字典中指定键对应的值
value = my_dict['apple']
print(value) # 输出:1
# 使用get()方法获取字典中指定键对应的值
value = my_dict.get('banana')
print(value) # 输出:2
# 获取字典中所有键的列表
keys = list(my_dict.keys())
print(keys) # 输出:['apple', 'banana', 'orange']
# 获取字典中所有值的列表
values = list(my_dict.values())
print(values) # 输出:[1, 2, 3]
修改字典
# 修改字典中指定键对应的值
my_dict['apple'] = 4
print(my_dict) # 输出:{'apple': 4, 'banana': 2, 'orange': 3}
# 使用update()方法修改字典中的值
my_dict.update({'apple': 5, 'orange': 6})
print(my_dict) # 输出:{'apple': 5, 'banana': 2, 'orange': 6}
删除字典
# 删除字典中指定键值对
del my_dict['apple']
print(my_dict) # 输出:{'banana': 2, 'orange': 6}
# 删除字典中所有键值对
my_dict.clear()
print(my_dict) # 输出:{}
其他函数
# 获取字典中键值对的数量
num_items = len(my_dict)
print(num_items) # 输出:0
# 检查字典中是否存在指定键
if 'apple' in my_dict:
print('Yes') # 输出:No
# 复制字典
new_dict = my_dict.copy()
print(new_dict) # 输出:{}
遍历字典
# 遍历字典中所有键值对
for key, value in my_dict.items():
print(key, value)
# 遍历字典中所有键
for key in my_dict.keys():
print(key)
# 遍历字典中所有值
for value in my_dict.values():
print(value)
设置默认值
# 使用setdefault()方法设置默认值
my_dict.setdefault('apple', 0)
print(my_dict) # 输出:{'banana': 2, 'orange': 6, 'apple': 0}
合并字典
# 使用update()方法合并字典
dict1 = {'apple': 1, 'banana': 2}
dict2 = {'orange': 3, 'pear': 4}
dict1.update(dict2)
print(dict1) # 输出:{'apple': 1, 'banana': 2, 'orange': 3, 'pear': 4}
# 使用**运算符合并字典
dict1 = {'apple': 1, 'banana': 2}
dict2 = {'orange': 3, 'pear': 4}
dict3 = {**dict1, **dict2}
print(dict3) # 输出:{'apple': 1, 'banana': 2, 'orange': 3, 'pear': 4}
字典推导式
# 创建字典推导式
my_dict = {i: i*2 for i in range(5)}
print(my_dict) # 输出:{0: 0, 1: 2, 2: 4, 3: 6, 4: 8}
反转字典
# 反转字典中的键值对
my_dict = {'apple': 1, 'banana': 2, 'orange': 3}
reversed_dict = {value: key for key, value in my_dict.items()}
print(reversed_dict) # 输出:{1: 'apple', 2: 'banana', 3: 'orange'}
排序字典
# 按键排序
my_dict = {'apple': 1, 'banana': 2, 'orange': 3}
sorted_dict = {key: my_dict[key] for key in sorted(my_dict)}
print(sorted_dict) # 输出:{'apple': 1, 'banana': 2, 'orange': 3}
# 按值排序
my_dict = {'apple': 1, 'banana': 2, 'orange': 3}
sorted_dict = {key: value for key, value in sorted(my_dict.items(), key=lambda item: item[1])}
print(sorted_dict) # 输出:{'apple': 1, 'banana': 2, 'orange': 3}
过滤字典
# 过滤字典中满足条件的键值对
my_dict = {'apple': 1, 'banana': 2, 'orange': 3}
filtered_dict = {key: value for key, value in my_dict.items() if value > 1}
print(filtered_dict) # 输出:{'banana': 2, 'orange': 3}
计数器
# 使用collections模块中的Counter类创建计数器
from collections import Counter
my_list = ['apple', 'banana', 'apple', 'orange', 'banana', 'apple']
my_counter = Counter(my_list)
print(my_counter) # 输出:Counter({'apple': 3, 'banana': 2, 'orange': 1})
# 获取计数器中指定元素的数量
count = my_counter['apple']
print(count) # 输出:3
# 获取计数器中出现次数最多的元素和出现次数
most_common = my_counter.most_common(1)
print(most_common) # 输出:[('apple', 3)]4.11 集合
以下是Python set对象支持的一些常用方法:
add(): 将一个元素添加到set中,如果元素已经存在,什么都不会发生。
fruits = {'apple', 'banana', 'orange'}
fruits.add('kiwi')
print(fruits) # {'orange', 'banana', 'kiwi', 'apple'}
clear(): 移除set中的所有元素。
fruits = {'apple', 'banana', 'orange'}
fruits.clear()
print(fruits) # set()
copy(): 返回set的一个副本。
fruits = {'apple', 'banana', 'orange'}
fruits_copy = fruits.copy()
print(fruits_copy) # {'orange', 'banana', 'apple'}
difference(): 返回一个包含set和另一个set或iterable中不同元素的新set。也可以直接减 eg:fruits - more_fruits
fruits = {'apple', 'banana', 'orange'}
more_fruits = {'banana', 'kiwi', 'pineapple'}
diff_fruits = fruits.difference(more_fruits)
print(diff_fruits) # {'orange', 'apple'}
discard(): 从set中移除一个元素,如果元素不存在,什么都不会发生。
fruits = {'apple', 'banana', 'orange'}
fruits.discard('banana')
print(fruits) # {'orange', 'apple'}
intersection(): 返回一个包含set和另一个set或iterable中共同元素的新set。也可以直接交 eg:fruits & more_fruits
fruits = {'apple', 'banana', 'orange'}
more_fruits = {'banana', 'kiwi', 'pineapple'}
common_fruits = fruits.intersection(more_fruits)
print(common_fruits) # {'banana'}
isdisjoint(): 如果set和另一个set或iterable没有共同元素,返回True,否则返回False。也可以直接交然后判断 eg:return fruits & more_fruits == set()
fruits = {'apple', 'banana', 'orange'}
more_fruits = {'kiwi', 'pineapple'}
print(fruits.isdisjoint(more_fruits)) # True
issubset(): 如果set是另一个set的子集,返回True,否则返回False。
也可以直接交然后判断是不是等于自身 eg:return fruits & more_fruits == fruits
fruits = {'apple', 'banana', 'orange'}
more_fruits = {'banana', 'orange', 'kiwi', 'pineapple'}
print(fruits.issubset(more_fruits)) # False
issuperset(): 如果set是另一个set的超集,返回True,否则返回False。
fruits = {'apple', 'banana', 'orange'}
more_fruits = {'banana', 'orange'}
print(fruits.issuperset(more_fruits)) # True
pop(): 移除并返回set中的一个元素,如果set为空,抛出KeyError异常。
fruits = {'apple', 'banana', 'orange'}
print(fruits.pop()) # 'orange'
print(fruits) # {'apple', 'banana'}
remove(): 从set中移除一个元素,如果元素不存在,抛出KeyError异常。
fruits = {'apple', 'banana', 'orange'}
fruits.remove('banana')
print(fruits) # {'orange', 'apple'}
symmetric_difference(): 返回一个包含set和另一个set或iterable中不重复元素的新set
symmetric_difference_update(): 将set和另一个set或iterable中不重复的元素更新到set中。
fruits = {'apple', 'banana', 'orange'}
more_fruits = {'banana', 'kiwi', 'pineapple'}
fruits.symmetric_difference_update(more_fruits)
print(fruits) # {'orange', 'kiwi', 'pineapple', 'apple'}
union(): 返回一个包含set和另一个set或iterable中所有元素的新set。
不可以+,除了 union() 方法,我们还可以使用 | 运算符来实现两个 set 的并集
fruits = {'apple', 'banana', 'orange'}
more_fruits = {'banana', 'kiwi', 'pineapple'}
all_fruits = fruits.union(more_fruits)
print(all_fruits) # {'kiwi', 'apple', 'pineapple', 'orange', 'banana'}
update(): 将set和另一个set或iterable中所有元素更新到set中。
fruits = {'apple', 'banana', 'orange'}
more_fruits = {'banana', 'kiwi', 'pineapple'}
fruits.update(more_fruits)
print(fruits) # {'kiwi', 'apple', 'pineapple', 'orange', 'banana'}
difference_update(): 将set和另一个set或iterable中不同的元素更新到set中。
fruits = {'apple', 'banana', 'orange'}
more_fruits = {'banana', 'kiwi', 'pineapple'}
fruits.difference_update(more_fruits)
print(fruits) # {'orange', 'apple'}
intersection_update(): 将set和另一个set或iterable中共同的元素更新到set中。
fruits = {'apple', 'banana', 'orange'}
more_fruits = {'banana', 'kiwi', 'pineapple'}
fruits.intersection_update(more_fruits)
print(fruits) # {'banana'}4.12 字符串处理函数
大小写处理
s,s1 = "aaaBBBccc", "123456"
s.upper() # 将字符串全部大写 AAABBBCCC
s.lower() # 将字符串全部小写 aaabbbccc
s.swapcase() # 将s大小写反转 AAAbbbCCC
字符判断
isdigit() , isnumeric # 判断字符串中是否全是数字字符
print(list(map(lambda x:x.isdigit(),[Z,Z2]))) # [False, True]
isdigit:是否为数字字符,包括Unicode数字,单字节数字,双字节全角数字,不包括汉字数字,罗马数字、小数
isnumeric:是否所有字符均为数值字符,包括Unicode数字、双字节全角数字、罗马数字、汉字数字,不包括小数。
s.isalpha() # 判断字符串中是否全为字母
s.isalnum() # 判断字符串中是否全为字母或者数字4.13 callable()
## 判断一个对象能不能调用
def func():
pass
class Foo:
pass
print(callable(Foo)) ## true
print(callable(func)) ## true4.14 dir()----查看属性
class Foo:
pass
obj = Foo()
print(dir(obj)) ## 查看obj的属性
'''
['__class__', '__delattr__', '__dict__', '__dir__', '__doc__', '__eq__', '__format__', '__ge__', '__getattribute__', '__gt__', '__hash__', '__init__', '__init_subclass__', '__le__', '__lt__', '__module__', '__ne__', '__new__', '__reduce__', '__reduce_ex__', '__repr__', '__setattr__', '__sizeof__', '__str__', '__subclasshook__', '__weakref__']
'''4.15 enumerate()
## 既能拿到索引,又能拿到值
lis = ['a','b','c','d','f']
for i,v in enumerate(lis):
print(i,v)
# 0 a
# 1 b
# 2 c
# 3 d
# 4 f4.16 eval()
## 执行字符串里的表达式
res = eval('1 + 2')
res = eval('{'name':'aini','age':22}')
print(res)
## {'name':'aini','age':22}
## 拿到的就是字典类型4.17 frozenset()
s = frozenset({1,2,3,4,5,6}) ## 得到不可变集合4.18 hash()
## 传入不可变类型,得到一个hash值
res = hash('aini')
print(res) ## -39472239622209066494.19 help()
## 查看文档注释4.20 isinstance()
## 判断一个对象是不是一个类的实例
class Foo:
pass
obj = Foo()
## 判断obj是不是Foo的实例化
isinstance(obj,Foo)
## 判断列表,字典都可以用
isinstance([],list)
isinstance({{'name':'aini','age':22}},dict)四,Python进阶知识
1,编码相关
1.1 指定默认的读文件的解码格式保证不乱码
这不是注释,第一行是固定格式 #coding:用什么编码格式读文件
# coding:utg-8 (如果写代码时指定则就是用什么方式编码,如果读文件时指定,则以什么格式解码)
# 代码内容
#Python3里的str类型默认直接存成Unicode所以不存在乱码
#·若要保证Python2的str类型也不乱码
x = u"艾尼你好" # 前面加上u,意思就是Unicode编码注:Python3默认用utf-8解码; Python2用ASCII码解码
2, 读写文件
2.1 控制文件读写内容的模式:t和b
# 强调:读写不能单独使用,必须跟r/w/a连用
open()方法,with 语法
1,t模式(默认的模式)
# 读写都以str(Unicode)为单位
# 必须指定encoding="utf-8"
# 必须是文本文件才可以指定编码
2,b模式
# 是对字节进行操作
# 不用指定编码
#文件操作基本流程
1,打开文件
# window系统路径分割问题
# 解决方案一:推荐
f = open(r'C:\a\b\c\aini.txt')
# 解决方案二:open这函数已经解决好了,右斜杠也可以
f = open('C:/a/b/c/aini.txt)
2,操作文件
f = open('./aini.txt',mode='r',encoding='utf-8')
res = f.read()
# 指针会停在最后,所以第二次读的时候没内容,需要重新打开文件,重新读取
# 会读取所有内容
3,关闭文件
f.close() #回收操作系统资源2.2 文件操作的模式
# 文件操作模式
# r w a 默认都是t模式,对文本进行操作(rt,wt,at)
# rb wb ab 对字节进行操作
# a 是追加模式,会往文件末尾开始写,w会把源文件清空掉
# rt+ 可读可写,文件不存在直接报错
# wt+ 可读可写,
# 指针移动
# 指针移动的单位都是bytes字节为单位
# 只有一种特殊情况
# t模式下的read(n),n代表的是字符个数
with open('./aini.txt',mode='rt',encoding='utf-8') as f:
f.read(4) # 四个字符
### 注意: 只有0模式在t模式下使用
f.seek(n,模式) # n值得是指针移动的字节个数,n可以是负数,可以倒着移动
# 模式
# 0 参照的是文件开头位置
# 1 参照的是当前指针的所造位置
# 2 参照物是文件末尾
f.tell ## 获取指针当前位置3,函数参数详解
3.1 位置参数--------关键字参数---------混合使用
1,位置实参:在函数调用阶段, 按照从左到有的顺序依次传入的值
# 特点:按照顺序与形参一一对应
2 关键字参数
# 关键字实参:在函数调用阶段,按照key=value的形式传入的值
# 特点:指名道姓给某个形参传值,可以完全不参照顺序
def func(x,y):
print(x,y)
func(y=2,x=1) # 关键字参数
func(1,2) # 位置参数
3,混合使用,强调
# 1、位置实参必须放在关键字实参前
def func(x,y):
print(x,y)
func(1,y=2)
func(y=2,1)
# 2、不能能为同一个形参重复传值
def func(x,y):
print(x,y)
func(1,y=2,x=3)
func(1,2,x=3,y=4)3.2 默认参数------位置参数与默认参数混用
4,默认参数
# 默认形参:在定义函数阶段,就已经被赋值的形参,称之为默认参数
# 特点:在定义阶段就已经被赋值,意味着在调用阶段可以不用为其赋值
def func(x,y=3):
print(x,y)
func(x=1)
func(x=1,y=44444)
def register(name,age,gender='男'):
print(name,age,gender)
register('三炮',18)
register('二炮',19)
register('大炮',19)
register('没炮',19,'女')
5,位置形参与默认形参混用,强调:
# 1、位置形参必须在默认形参的左边
def func(y=2,x): # 错误写法
pass
# 2、默认参数的值是在函数定义阶段被赋值的,准确地说被赋予的是值的内存地址
# 示范1:
m=2
def func(x,y=m): # y=>2的内存地址
print(x,y)
m=3333333333333333333
func(1)
# 3、虽然默认值可以被指定为任意数据类型,但是不推荐使用可变类型
# 函数最理想的状态:函数的调用只跟函数本身有关系,不外界代码的影响
m = [111111, ]
def func(x, y=m):
print(x, y)
m.append(3333333)
m.append(444444)
m.append(5555)
func(1)
func(2)
func(3)
def func(x,y,z,l=None):
if l is None:
l=[]
l.append(x)
l.append(y)
l.append(z)
print(l)
func(1,2,3)
func(4,5,6)
new_l=[111,222]
func(1,2,3,new_l)3.3 可变长度的参数
6,可变长度的参数(*与**的用法)
# 可变长度指的是在调用函数时,传入的值(实参)的个数不固定
# 而实参是用来为形参赋值的,所以对应着,针对溢出的实参必须有对应的形参来接收
6.1 可变长度的位置参数
# I:*形参名:用来接收溢出的位置实参,溢出的位置实参会被*保存成元组的格式然后赋值紧跟其后的形参名
# *后跟的可以是任意名字,但是约定俗成应该是args
def func(x,y,*z): # z =(3,4,5,6)
print(x,y,z)
func(1,2,3,4,5,6)
def my_sum(*args):
res=0
for item in args:
res+=item
return res
res=my_sum(1,2,3,4,)
print(res)
# II: *可以用在实参中,实参中带*,先*后的值打散成位置实参
def func(x,y,z):
print(x,y,z)
func(*[11,22,33]) # func(11,22,33)
func(*[11,22]) # func(11,22)
l=[11,22,33]
func(*l)
# III: 形参与实参中都带*
def func(x,y,*args): # args=(3,4,5,6)
print(x,y,args)
func(1,2,[3,4,5,6])
func(1,2,*[3,4,5,6]) # func(1,2,3,4,5,6)
func(*'hello') # func('h','e','l','l','o')
6.2 可变长度的关键字参数
# I:**形参名:用来接收溢出的关键字实参,**会将溢出的关键字实参保存成字典格式,然后赋值给紧跟其后的形参名
# **后跟的可以是任意名字,但是约定俗成应该是kwargs
def func(x,y,**kwargs):
print(x,y,kwargs)
func(1,y=2,a=1,b=2,c=3)
# II: **可以用在实参中(**后跟的只能是字典),实参中带**,先**后的值打散成关键字实参
def func(x,y,z):
print(x,y,z)
func(*{'x':1,'y':2,'z':3}) # func('x','y','z')
func(**{'x':1,'y':2,'z':3}) # func(x=1,y=2,z=3)
# 错误
func(**{'x':1,'y':2,}) # func(x=1,y=2)
func(**{'x':1,'a':2,'z':3}) # func(x=1,a=2,z=3)
# III: 形参与实参中都带**
def func(x,y,**kwargs):
print(x,y,kwargs)
func(y=222,x=111,a=333,b=444)
func(**{'y':222,'x':111,'a':333,'b':4444})
# 混用*与**:*args必须在**kwargs之前
def func(x,*args,**kwargs):
print(args)
print(kwargs)
func(1,2,3,4,5,6,7,8,x=1,y=2,z=3)
def index(x,y,z):
print('index=>>> ',x,y,z)
def wrapper(*args,**kwargs): #args=(1,) kwargs={'z':3,'y':2}
index(*args,**kwargs)
# index(*(1,),**{'z':3,'y':2})
# index(1,z=3,y=2)
wrapper(1,z=3,y=2) # 为wrapper传递的参数是给index用的3.4 函数的类型提示
## : 后面是提示信息,可以随意写
def regidter(name:"不能写艾尼",age:"至少18岁"):
print(name)
print(age)
def register(name:str,age:int,hobbies:tuple)->int: # 返回值类型为 int
print(name)
print(age)
print(hobbies)
# 添加提示功能的同时,再添加默认值
def register(name:str = 'aini',age:int = 18 ,hobbies:tuple)->int: # 返回值类型为 int
print(name)
print(age)
print(hobbies)4,装饰器
4.1 装饰器的一步步实现
## 装饰器:装饰器定义一个函数,该函数是用来为其他函数添加额外的工能
## 装饰器就是不修改源代码以及调用方式的基础上增加新功能
## 开放封闭原则
# 开放:指的是对拓展工能是开放的
# 封闭: 指的是对修改源代码是封闭的
## 添加一个计算代码运行时间的工能(修改了源代码)
import time
def index(name,age):
start = time.time()
time.sleep(3)
print('我叫%s,今年%s岁'%(name,age))
end = time.time()
print(end - start)
index(age = 18,name = 'aini')
# --------------------------------------------------------------------------
def index1(name,age):
print('我叫%s,今年%s岁' % (name, age))
def wrapper():
start = time.time()
index1(name="aini", age=18)
time.sleep(3)
end = time.time()
print(end - start)
wrapper()
# 解决了修改原函数,但是也改变了函数调用方式
# --------------------------------------------------------------------------------------
def index1(name,age):
print('我叫%s,今年%s岁' % (name, age))
def wrapper(name,age):
start = time.time()
index1(name, age)
time.sleep(3)
end = time.time()
print(end - start)
wrapper('aini',18)
# -----------------------------------------------------------------------------------
def index1(name,age):
print('我叫%s,今年%s岁' % (name, age))
def wrapper(*args,**kwargs):
start = time.time()
index1(*args,**kwargs)
time.sleep(3)
end = time.time()
print(end - start)
wrapper('aini',age = 18)
# ------------------------------------------------------------------------------------
def index1(name,age):
print('我叫%s,今年%s岁' % (name, age))
def outer():
func = index
def wrapper(*args,**kwargs):
start = time.time()
fun(*args,**kwargs)
time.sleep(3)
end = time.time()
print(end - start)
return wrapper
f = outer() # f本质就是wrapper函数
### 继续改进
def index1(name,age):
print('我叫%s,今年%s岁' % (name, age))
def outer(fun):
def wrapper(*args,**kwargs):
start = time.time()
fun(*args,**kwargs)
time.sleep(3)
end = time.time()
print(end - start)
return wrapper
f = outer(index1) # f本质就是wrapper函数
f(name='aini',age=22)
# 继续改进,偷梁换柱
def index1(name,age):
print('我叫%s,今年%s岁' % (name, age))
def outer(fun):
def wrapper(*args,**kwargs):
start = time.time()
fun(*args,**kwargs)
time.sleep(3)
end = time.time()
print(end - start)
return wrapper
index1 = outer(index1) # f本质就是wrapper函数
index1(name='aini',age=22) # 新功能加上了,也没有修改函数的调用方式
# ---------------------------------------------------------4.2 装饰器最终版本
# 被装饰函数有返回值
########### 装饰器最终版本
def index1(name,age):
print('我叫%s,今年%s岁' % (name, age))
return [name,age] # 有返回值
def outer(fun):
def wrapper(*args,**kwargs):
start = time.time()
arg = fun(*args,**kwargs)
time.sleep(3)
end = time.time()
print(end - start)
return arg # 返回index1 的返回值
return wrapper
index1 = outer(index1) # f本质就是wrapper函数
res = index1(name='aini',age=22) # 新功能加上了,也没有修改函数的调用方式,把原函数的返回值也拿到了
# --------------------------------------------------------------------------------------------------4.3 装饰器语法糖
def outer(fun):
def wrapper(*args,**kwargs):
start = time.time()
arg = fun(*args,**kwargs)
time.sleep(3)
end = time.time()
print(end - start)
return arg # 返回index1 的返回值
return wrapper
@outer
def index1(name,age):
print('我叫%s,今年%s岁' % (name, age))
return [name,age] # 有返回值
# -----------------------------------------------
# 与原函数伪装的更像一点
from functools import wraps # 用于把原函数的属性特征赋值给另一个函数
def outer(fun):
@wraps(fun) # 可以把fun函数的所有属性特征加到wrapper函数身上
def wrapper(*args,**kwargs):
# wrapper.__name__ = fun.__name__
# wrapper.__doc__ = fun.__doc__
# 手动赋值麻烦
start = time.time()
arg = fun(*args,**kwargs)
time.sleep(3)
end = time.time()
print(end - start)
return arg # 返回index1 的返回值
return wrapper
@outer
def index1(name,age):
'''我是index1''' # 通过help(index)函数来查看 文档信息,可以通过index.__doc__ = 'xxxxx' 来给某个函数赋值文档信息
# 通过 index__name__ 可以获得函数的名字,也可以对其进行赋值
print('我叫%s,今年%s岁' % (name, age))
return [name,age] # 有返回值4.4 有参装饰器
4.4.1 不用语法糖
### 不用语法糖
def auth(func,db_type):
def wrapper(*args,**kwargs):
name = input('your name:').strip()
pwd = input('your password:').strip()
if db_type == 'file':
print('基于文件验证')
if name == 'aini' and pwd == 'aini123':
print('login success')
res = func(*args,**kwargs)
return res
else:
print('用户名或者密码错误!!')
elif db_type == 'mysql':
print('基于mysql验证')
elif db_type == 'ldap':
print('基于ldap验证')
else:
print('基于其他途径验证')
return wrapper
def index(x,y):
print('index->>%s:%s'%(x,y))
index = auth(index,'file')
index('aini',22)4.4.2 语法糖01
#---------------------------------------------------------------------
# 语法糖01
def auth(db_type = "file"):
def deco(func):
def wrapper(*args,**kwargs):
name = input('your name:').strip()
pwd = input('your password:').strip()
if db_type == 'file':
print('基于文件验证')
if name == 'aini' and pwd == 'aini123':
print('login success')
res = func(*args,**kwargs)
return res
else:
print('用户名或者密码错误!!')
elif db_type == 'mysql':
print('基于mysql验证')
elif db_type == 'ldap':
print('基于ldap验证')
else:
print('基于其他途径验证')
return wrapper
return deco
deco = auth(db_type = 'file')
@deco
def index(x,y):
print('index->>%s:%s'%(x,y))
index('aini',22)
deco = auth(db_type = 'mysql')
@deco
def index(x,y):
print('index->>%s:%s'%(x,y))
index('aini',22)4.4.3 标准语法糖
# ---------------------------------------------------------------------------------
# 标准语法糖模板
def auth(外界传递的参数):
def deco(func):
def wrapper(*args,**kwargs):
'''自己扩展的功能'''
res = func(*args,**kwargs)
return res
return wrapper
return deco
@auth(外界传递的参数)
def index(x,y):
print(x,y)
return(x,y)
# 标准语法糖02(例子)
def auth(db_type = "file"):
def deco(func):
def wrapper(*args,**kwargs):
name = input('your name:').strip()
pwd = input('your password:').strip()
if db_type == 'file':
print('基于文件验证')
if name == 'aini' and pwd == 'aini123':
print('login success')
res = func(*args,**kwargs)
return res
else:
print('用户名或者密码错误!!')
elif db_type == 'mysql':
print('基于mysql验证')
elif db_type == 'ldap':
print('基于ldap验证')
else:
print('基于其他途径验证')
return wrapper
return deco
@auth(db_type = 'file')
def index(x,y):
print('index->>%s:%s'%(x,y))
index('aini',22)
@auth(db_type = 'file')
def index(x,y):
print('index->>%s:%s'%(x,y))
index('aini',22)5, 迭代器
5.1 基础知识
1,迭代器:迭代取值的工具,迭代是重复的过程,每一次重复都是基于上次的结果而继续的,单纯的重复不是迭代
# 可迭代对象: 但凡内置有__iter__()方法的都称之为可迭代对象
# 字符串---列表---元祖---字典---集合---文件操作 都是可迭代对象
# 调用可迭代对象下的__iter__方法将其转换为可迭代对象
d = {'a':1, 'b':2, 'c':3}
d_iter = d.__iter__() # 把字典d转换成了可迭代对象
# d_iter.__next__() # 通过__next__()方法可以取值
print(d_iter.__next__()) # a
print(d_iter.__next__()) # b
print(d_iter.__next__()) # c
# 没值了以后就会报错, 抛出异常StopIteration
#-----------------------------------------------
d = {'a':1, 'b':2, 'c':3}
d_iter = d.__iter__()
while True:
try:
print(d_iter.__next__())
except StopIteration:
break
# 对同一个迭代器对象,取值取干净的情况下第二次取值的时候去不了,没值,只能造新的迭代器5.2 迭代器与for循环工作原理
#可迭代对象与迭代器详解
#可迭代对象:内置有__iter__() 方法对象
# 可迭代对象.__iter__(): 得到可迭代对象
#迭代器对象:内置有__next__() 方法
# 迭代器对象.__next__():得到迭代器的下一个值
# 迭代器对象.__iter__(): 得到的值迭代器对象的本身(调跟没调一个样)-----------> 为了保证for循环的工作
# for循环工作原理
d = {'a':1, 'b':2, 'c':3}
d_iter = d.__iter__()
# 1,d.__iter__() 方法得到一个跌倒器对象
# 2,迭代器对象的__next__()方法拿到返回值,将该返回值赋值给k
# 3,循环往复步骤2,直到抛出异常,for循环会捕捉异常并结束循坏
for k in d:
print(k)
# 可迭代器对象不一定是迭代器对象------------迭代器对象一定是可迭代对象
# 字符串---列表---元祖---字典---集合只是可迭代对象,不是迭代器对象、
# 文件操作时迭代器对象也是可迭代对象6,生成器(本质就是迭代器)
# 函数里包含yield,并且调用函数以后就能得到一个可迭代对象
def test():
print('第一次')
yield 1
print('第二次')
yield 2
print('第三次')
yield 3
print('第四次')
g = test()
print(g) # <generator object test at 0x0000014C809A27A0>
g_iter = g.__iter__()
res1 = g_iter.__next__() # 第一次
print(res1) # 1
res2 = g_iter.__next__() # 第二次
print(res2) # 2
res3 = g_iter.__next__() # 第三次
print(res3) # 3
# 补充
len(s) -------> s.__len__()
next(s) ------> s.__next__()
iter(d) -------> d.__iter__()1,yield 表达式
def person(name):
print("%s吃东西啦!!"%name)
while True:
x = yield None
print('%s吃东西啦---%s'%(name,x))
g = person('aini')
# next(g) =============== g.send(None)
next(g)
next(g)
# send()方法可以给yield传值
# 不能在第一次运行时用g.send()来传值,需要用g.send(None)或者next(g) 来初始化,第二次开始可以用g.send("值")来传值
g.send("雪糕") # aini吃东西啦---雪糕
g.send("西瓜") # aini吃东西啦---西瓜2, 三元表达式
x = 10
y = 20
res = x if x > y else y
# 格式
条件成立时返回的值 if 条件 else 条件不成立时返回的值3,列表生成式
l = ['aini_aaa','dilnur_aaa','donghua_aaa','egon']
res = [name for name in l if name.endswith('aaa')]
print(res)
# 语法: [结果 for 元素 in 可迭代对象 if 条件]
l = ['aini_aaa','dilnur_aaa','donghua_aaa','egon']
l = [name.upper() for name in l]
print(l)
l = ['aini_aaa','dilnur_aaa','donghua_aaa','egon']
l = [name.replace('_aaa','') for name in l if name.endswith('_aaa')]
print(l)4,其他生成器(——没有元祖生成式——)
### 字典生成器
keys = ['name','age','gender']
res = {key: None for key in keys}
print(res) # {'name': None, 'age': None, 'gender': None}
items = [('name','aini'),('age',22),('gender','man')]
res = {k:v for k,v in items}
print(res)
## 集合生成器
keys = ['name','age','gender']
set1 = {key for key in keys}
## 没有元祖生成器
g = (i for i in range(10) if i % 4 == 0 ) ## 得到的是一个迭代器
#### 统计文件字符个数
with open('aini.txt', mode='rt', encoding= 'utf-8') as f:
res = sum(len(line) for line in f)
print(res)5,二分法
l = [-10,-6,-3,0,1,10,56,134,222,234,532,642,743,852,1431]
def search_num(num,list):
mid_index = len(list) // 2
if len(list) == 0:
print("没找到")
return False
if num > list[mid_index]:
list = list[mid_index + 1 :]
search_num(num,list)
elif num < list[mid_index]:
list = list[:mid_index]
search_num(num, list)
else:
print('找到了' , list[mid_index])
search_num(743,l)6,匿名函数与lambdaj
## 定义
res = lambda x,y : x+y
## 调用
(lambda x,y : x+y)(10,20) # 第一种方法
res(10,20) ## 第二种方法
##应用场景
salary = {
'aini':20000,
'aili':50000,
'dilnur':15000,
'hahhaha':42568,
'fdafdaf':7854
}
res = max(salary ,key= lambda x : salary[x])
print(res)7,模块
## 内置模块
## 第三方模块
## 自定义模块
## 模块的四种形式
1, 使用Python编写的py文件
2, 已被编译为共享库或DLL的C或C++扩展
3, 把一系列模块组织到一起的文件夹(文件夹下面有个__init__.py 该文件夹称为包)
3, 使用C编写并链接到Python解释器的内置模块
import foo
## 首次导入模块会发生什么?
1,执行foo.py
2, 产生foo.py的命名空间
3,在当前文件中产生的有一个名字foo,改名字指向2中产生的命名空间
## 无论是调用还是修改与源模块为准,与调用位置无关
## 导入模块规范
1 Python内置模块
2,Python第三方模块
3,自定义模块
## 起别名
import foo as f
## 自定义模块命名应该纯小写+下划线
## 可以在函数内导入模块7.1 写模块时测试
# 每个Python文件内置了__name__,指向Python文件名
# 当foo.py 被运行时,
__name__ = "__main__"
# 当foo.py 被当做模块导入时,
__name__ != "__main__"
##### 测试时可以if判断,在foo.py文件中写以下判断
if __name__ == "__main__" :
## 你的测试代码7.2 from xxx import xxx
# from foo import x 发生什么事情
1, 产生一个模块的命名空间
2, 运行foo.py 产生,将运行过程中产生的名字都丢到命名空间去
3, 在当前命名空间拿到一个名字,改名字指向模块命名空间7.3 从一个模块导入所有
#不太推荐使用
form foo import *
# 被导入模块有个 __all__ = []
__all__ = [] # 存放导入模块里的所有变量和函数, 默认放所有的变量和函数,也可以手动修改
foo.py
__all__ = ['x','change']
x = 10
def change():
global x
x = 20
a = 20
b = 30
run.py
from foo import * ## * 导入的是foo.py里的 __all__ 列表里的变量和函数
print(x)
change()
print(a) # 会报错,因为foo.py 里的 __all__ 列表里没有a变量7.4 sys.path 模块搜索路径优先级
1, 内存(内置模块)
2, 从硬盘查找
import sys
# 值为一个列表,存放了一系列的文件夹
# 其中第一个文件夹是当前执行所在的文件夹
# 第二个文件夹当不存在,因为这不是解释器存放的,是pycharm添加的
print(sys.path)
# sys.path 里放的就是模块的存放路径查找顺序
[
'E:\\Desktop\\python全栈\\模块', 'E:\\Desktop\\python全栈', 'D:\\软件\\pycharm\\PyCharm 2021.3.1\\plugins\\python\\helpers\\pycharm_display', 'D:\\软件\\python\\python310.zip', 'D:\\软件\\python\\DLLs', 'D:\\软件\\python\\lib', 'D:\\软件\\python', 'C:\\Users\\艾尼-aini\\AppData\\Roaming\\Python\\Python310\\site-packages', 'D:\\软件\\python\\lib\\site-packages', 'D:\\软件\\python\\lib\\site-packages\\win32', 'D:\\软件\\python\\lib\\site-packages\\win32\\lib', 'D:\\软件\\python\\lib\\site-packages\\Pythonwin', 'D:\\软件\\pycharm\\PyCharm 2021.3.1\\plugins\\python\\helpers\\pycharm_matplotlib_backend'
]7.5 sys.modules 查看内存中的模块
import sys
print(sys.module) # 是一个字典,存放导入的模块
## 可以判断一个模块是否已经在内存中
print('foo' in sys.module)7.6 编写规范的模块
"this module is used to ......" # 第一行文档注释
import sys # 导入需要用到的包
x = 1 # 定义全局变量
class foo: # 定义类
pass
def test(): #定义函数
pass
if __name__ == "__main__":
pass8,包(包本身就是模块)
### 包就是一个包含__init__.py的文件夹,包的本质是模块的一种形式,包用来被当做模块导入
### 导入包运行时运行__inti__.py文件里的代码
### 环境变量是以执行文件为准备的,所有的被导入的模块或者说后续的其他的sys.path都是参照执行文件的sys.path9, 软件开发的目录规范
ATM --------------------------------- # 项目跟目录
bin
start.py ---------------------# 启动程序
config ------------------------- # 项目配置文件
setting.py
db ------------------------------- # 数据库相关的文件夹
db_handle.py
lib ------------------------------ # 共享库(包)
common.py
core ------------------------------# 核心代码逻辑
src.py
api -------------------------------# API有关的文件夹
api.py
log -------------------------------# 记录日志的文件夹
user.log
README --------------------------- # 对软件的解释说明
__file__ # 当前文件的绝对路径
# 在start.py中运行 print(__file__) ---------------------- E:\Desktop\python全栈\ATM\bin\start.py
import os
import sys
BASE_DIR = os.path.dirname(os.path.dirname(__file__)) ## 这样可以动态拿到根目录
sys.path.append(BASE_DIR) # 把项目根目录加到环境变量了,这样可以很好的导包了
## 如果把运行文件 start.py 直接放在跟文件的目录下,就不需要处理环境变量了10,反射
10.1 什么是反射
## 反射---------------> 程序运行过程当中,动态的获取对象的信息。10.2 如何实现反射
# 通过dir:查看某一个对象可以.出来那些属性来
# 可以通过字符串反射到真正的属性上,得到熟悉值
## 四个内置函数的使用
hasattr() ## 判断属性是否存在
getattr() ## 得到属性
setattr() ## 设置属性
delattr() ## 删除属性
hasattr(obj,'name') ## 判断对象 obj 有没有 name 属性
getattr(obj,;'name',None) ## 得到对象 obj 的 name 属性,如果没有返回 None
setattr(obj,'name','aini') ## 设置对象 obj 的 name 属性为 "aini"
delattr(obj,'name') ## 删除对象 obj 的 name 属性五,面向对象编程
1,类的定义
## 类名驼峰命名
## 类体中可以写任意Python代码,类体代码在定义时就运行
## __dic__ 可以查看类的命名空间
'''
{'__module__': '__main__', 'school': 'donghua', 'adress': 'shanghai', 'local': <classmethod(<function Student.local at 0x000001BCF418E9E0>)>, 'say_hello': <staticmethod(<function Student.say_hello at 0x000001BCF418EA70>)>, '__init__': <function Student.__init__ at 0x000001BCF418EB00>, 'say_score': <function Student.say_score at 0x000001BCF418EB90>, '__dict__': <attribute '__dict__' of 'Student' objects>, '__weakref__': <attribute '__weakref__' of 'Student' objects>, '__doc__': None}
'''
class Student:
# 类属性
# 可以被所有的实例对象所共享
school = 'donghua'
adress = 'shanghai'
stu_count = 0 # 统计注册的实例个数
# 类方法
@classmethod
def local(cls):
print(cls.adress)
# 静态方法
# 可以调用类的属性和方法
@staticmethod
def say_hello(str):
print(str)
Student.local()
# 通过构造函数__init__创建对象的属性
def __init__(self,name,age,score):
self.name = name
self.age = age
self.score = score
Student.stu_count += 1
# 创建实例对象方法
def say_score(self):
print(f'{self.name}的分数是{self.score}')
print(Student.say_score) ## <function Student.say_score at 0x00000255F6DDEB90>
s1 = Student('aini',22,80) ## 实例化
Student.say_score(s1) ## aini的分数是80
s1.say_score() ----- ## 本质是 Student.say_score(s1)
## 通过类名可以调用实例方法,需要传递实例进去
## 实例化发生的三件事情
1,先产生一个空对象
2,Python会自动调用 __init__方法
3,返回初始化完的对象
print(s1.__dict__) ------ ## ## {'name': 'aini', 'age': 22, 'score': 80}2,封装
2.1 私有属性
## 在属性或方法前加__前缀,可以对外进行隐藏
## 这种隐藏对外不对内,因为__开头的属性会在类定义阶段检查语法时统一变形
class Foo:
__x = 1
def __test(self):
print('from test')
def f2(self):
print(self.__x) # 1
print(self.__test) ## <bound method Foo.__test of <__main__.Foo object at 0x000002063304B7F0>>
## 隐藏属性的访问
## Python不推荐此方法
print(Foo._Foo__x) ## 1
print(Foo._Foo__test) ## <function Foo.__test at 0x000001C42976E320>
## 这种变形操作只在检查类语法的时候发生一次,之后定义__定义的属性都不会变形
Foo.__y = 3
print(Foo.__y)2.2 property使用
## 第一种类型
## 把函数像普通属性一样调用
class Person:
def __init__(self,name):
self.__name = name
@property
def get_name(self):
return self.__name
aini = Person('aini')
print(aini.get_name) ## 'aini'
## 第二种类型
class Person:
def __init__(self,name):
self.__name = name
def get_name(self):
return self.__name
def set_name(self,val):
if type(val) is not str:
print('必须传入str类型')
return
self.__name = val
## 伪装成数据接口的属性
name = property(get_name,set_name)
aini = Person('aini')
print(aini.name) ## 'aini'
aini.name = 'norah'
print(aini.name) ## 'norah'
## 第三种方法
## 起一个一样的函数名,用不同功能的property装饰
class Person:
def __init__(self,name):
self.__name = name
@property ## name = property(name)
def name(self):
return self.__name
@name.setter
def name(self,val):
if type(val) is not str:
print('必须传入str类型')
return
self.__name = val
@ name.deleter
def name(self):
print("不能删除")3,继承
Python里支持多继承
python3里没有继承任何类的类都继承了Object类
Python2 里有经典类和新式类
经典类:没有继承Object ------------------ 新式类:继承了Object
class Parent1:
pass
class Parent2:
pass
class Sub1(Parent1): ## 单继承
pass
class Sub2(Parent1,Parent2): ## 多继承
pass
print(Sub1.__bases__) ## (<class '__main__.Parent1'>,)
print(Sub2.__bases__) ## (<class '__main__.Parent1'>, <class '__main__.Parent2'>)3.1 继承的实现
class OldBoyPeople:
school = 'OLDBOY'
def __init__(self, name, age, sex):
self.name = name
self.age = age
self.sex = sex
class Student(OldBoyPeople):
def choose_course(self):
print(f'学生 {self.name}正在选课')
class Teacher(OldBoyPeople):
def __init__(self,name,age,sex,salary,level):
# 调父类的属性就行
OldBoyPeople.__init__(self,name,age,sex)
self.salary = salary
self.level = level
def score(self):
print('老师 %s 正在给学生打分' %self.name)
t = Teacher('agen',25,'man',50000,'一级')
print(t.__dict__) ## {'name': 'agen', 'age': 25, 'sex': 'man', 'salary': 50000, 'level': '一级'}
stu_1 = Student('aini',22,'man')
print(stu_1.name,stu_1.age,stu_1.sex) ## aini 22 man
print(stu_1.school) ## OLDBOY
stu_1.choose_course() ## 学生 aini正在选课3.2 单继承背景下的属性查找
class Foo:
def f1(self):
print('Foo.f1')
def f2(self):
print('Foo.f2')
self.f1() ## z这里如何调用自己的f1函数
# 第一种方法 Foo.f1(self)
# 第二种方法,把f1函数改为次有属性 self.__f1()
class Bar(Foo):
def f1(self):
print('Bar.f1')
obj = Bar()
obj.f2() ## 到父类调f2,也会把自己传进来,随意 self.f1() == obj.f1()
## Foo.f2
## Bar.f13.3 菱形问题
'''
大多数面向对象语言都不支持多继承,而在Python中,一个子类是可以同时继承多个父类的,这固然可以带来一个子类可以对多个不同父类加以重用的好处,但也有可能引发著名的 Diamond problem菱形问题(或称钻石问题,有时候也被称为“死亡钻石”),菱形其实就是对下面这种继承结构的形象比喻
'''
class A(object):
def test(self):
print('from A')
class B(A):
def test(self):
print('from B')
class C(A):
def test(self):
print('from C')
class D(B,C):
pass
obj = D()
obj.test() # 结果为:from B3.4 继承原理
## python2 和 Python3 里算出来的mro不一样的
## python到底是如何实现继承的呢? 对于你定义的每一个类,Python都会计算出一个方法解析顺序(MRO)列表,该MRO列表就是一个简单的所有基类的线性顺序列表,如下
D.mro()
## [<class '__main__.D'>, <class '__main__.B'>, <class '__main__.C'>, <class '__main__.A'>, <class 'object'>]
B.mro()
## [<class '__main__.B'>, <class '__main__.A'>, <class 'object'>]
## 1.子类会先于父类被检查
## 2.多个父类会根据它们在列表中的顺序被检查
## 3.如果对下一个类存在两个合法的选择,选择第一个父类3.5 深度优先和广度优先
## 参照下述代码,多继承结构为非菱形结构,此时,会按照先找B这一条分支,然后再找C这一条分支,最后找D这一条分支的顺序直到找到我们想要的属性
class E:
def test(self):
print('from E')
class F:
def test(self):
print('from F')
class B(E):
def test(self):
print('from B')
class C(F):
def test(self):
print('from C')
class D:
def test(self):
print('from D')
class A(B, C, D):
# def test(self):
# print('from A')
pass
print(A.mro())
'''
[<class '__main__.A'>, <class '__main__.B'>, <class '__main__.E'>, <class '__main__.C'>, <class '__main__.F'>, <class '__main__.D'>, <class 'object'>]
'''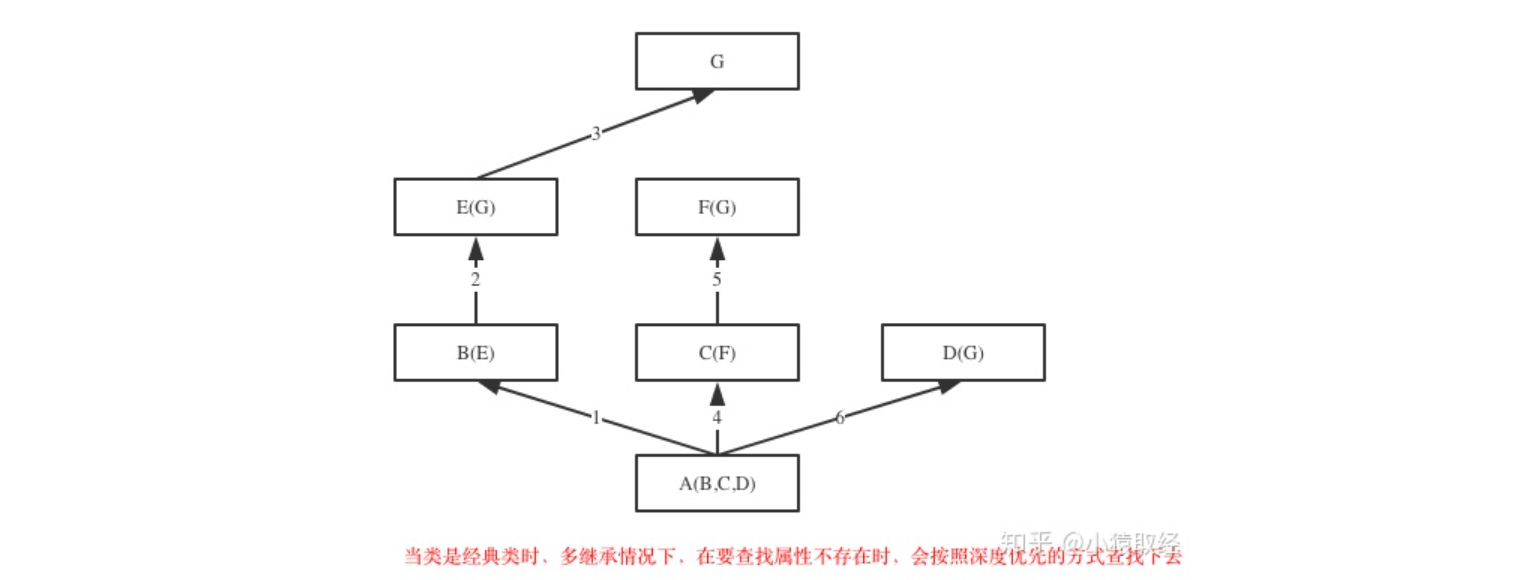
## 如果继承关系为菱形结构,那么经典类与新式类会有不同MRO,分别对应属性的两种查找方式:深度优先和广度优先
#################### 这是经典类:深度优先查找
class G: # 在python2中,未继承object的类及其子类,都是经典类
def test(self):
print('from G')
class E(G):
def test(self):
print('from E')
class F(G):
def test(self):
print('from F')
class B(E):
def test(self):
print('from B')
class C(F):
def test(self):
print('from C')
class D(G):
def test(self):
print('from D')
class A(B,C,D):
# def test(self):
# print('from A')
pass
obj = A()
obj.test() # 如上图,查找顺序为:obj->A->B->E->G->C->F->D->object
# 可依次注释上述类中的方法test来进行验证,注意请在python2.x中进行测试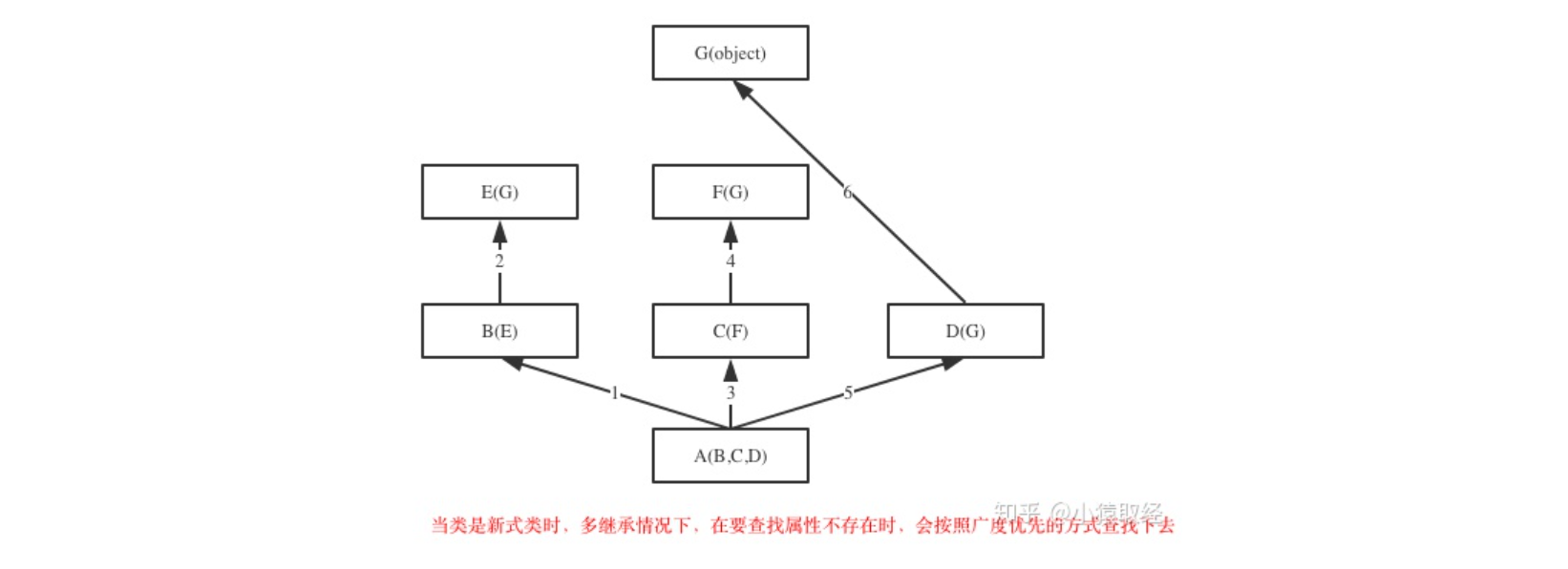
#################### 这是新式类:广度优先查找
class G(object):
def test(self):
print('from G')
class E(G):
def test(self):
print('from E')
class F(G):
def test(self):
print('from F')
class B(E):
def test(self):
print('from B')
class C(F):
def test(self):
print('from C')
class D(G):
def test(self):
print('from D')
class A(B,C,D):
# def test(self):
# print('from A')
pass
obj = A()
obj.test() # 如上图,查找顺序为:obj->A->B->E->C->F->D->G->object
# 可依次注释上述类中的方法test来进行验证3.6 Mixins机制(解决多继承问题)
## Mixins机制核心:多继承背景下,尽可能地提升多继承的可读性
## 让多继承满足人类的思维习惯
## 民航飞机、直升飞机、轿车都是一个(is-a)交通工具,前两者都有一个功能是飞行fly,但是轿车没有,所以如下所示我们把飞行功能放到交通工具这个父类中是不合理的
class Vehicle: # 交通工具
def fly(self):
'''
飞行功能相应的代码
'''
print("I am flying")
class CivilAircraft(Vehicle): # 民航飞机
pass
class Helicopter(Vehicle): # 直升飞机
pass
class Car(Vehicle): # 汽车并不会飞,但按照上述继承关系,汽车也能飞了
pass
## -------------------------------------------------------------------------------------------------------------
## 解决方法
class Vehicle: # 交通工具
pass
class FlyableMixin:
def fly(self):
'''
飞行功能相应的代码
'''
print("I am flying")
class CivilAircraft(FlyableMixin, Vehicle): # 民航飞机
pass
class Helicopter(FlyableMixin, Vehicle): # 直升飞机
pass
class Car(Vehicle): # 汽车
pass
# ps: 采用某种规范(如命名规范)来解决具体的问题是python惯用的套路
## -------------------------------------------------------------------------------------------------------------
## 使用Minin
class Vehicle: # 交通工具
pass
class FlyableMixin:
def fly(self):
'''
飞行功能相应的代码
'''
print("I am flying")
class CivilAircraft(FlyableMixin, Vehicle): # 民航飞机
pass
class Helicopter(FlyableMixin, Vehicle): # 直升飞机
pass
class Car(Vehicle): # 汽车
pass
# ps: 采用某种规范(如命名规范)来解决具体的问题是python惯用的套路
## --------------------------------------------------------------------------------------------------------3.7 使用minin注意事项
## 使用Mixin类实现多重继承要非常小心
## 首先它必须表示某一种功能,而不是某个物品,python 对于mixin类的命名方式一般以 Mixin, able, ible 为后缀
## 其次它必须责任单一,如果有多个功能,那就写多个Mixin类,一个类可以继承多个Mixin,为了保证遵循继承的“is-a”原则,只能继承一个 标识其归属含义的父类
## 然后,它不依赖于子类的实现
## 最后,子类即便没有继承这个Mixin类,也照样可以工作,就是缺少了某个功能。(比如飞机照样可以载客,就是不能飞了)3.8 派生与方法重用
# 子类可以派生出自己新的属性,在进行属性查找时,子类中的属性名会优先于父类被查找,例如每个老师还有职称这一属性,我们就需要在Teacher类中定义该类自己的__init__覆盖父类的
class OldBoyPeople:
def __init__(self,name,age,sex):
self.name = name
self.age = age
self.sex = sex
def f1(self):
print('%s say hello' %self.name)
class Teacher(OldBoyPeople):
def __int__(self,name,age,sex,level,salary):
## 第一种方法(不依赖于继承)
## OldBoyPeople.__init__(self,name,age,sex)
## 第二种方法(严格依赖继承,只能用于新式类)
## Python2中需要传入类和本身
## super(Teacher, self).__init__(name.age, sex)
## Python3中什么也不需要传
super().__init__(name,age,sex)
## super 根据当前类的mro去访问父类里面去找
self.level = level
self.salary = salary
## super 严格遵守 mor 去找父类,而不是我们肉眼看到的
#A没有继承B
class A:
def test(self):
super().test()
class B:
def test(self):
print('from B')
class C(A,B):
pass
C.mro() # 在代码层面A并不是B的子类,但从MRO列表来看,属性查找时,就是按照顺序C->A->B->object,B就相当于A的“父类”
## [<class '__main__.C'>, <class '__main__.A'>, <class '__main__.B'>,<class ‘object'>]
obj=C()
obj.test() # 属性查找的发起者是类C的对象obj,所以中途发生的属性查找都是参照C.mro()
## from B3.9 组合
'''
在一个类中以另外一个类的对象作为数据属性,称为类的组合。组合与继承都是用来解决代码的重用性问题。不同的是:继承是一种“是”的关系,比如老师是人、学生是人,当类之间有很多相同的之处,应该使用继承;而组合则是一种“有”的关系,比如老师有生日,老师有多门课程,当类之间有显著不同,并且较小的类是较大的类所需要的组件时,应该使用组合,如下示例
'''
class Course:
def __init__(self,name,period,price):
self.name=name
self.period=period
self.price=price
def tell_info(self):
print('<%s %s %s>' %(self.name,self.period,self.price))
class Date:
def __init__(self,year,mon,day):
self.year=year
self.mon=mon
self.day=day
def tell_birth(self):
print('<%s-%s-%s>' %(self.year,self.mon,self.day))
class People:
school='清华大学'
def __init__(self,name,sex,age):
self.name=name
self.sex=sex
self.age=age
#Teacher类基于继承来重用People的代码,基于组合来重用Date类和Course类的代码
class Teacher(People): #老师是人
def __init__(self,name,sex,age,title,year,mon,day):
super().__init__(name,age,sex)
self.birth=Date(year,mon,day) #老师有生日
self.courses=[] #老师有课程,可以在实例化后,往该列表中添加Course类的对象
def teach(self):
print('%s is teaching' %self.name)
python=Course('python','3mons',3000.0)
linux=Course('linux','5mons',5000.0)
teacher1=Teacher('lili','female',28,'博士生导师',1990,3,23)
# teacher1有两门课程
teacher1.courses.append(python)
teacher1.courses.append(linux)
# 重用Date类的功能
teacher1.birth.tell_birth()
# 重用Course类的功能
for obj in teacher1.courses:
obj.tell_info()4,多态
4.1 多态的一种方式
## 多态:同一种事务的多种状态
## 多态性指的是可以在不考虑对象具体类型的情况下而直接使用对象
class Animal:
def say(self):
print('动物基本的发声')
class Person(Animal):
def say(self):
super().say()
print('啊啊啊啊啊啊啊啊')
class Dog(Animal):
def say(self):
super().say()
print('汪汪汪')
class Pig(Animal):
def say(self):
super().say()
print('哼哼哼')
person = Person()
dog = Dog()
pig = Pig()
## 定义统一的接口,实现多态
def animal_say(animal):
animal.say()
animal_say(person)
animal_say(dog)
animal_say(pig)
## 多态的例子
def my_len(val):
return val.__len__()
my_len('aini')
my_len([1,12,3,4,5,'hhh'])
my_len({'name':'aini','age':22})4.2 Python推崇的多态
## 鸭子类型,不用继承
class Cpu:
def read(self):
print('cpu read')
def write(self):
print('cpu write')
class Meu:
def read(self):
print('meu read')
def write(self):
print('meu write')
class Txt:
def read(self):
print('txt read')
def write(self):
print('txt write')
cpu = Cpu()
meu = Meu()
txt = Txt()5,classmethod
import setting
class Mysql:
def __init__(self,ip,port):
self.ip = ip
self.port = port
def func(self):
print('%s %s' %(self.ip,self.port))
@classmethod ## 提供一种初始化对象的方法
def from_conf(cls):
return cls(setting.IP,setting.PORT) ## 返回的就是一个实例化的对象,不需要我自己一个个创建
obj = Mysql.from_conf()
print(obj.__dict__) ## {'ip': '127.0.0.1', 'port': 3306}6,staticmethod
class Mysql:
def __init__(self,ip,port):
self.ip = ip
self.port = port
@staticmethod
def create_id():
import uuid
return uuid.uuid4()
obj = Mysql('127.0.0.1','3306')
## 像普通函数一样调用就可以,不会自动传参,需要人工传参
print(Mysql.create_id()) ## 57c42038-b169-4f25-9057-d83795d097cc
print(obj.create_id()) ## 485372bc-efca-4da8-a446-b11c7bbf3c9b7,内置方法
7.1 什么是内置方法
## 定义在类内部,以__开头和__结尾的方法称之为内置方法
## 会在满足某种情况下回自动触发执行
## 为什么用: 为了定制化我们的类或者对象7.2 如何使用内置方法
# __str__
# __del__
class People:
def __init__(self,name,age):
self.name = name
self.age = age
def say(self):
print('<%s:%s>'%(self.name,self.age))
obj = People('aini',22)
print(obj) ## <__main__.People object at 0x00000276F6B8B730>
## ----------------------------------------------------------------------
## __str__ 来完成定制化操作
class People:
def __init__(self,name,age):
self.name = name
self.age = age
def say(self):
print('<%s:%s>'%(self.name,self.age))
def __str__(self):
print('这是xxxxx对象') ## 值起到提示作用
return '<%s:%s>' % (self.name, self.age) ## 必须要有return,而且返回字符串
obj = People('aini',22)
print(obj) ## <aini:22>
## ----------------------------------------------------------------------------------------
# __del__ :在清理对象时触发,会先执行该方法
class People:
def __init__(self,name,age):
self.name = name
self.age = age
def say(self):
print('<%s:%s>'%(self.name,self.age))
def __del__(self):
print('running......')
obj = People('aini',22)
print('=======================')
'''
== == == == == == == == == == == = ## 程序运行完了,要清理对象
running...... ## 清理对象时云运行
'''
## ---------------------------------------------------------------------------------------
class People:
def __init__(self,name,age):
self.name = name
self.age = age
def say(self):
print('<%s:%s>'%(self.name,self.age))
def __del__(self):
print('running......')
obj = People('aini',22)
del obj
print('=======================')
'''
running...... ## 清理对象时云运行
== == == == == == == == == == == = ## 程序运行完了
'''
## ---------------------------------------------------------------------------------------------
##### 对象本身占得是应用程序的内存空间,所以没有多大用处
##### 但是如果对象某个属性x 比如 obj.x 占得是操作系统内存空间,对象运行完了以后Python回收的是程序中的内存空间
### 操作系统不会被回收
class People:
def __init__(self,name,age):
self.name = name
self.age = age
self.x = open('aini.txt','w',encoding="utf-8")
def say(self):
print('<%s:%s>'%(self.name,self.age))
def __del__(self):
print('running......')
## 发起系统调用,告诉系统回收操作系统资源,比如如下:
self.x.close()
obj = People('aini',22)
print('=======================')8,元类介绍
## 元类----------------> 用来实例化产生类的那个类
## 关系 : 元类---------------实例化 --------------->类----------------------> 对象
class People:
def __init__(self, name, age):
self.name = name
self.age = age
def say(self):
print('<%s:%s>' % (self.name, self.age))
## 查看内置元类
print(type(People)) # <class 'type'>
print(type(int)) # <class 'type'>
## class关键字定义的类和内置的类都是由type产生的8.1 class关键字创建类的步骤
# 类三大特征:类名 class_name || 类的基类 clas_bases = (Object) || 类体本身 --> 一对字符串(执行类体代码,拿到运行空间)
class People:
def __init__(self, name, age):
self.name = name
self.age = age
def say(self):
print('<%s:%s>' % (self.name, self.age))
class_body = '''
def __init__(self, name, age):
self.name = name
self.age = age
def say(self):
print('<%s:%s>' % (self.name, self.age))
'''
class_dic = {} # 定义类的命名空间
# 类名
class_name = "People"
# 类的基类
clas_bases = (object,)
# 执行类体代码,拿到运行空间
exec(class_body,{},class_dic) # 空字典指的是全局命名空间 class_dic是类的命名空间
## 运行拿到exec以后可以拿到类体代码的运行空间,放在class_dic 里
print(class_dic)
## {'__init__': <function __init__ at 0x0000016A0BDC9900>, 'say': <function say at 0x0000016A0BE2E320>}
# 调用元类
People = type(class_name,class_basis,class_dic)
print(People) ## <class '__main__.People'>8.2 定制元类,控制类的产生
## 定制元类
class Mymeta(type): ## 只有继承了type类的类才可以称之为元
## 运行__init__方法的时候,空对象和这些class_name,class_basis,class_dic一共四个参数一起传进来了
## 所以需要四个参数接受
## 重写了造对象的方法,不写__new__方法的话自动创建空对象
## 参数为: 类本身,调用类时所传入的参数
def __new__(xls,*args,**kwargs):
##第一种方法 ----------------> 调父类的__new__()方法造对象
return super().__new__(cls,*args,**kwargs)
## 第二种方法 -----------------> 调用元类的内置方法
return type.__new__(cls,*args,**kwargs)
## 可以控制类的产生
def __init__(self,class_name,class_basis,class_dic):
## 类的首字母大写
if not x.capitalize():
raise NameError('类名的首字母必须大写啊!!!!')
class People(object ,metaclass = Mymeta):
# class产生类的话会自动继承object
# 底层的话需要明确之指定继承object类
def __init__(self, name, age):
self.name = name
self.age = age
def say(self):
print('<%s:%s>' % (self.name, self.age))
class_body = '''
def __init__(self, name, age):
self.name = name
self.age = age
def say(self):
print('<%s:%s>' % (self.name, self.age))
'''
class_dic = {} # 定义类的命名空间
# 类名
class_name = "People"
# 类的基类
clas_bases = (object,)
# 执行类体代码,拿到运行空间
exec(class_body,{},class_dic)
# 调用元类
People = Mymeta(class_name,class_basis,class_dic) ## 调用 type.__call__(方法)
## 将参数先传给 __new__方法,造空对象
## 然后参数传递给 __init__方法初始化类
## 调用Mymeta发生的事儿,调用Mymeta 就是type.__call__()
# 先造一个空对象 ==> People 调用__new__方法
# 调用Mymeta这个类的__inti__方法,完成初始化对象的操作(这个过程中可以控制类的产生)
# 返回初始化好的对象
## 总结
# 控制造空对象过程 重写 __new__()方法
# 控制类的产生 重写 __init__()方法8.3 new(方法)
## 具体看 8.2 控制造空对象的过程
## __new__() 放下造对象时,早于 __init__() 方法运行8.4 call(方法)
## 8.1 中
# 调用元类时
People = Mymeta(class_name,class_basis,class_dic) ## 本质就是调用 type的__call__()方法
class Foo:
def __init__(self,x,y):
self.x = x
self.y = y
def __call__(self,name,age):
print(name,age)
print('我运行了obj下面的__call__方法')
obj = Foo(111,222)
obj("aini",'22')
# 'aini' 22
# '我运行了obj下面的__call__方法'
## 对象的类里定义__call__方法的话,实例对象可以调用
### -------------------------------------------------------------------
## 如果想要控制类的调用, 那就重写__call__()方法
## 定制元类
class Mymeta(type):
def __call__(self,*args,**kwargs):
## Mymeta.__call__函数内会调用People.__new__()方法
people_obj = self__new__(self)
## 可以对类进行定制化
obj.__dict__['xxxx'] ='所有的obj产生的类我新加了一个属性'
## Mymeta.__call__函数内调用People.__inti__()方法
self.__init__(people_obj,*args,**kwargs)
## 重写了造对象的方法,不写__new__方法的话自动创建空对象
## 参数为: 类本身,调用类时所传入的参数
def __new__(xls,*args,**kwargs):
##第一种方法 ----------------> 调父类的__new__()方法造对象
return super().__new__(cls,*args,**kwargs)
## 第二种方法 -----------------> 调用元类的内置方法
return type.__new__(cls,*args,**kwargs)
## 可以控制类的产生
def __init__(self,class_name,class_basis,class_dic):
## 类的首字母大写
if not x.capitalize():
raise NameError('类名的首字母必须大写啊!!!!')
class People(object ,metaclass = Mymeta):
# class产生类的话会自动继承object
# 底层的话需要明确之指定继承object类
def __init__(self, name, age):
self.name = name
self.age = age
def __new__(cls,*args,**kwargs):
# 造对象
return object.__new__(cls,*args,**kwargs)
def say(self):
print('<%s:%s>' % (self.name, self.age))
## ------------------------------------------------------------
class_body = '''
def __init__(self, name, age):
self.name = name
self.age = age
def say(self):
print('<%s:%s>' % (self.name, self.age))
'''
class_dic = {} # 定义类的命名空间
class_name = "People"
clas_bases = (object,)
exec(class_body,{},class_dic)
People = Mymeta(class_name,class_basis,class_dic) ## 调用 type.__call__(方法)
## 调用Mymeta发生的事儿,调用Mymeta 就是type.__call__()
# 先造一个空对象 ==> People 调用__new__方法
# 调用Mymeta这个类的__inti__方法,完成初始化对象的操作(这个过程中可以控制类的产生)
# 返回初始化好的对象
obj = People('aini',22)
# 实例化People发生的三件事
# 调用Mymeta.__call__(self,*args,**kwargs)方法
# Mymeta.__call__函数内会调用People.__new__()方法
# Mymeta.__call__函数内调用People.__inti__()方法8.5 属性查找的原则
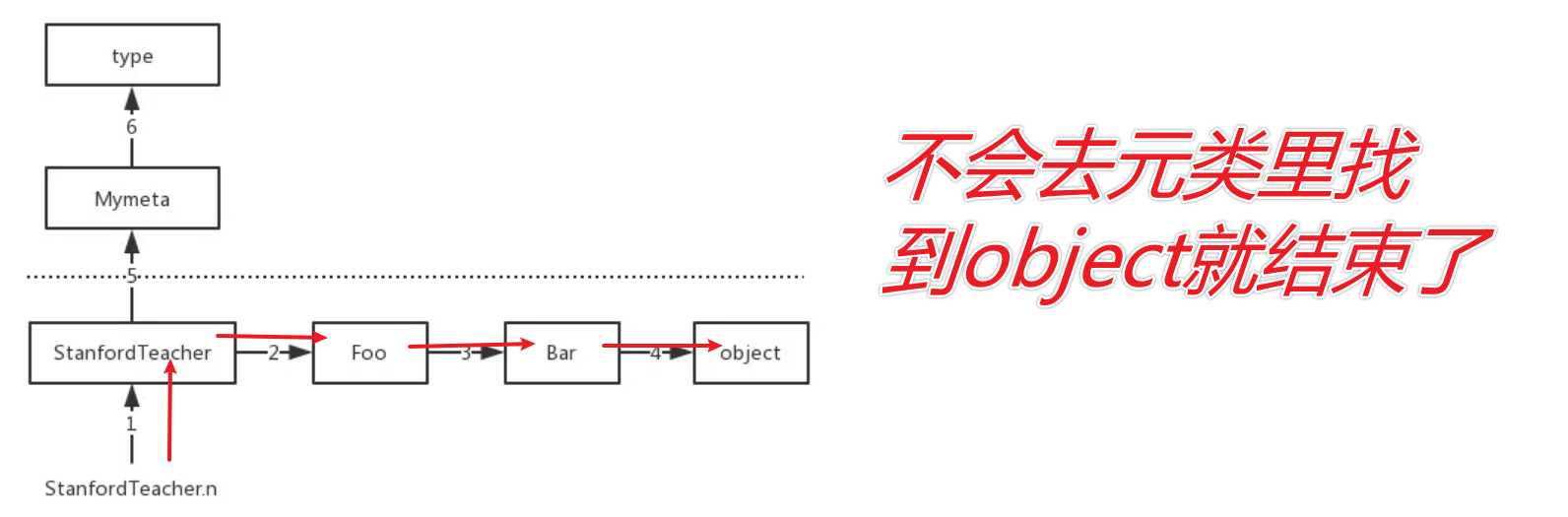
## 属性查找的原则:对象 ----> 类 ----------->父类
## 切记:父类不是元类,不会去从元类里找